Script
Vous pouvez voir le script en cliquant ici !
Création des sous-dossiers
Avant d’écrire le script, nous avons créé les sous-dossiers nécessaires sur chacune de nos machines respectives, dans un dossier dédié au projet.
Les sous-dossiers ont été nommés :
- URLS, le fichier texte contenant les urls à traiter;
- PROGRAMMES, le script en format sh;
- DUMP-TEXT, le contenu textuel de chaque url;
- PAGES-ASPIREES, les pages aspirées de chaque url;
- CONTEXTES, le contexte de chaque motif;
- TABLEAUX, le tableau en format html s’affichant les résultats par le script;
- IMAGES.
Principe général du script
- Trois variables spécifiées lors du lancement du script depuis le Terminal: le dossier des URLS, le dossier des TABLEAUX, et le motif.
- On parcourt le fichier, URL par URL, grâce à l’implémentation d’un compteur.
- On crée un tableau, où on va traiter une URL par ligne.
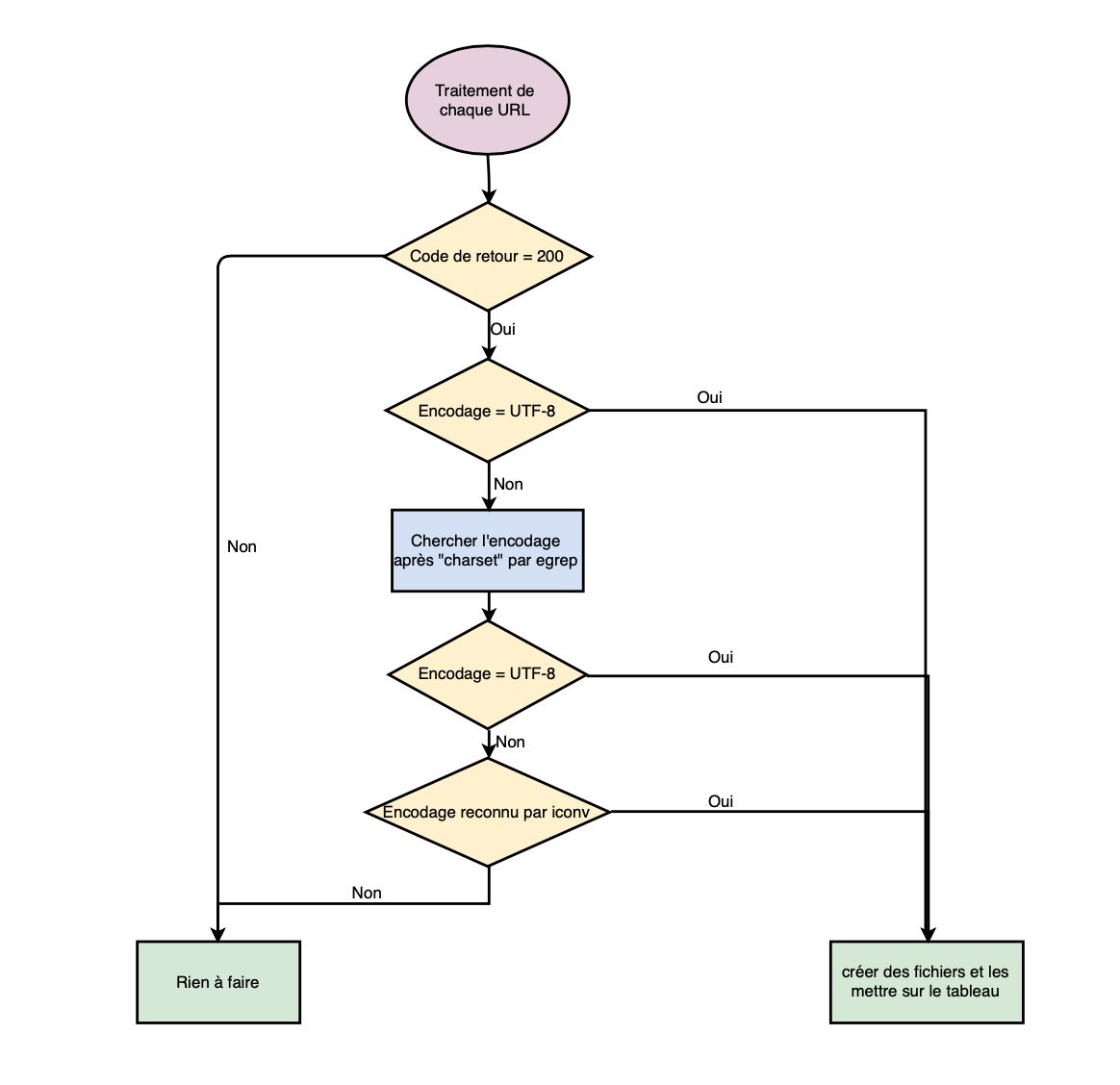
- On vérifie le code HTTP de chaque URL, s’il est égal à 200 on peut passer à la suite.
- On vérifie alors si l’encodage est en UTF-8, si c’est le cas on peut traiter l’URL grâce à différentes opérations ( Lynx Dump, Contexte, Fréquence Motif, Contexte HTML, index hiérarchique, bigramme ) et en inscrire le résultat dans le tableau.
- Si l’encodage n’est pas égal à UTF-8, on tente de le récupérer avec egrep, en spécifiant un set de caractères à identifier.
- Si l’encodage repéré s’avère être en UTF-8, alors on le traite avec les mêmes opérations déjà effectuées.
- Si l’encodage n’a pas été reconnu, on tente de le faire grâce à iconv.
- Si iconv donne une réponse non-vide, l’encodage a été reconnu et peut donc être traité grâce aux mêmes opérations.
- Si le code HTTP de base, n’est pas égal à 200, l’URL est considérée pourrie et ne peut être traitée.
Pour une explication détaillée du script, se référer à la section RÉALISATION DU SCRIPT, dans notre blog.
Afin de s'éclaircir la logique globale de notre script, nous présentons aussi le graphe ci-dessous.