Présentation du projet

1. Autour de notre terme
Le terme que nous souhaitons étudier est celui de "mouvement social", ainsi que ses déclinaisons en langue anglaise ainsi qu'en langue chinoise.
Pourquoi "mouvement social" ?
Nous avons choisi ce terme car il occupe une place centrale au sein de la société française, alors que son rôle est beaucoup plus limité au sein de la société chionise, ce qui nous intrigue particulièrement. Au cours de l'année 2020, nous avons notamment été témoins en France de nombreux mouvements sociaux importants, que ce soient la manifestation contre la réforme des retraites ou la manifestation contre la loi "sécurité globale". Du côté des Etats-Unis, on peut noter l'émergence du mouvement "Black Lives Matter" et "anti-lockdown protests", alors qu'en Chine, le seul mouvement social d'envergure concerne les manifestations contre l'amendement de la loi d'extradition de Hong kong.
Nous souhaitons, à travers une analyse de textes autour de ce sujet, comprendre si la notion de mouvement social est connotée différemment en Chine par rapport à la France ou aux pays Anglo-Saxons.
Notre hypothèse
Notre hypothèse est que le terme "mouvement social" est connoté péjorativement en Chine, en tout cas plus qu'il ne l'est en France et dans le monde anglo-saxon.
2. La construction du corpus
Après avoir défini le terme et les langues de travail, nous avons procédé à la construction du corpus en commençant par récupérer des textes sur internet. Nous avons utilisé les moteurs de recherche "Google" et "Bing" pour collecter des textes en français et anglais; "Google" et "Baidu" pour les textes en chinois.
Après avoir entré le terme pour la langue donnée dans le moteur de recherche, nous avons utilisé "lynx" et des expressions régulières (cf. blog) pour récupérer en masse les urls qui nous étaient utiles. Nous avons créé trois fichiers textes pour sauvegarder les urls de la langue donnée.
La partie suivante concerne une série de traitements sur les urls collectés afin d'y extraire des textes bruts et d'effectuer sur ces textes quelques calculs sur le plan linguistique. Cette partie de travail a été réalisée principalement avec notre script écrit en Bash en suivant le processus illustré ci-dessous :
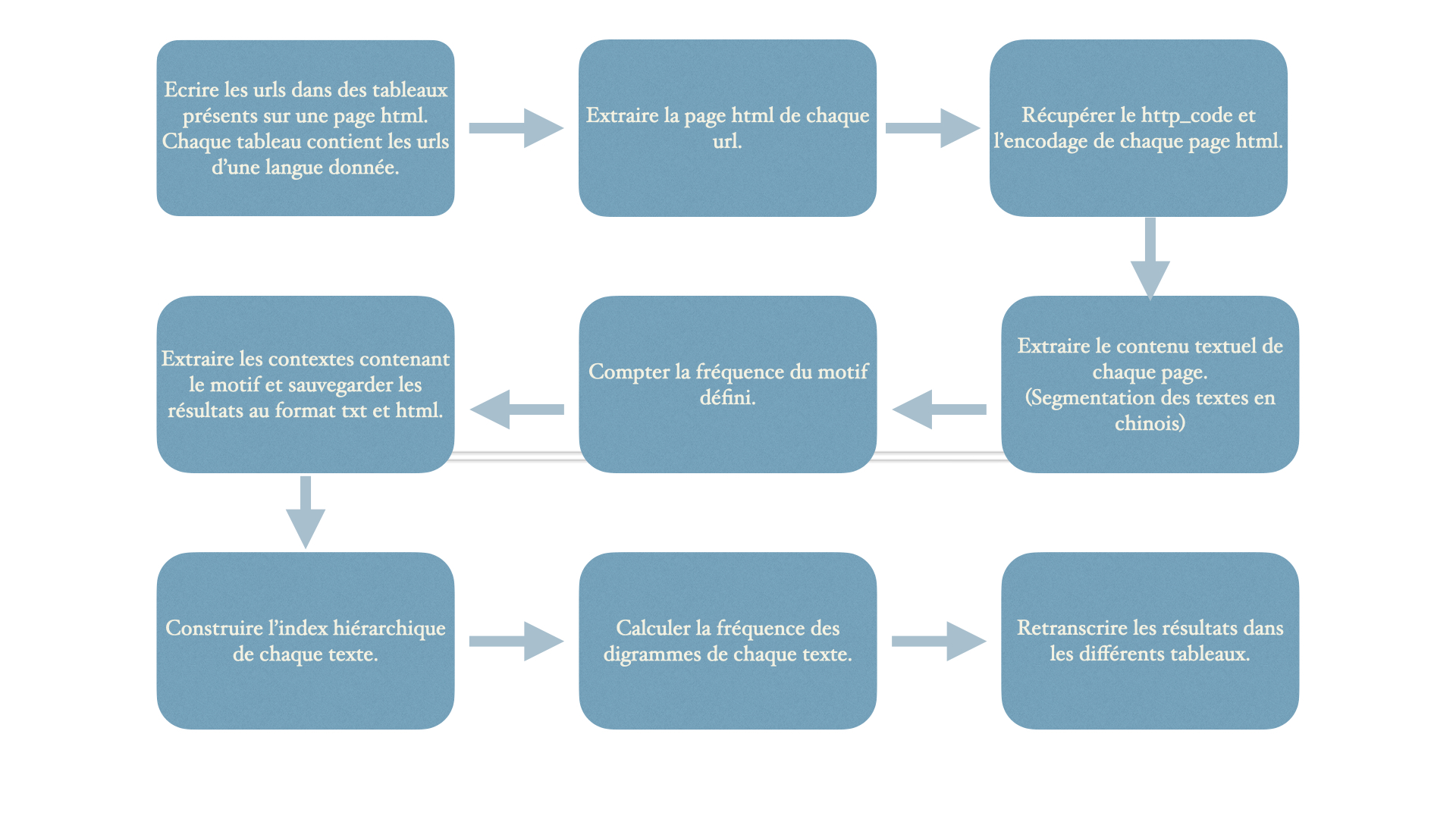
Les outils utilisés dans notre script :
Standford segmenter : segmentation des textes chinois (cf. blog)
httpstat : récupération de http_code et encodage d'une page html.
Readability-cli : extraction des textes bruts.
Minigrep-multilingue : extraire des contextes autour du motif et écrire les résultats au format html. Les contextes sont affichés avec plus de clarté.
Lynx : extraction des textes bruts.
La dernière étape consisite en la concaténation de corpus. Afin d'effectuer une analyse sur nos outils, il faut rassembler tous les textes extraits de la même langue dans un seul ficher en mettant une "étiquette" permettant de les distinguer les uns des autres. Ceci est également réalisé avec quelques lignes de commandes en Bash.
3. Analyse de corpus
Nous avons utilisé les deux outils présentés ci-dessous pour réaliser notre analyse de corpus :
* Nuages des mots
Le nuage des mots est une représentation visuelle des mots les plus utilisés dans un corpus donné. Nos nuages des mots ont été réalisés avec des outils en ligne: Nuages de mots.fr pour le corpus français, WordArt pour le corpus anglais et 微词云(weiciyun) pour le corpus chinois.
* ITrameur
ITrameur est un outil d'analyse textométrique disponible en ligne. Il nous permet d'obtenir des statistiques liées aux caractéristiques lexicographiques d'un corpus, par exemple le nombre de formes totales, la fréquence des formes, les co-occurrents autour d'une forme, les concordances d'une forme etc. ITrameur est l'outil principal pour nos analyses et il possède bien d'autres fonctions que nous n'avons pas encore totalement exploitées.