Boîte à outils 1
Au début de ce projet, on nous a mis à disposition un corpus contenant les fils RSS du journal Le Monde, extraits tous les jours à 19h pendant l'année 2021.
Ce corpus se compose de fichiers XML contenant pour chaque article publié son titre et sa description. L'objectif de la BAO1 est de récupérer le contenu textuel de ces fichiers afin
de produire un fichier TXT et un fichier XML.
Le corpus est structuré par mois, par jour de publication mais aussi par rubrique. Or nous voulons travailler sur ces rubriques indépendamment.
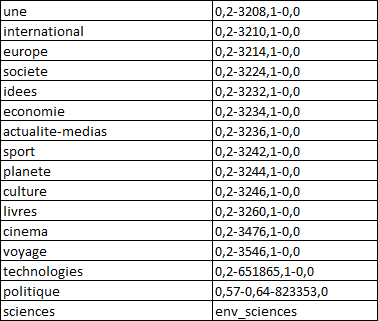
Notre script doit donc traiter les articles d'une seule rubrique, qui est précisée en argument. Voici les codes correspondant aux rubriques:
Script Perl commenté
#/usr/bin/perl
#-----------------------------------------------------------
use utf8;
use strict;
binmode(STDOUT, ":encoding(UTF-8)");
#-----------------------------------------------------------
# Ce programme s'utilise ainsi :
# perl parcours-arborescence.pl 2021 3208
# Il prend en arguments 2 éléments : (1) le nom de l'arborescence 2021
# contenant les fils RSS de l'année 2021, (2) le nom de la rubrique à traiter
# ici 3208 pour A la une
#-----------------------------------------------------------
if ($#ARGV != 1) {print "Il manque un argument à votre programme....\n";exit;}
my $rep="$ARGV[0]";
my $RUBRIQUE="$ARGV[1]";
# on s'assure que le nom du répertoire ne se termine pas par un "/"
$rep=~ s/[\/]$//;
open my $output, ">:encoding(UTF-8)","corpus-titre-description-${RUBRIQUE}.txt";
open my $output2, ">:encoding(UTF-8)","corpus-titre-description-${RUBRIQUE}.xml";
print $output2 "<?xml version=\"1.0\" encoding=\"utf-8\"?>\n<corpus>\n";
#----------------------------------------
&parcoursarborescencefichiers($rep); #recurse!
#----------------------------------------
print $output2 "</corpus>\n";
close $output;
close $output2;
#----------------------------------------------
exit;
#----------------------------------------------
sub parcoursarborescencefichiers {
my $path = shift(@_);
opendir(DIR, $path) or die "can't open $path: $!\n";
my @files = readdir(DIR);
closedir(DIR);
foreach my $file (sort @files) {
next if $file =~ /^\.\.?$/;
$file = $path."/".$file;
if (-d $file) {
print "On entre dans le REPERTOIRE : $file \n";
&parcoursarborescencefichiers($file); #recurse!
print "On sort du REPERTOIRE : $file \n";
}
if (-f $file) {
if ($file =~ /$RUBRIQUE.+\.xml$/) {
print "Traitement du fichier $file \n";
open my $input, "<:encoding(UTF-8)",$file;
$/=undef; # par défaut cette variable contient \n
my $ligne=<$input> ;
close($input);
while ($ligne=~/<item><title>(.+?)<\/title>.+?<description>(.+?)<\/description>/gs) {
my $titre=&nettoyage($1);
my $description=&nettoyage($2);
print $output "$titre \n";
print $output "$description \n";
print $output "----------------------------\n";
print $output2 "<item><titre>$titre</titre><description>$description</description></item>\n";
}
}
}
}
}
#----------------------------------------------
sub nettoyage {
my $texte=shift @_;
$texte=~s/(^<!\[CDATA\[)|(\]\]>$)//g;
$texte.=".";
$texte=~s/\.+$/\./;
return $texte;
}
#----------------------------------------------
Pour télécharger le script Perl : Script Perl
Script Python commenté
#-----------------------------------------------------------
# Pour lancer le programme:
# python3 bao1.py chemin_du_corpus numero_rubrique
#-----------------------------------------------------------
import sys
from pathlib import Path
import re
#on crée une fonction de nettoyage identique à celle du script Perl
def nettoyage(texte):
texte_net = re.sub("<!\[CDATA\[(.*?)\]\]>", "\\1", texte)
#on ajoute un point à la fin de chaque titre ou description pour faciliter l'étiquetage
texte_net += "."
#s'il y a plusieurs points, on en laisse un seul
texte_net = re.sub("\.+$",".",texte_net)
return texte_net
#on définit l'expression régulière qui va nous servir à reconnaître les titres et les descriptions
regex_item = re.compile("<item><title>(.*?)<\/title>.*?<description>(.*?)<\/description>")
#on crée une fonction qui permet d'extraire le titre et la description pour un seul fichier
def extract_un_fil(fichier_rss, output_xml, output_txt, titres_uniques):
#on ouvre le fichier d'entrée
with open(fichier_rss, "r") as input_rss:
#on lit et on stocke le contenu du fichier d'entrée
lignes = input_rss.readlines()
texte = "".join(lignes)
#chaque fois qu'on trouve quelque chose qui correspond à notre expression régulière
for m in re.finditer(regex_item, texte):
#on récupère et on nettoie le titre
titre_net = nettoyage(m.group(1))
#idem pour la description
description_net = nettoyage(m.group(2))
#si le titre ne se trouve pas déjà dans les titres rencontrés
if titre_net not in titres_uniques:
#on écrit le titre et sa description dans les deux fichiers de sortie
titres_uniques.add(titre_net)
output_txt.write(titre_net)
output_txt.write("\n")
output_txt.write(description_net)
output_txt.write(f"\n----------------------------\n")
item_xml = f"<item><titre>{titre_net}</titre><description>{description_net}</description></item>\n"
output_xml.write(item_xml)
#on crée une fonction pour parcourir l'arborescence
def parcours(dossier : Path, fichier_xml, fichier_txt, rubrique):
for sub in sorted(dossier.iterdir()):
if sub.is_dir():
parcours(sub, fichier_xml, fichier_txt, rubrique)
if sub.is_file() and sub.name.endswith(".xml") and rubrique in sub.name:
extract_un_fil(sub, fichier_xml, fichier_txt, titres_uniques)
#une fois qu'on a créé toutes les fonctions, on les applique à notre corpus
#on récupère le chemin du dossier contenant le corpus 2021
dossier = Path(sys.argv[1])
#on récupère le numéro de la rubrique à traiter
rubrique = sys.argv[2]
with open (f"bao1-{rubrique}.xml", "w") as output_xml:
with open (f"bao1-{rubrique}.txt", "w") as output_txt:
header = "<?xml version=\"1.0\" encoding=\"utf-8\"?>\n<corpus>\n"
#on écrit la déclaration XML dans le fichier de sortie
output_xml.write(header)
#on crée un set qui va servir à s'assurer qu'il n'y a pas de doublons dans les fichiers de sortie
titres_uniques= set()
parcours(dossier, output_xml, output_txt, rubrique)
output_xml.write("</corpus>\n")
Pour télécharger le script Python : Script Python
Résultats
Les scripts produisent en sortie deux fichiers par rubrique.
- Un fichier XML. InternationalEconomieIdées
- Un fichier TXT. InternationalEconomieIdées