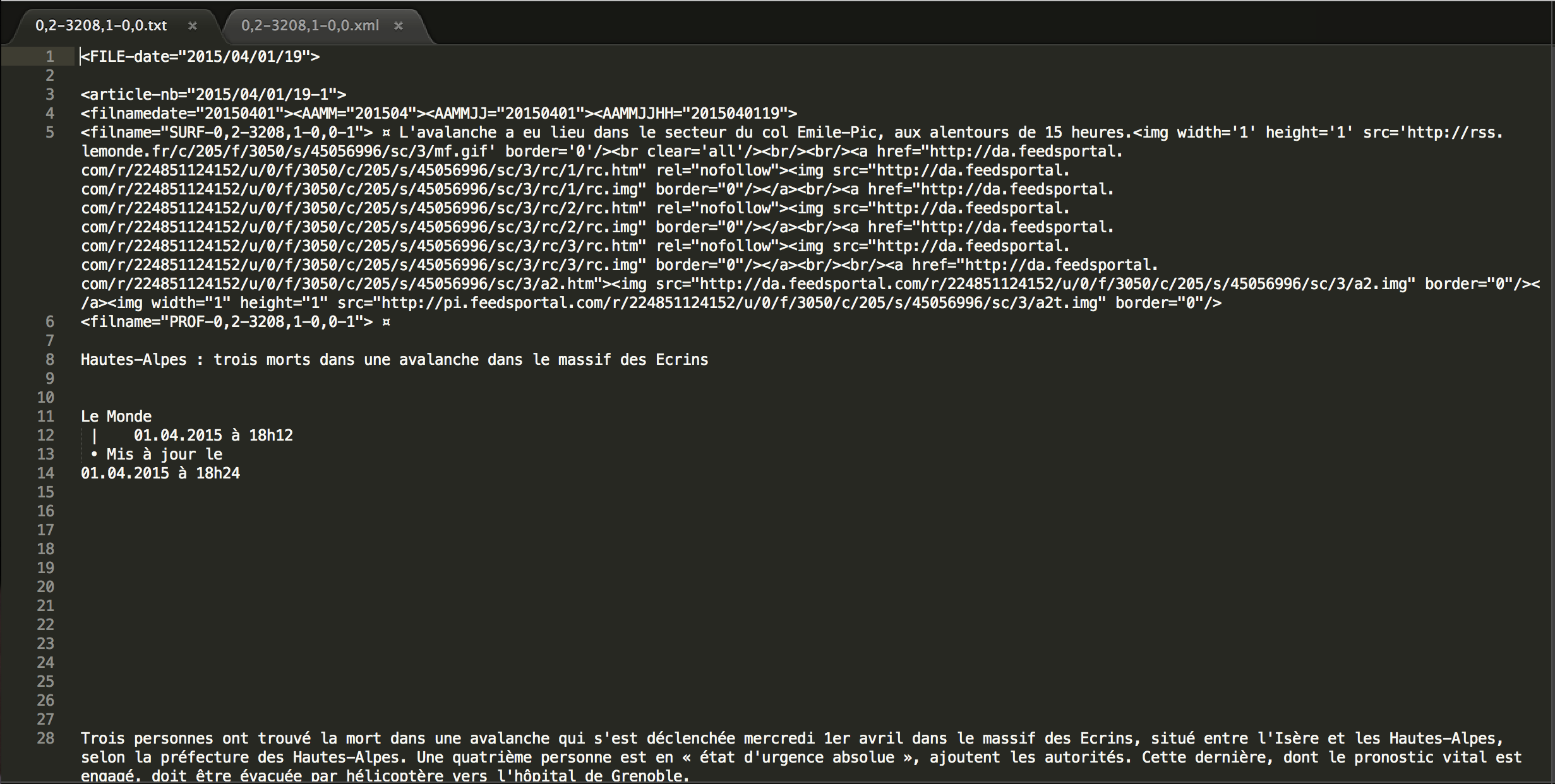
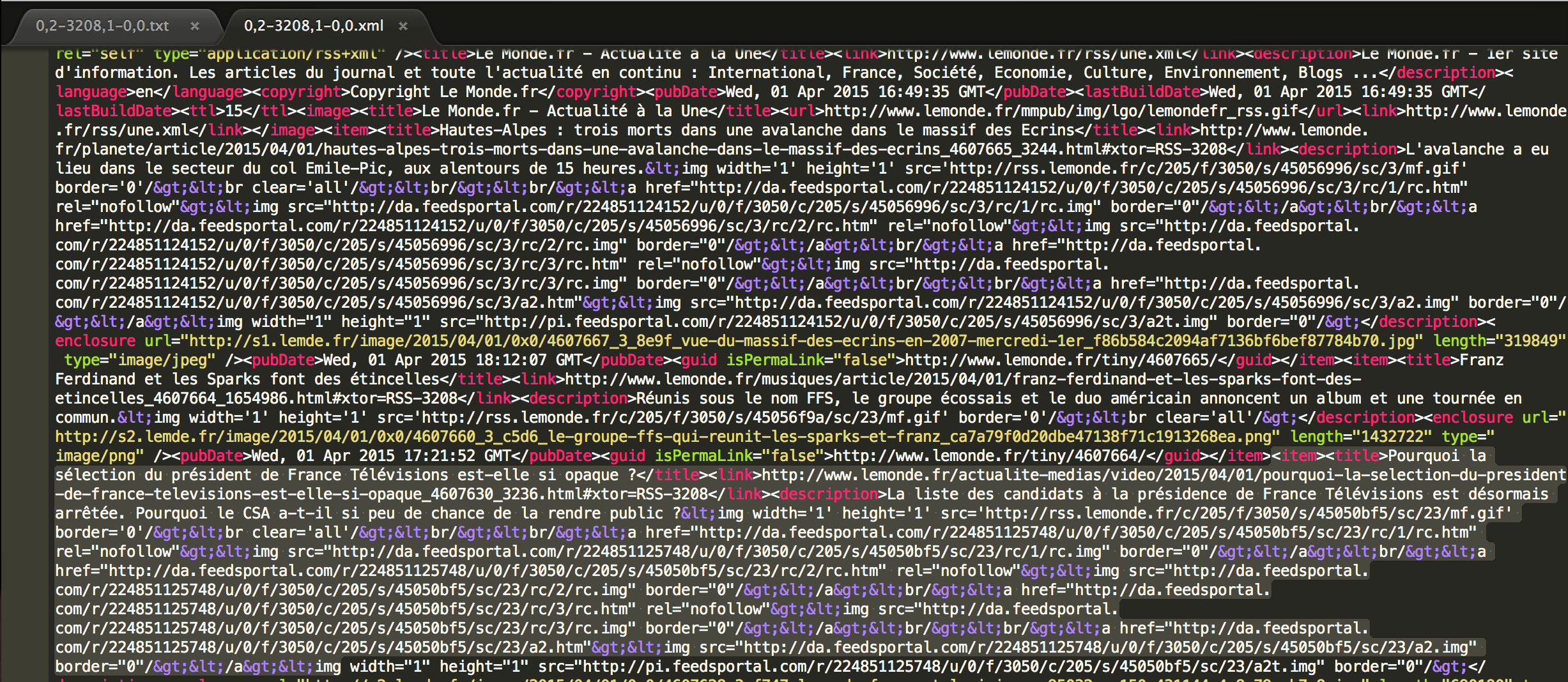
La BAO1 est la première étape de notre projet et consiste en l'extraction du texte, à la fois profond et de surface. La surface correspond au titre et à la description des fichiers xml et txt. En ce qui concerne l'extraction de la surface à partir des fichiers xml, nous avons recherché les balises "titre" et "description", dépendantes de la balise "item". La profondeur quant à elle est l'intégralité d’un article et son titre récupérés à partir des fichiers textes.
Nous avons donc procédé à l'extraction de deux manières différentes :
1° EXPRESSIONS REGULIERES : Surface
TRAITEMENT DE LA SURFACE
ENTREE : fichiers xml et txt du corpus 2015
SORTIE 1 : fichiers xml comprenant titre et description des articles
SORTIE 2 : fichiers txt comprenant titre et description des articles
#/usr/bin/perl
#Le programme prend en entrée le nom du répertoire contenant les fichiers à traiter
# Le programme construit en sortie un fichier structuré contenant sur chaque ligne le nom du fichier et le résultat du filtrage
#-----------------------------------------------------------
my $repertoire="$ARGV[0]";
my $rubrique = "$ARGV[1]";
my %dico;
# on s'assure que le nom du répertoire ne se termine pas par un "/"
$repertoire=~ s/[\/]$//;
# on initialise une variable contenant le flux de sortie
#----------------------------------------
my $output1="Regex-$rubrique.xml";
if (!open (FILEOUT,">$output1")) { die "Pb a l'ouverture du fichier $output1"};
print FILEOUT "\n";
print FILEOUT "\n";
print FILEOUT "BOTHUA \n";
close (FILEOUT);
#----------------------------------------
&parcoursarborescencefichiers($repertoire); # on lance la récursion.... et elle se terminera après examen de toute l'arborescence
#----------------------------------------
open (FILEOUT,">>:encoding(utf-8)", $output1);
print FILEOUT " \n";
close(FILEOUT);
exit;
#----------------------------------------------
sub parcoursarborescencefichiers {
my $path = shift(@_);
opendir(DIR, $path) or die "can't open $path: $!\n";
my @files = readdir(DIR);
closedir(DIR);
foreach my $file (@files) {
next if $file =~ /^\.\.?$/;
$file = $path."/".$file; #2016/01/19,00,00
if (-d $file) {
print " ==> ",$file,"\n";
&parcoursarborescencefichiers($file); #recurse!
print " ==> ",$file,"\n";
}
if (-f $file) {
# TRAITEMENT à réaliser sur chaque fichier
if ($file =~ /$rubrique.+\.xml$/) {
print "<",$i++,"> ==> ",$file,"\n";
#traitement pour extraire texte
$codage = "utf-8";
open (FIC, "<:encoding($codage)", $file);
open (OUT, ">>:encoding($codage)", "regex-$rubrique.txt");
open (OUT2, ">>:encoding($codage)", "regex-$rubrique.xml");
#ramener tout le flux textuel de FIC sur une seule ligne
my $texte="";
while (my $ligne = ) {
chomp $ligne;
$ligne =~ s/\r//g;
$texte = $texte . $ligne;
}
close FIC;
$texte =~ s/>\s+([^<]+?)<\/title><link>(?:[^<]+?)<\/link><description>([^<]+?)<\/description>/g) {
my $titre = $1;
my $description = $2;
$titre=~s/<.+?>//g;
$titre.=".";
$titre=~s/\?\.$/\?/;
$description=~s/<.+?>//g;
if (!(exists $dico{$titre})) {
$dico{$titre} = 1;
print OUT "$titre\n";
print OUT "$description\n\n";
print OUT2 "<item><title>$titre $description \n";
}
}
close OUT;
close OUT2;
# fin de traitement du fichier
}
}
}
}
Télécharger les fichiers obtenus
1B° EXPRESSIONS REGULIERES : Profondeur
TRAITEMENT DE LA PROFONDEUR
ENTREE : fichiers txt du Corpus 2015
SORTIE : fichiers txt nettoyés comprenant l'intégralité du contenu textuel des articles
#/usr/bin/perl
#-----------------------------------------------------------
my $rep="$ARGV[0]";
my $rubrique = "$ARGV[1]";
my %dico;
# on s'assure que le nom du répertoire ne se termine pas par un "/"
$rep=~ s/[\/]$//;
# on initialise une variable contenant le flux de sortie
#----------------------------------------
#----------------------------------------
&parcoursarborescencefichiers($rep); # on lance la récursion.... et elle se terminera après examen de toute l'arborescence
#----------------------------------------
open (FILEOUT,">>:encoding(utf-8)", $output1);
print FILEOUT "\n";
close(FILEOUT);
exit;
#----------------------------------------------
sub parcoursarborescencefichiers {
my $path = shift(@_);
opendir(DIR, $path) or die "can't open $path: $!\n";
my @files = readdir(DIR);
closedir(DIR);
foreach my $file (@files) {
next if $file =~ /^\.\.?$/;
$file = $path."/".$file; #2016/01/19,00,00
if (-d $file) {
print " ==> ",$file,"\n";
&parcoursarborescencefichiers($file); #recurse!
print " ==> ",$file,"\n";
}
if (-f $file) {
#!!!!!!!! TRAITEMENT MONDE PROFOND !!!!!!!!#
# On traite le fichier texte
if ($file =~ /$rubrique.+\.txt$/) {
# $i est un compteur
print "<",$i++,"> ==> ",$file,"\n";
$codage = "utf-8";
open (FIC, "<:encoding($codage)", $file);
open (OUT3, ">>:encoding($codage)", "$rubrique-regex-profond.txt");
# open (OUT2, ">>:encoding($codage)", "$rubrique.xml");
# ramener tout le flux textuel de FIC sur une seule ligne
my $texte="";
# tant que l'on a une ligne
while (my $ligne = ) {
# ^ debut de ligne | !~ operateur de recherche "ne contient pas"
# si la ligne ne commence pas par ^<
if ($ligne =~/(^
Télécharger les fichiers obtenus
2° XLM::RSS : Extraction du texte à l’aide de requêtes XPATH pour le parcours des fichiers XML.
Concernant l'installation des bibliothèques nécessaires se reporter à la page suivante :
Blog-PPE
TRAITEMENT DE LA SURFACE
ENTREE : fichiers xml du Corpus 2015
SORTIE : fichiers xml comprenant titre et description des articles
#! /usr/bin/perl
"""
Ce script permet l'extraction des balises title et description au sein des balises item
Il ne va donc parcourir que les fichiers XML de notre corpus et ne traitera par conséquent que la surface
"""
use XML::RSS;
use XML::Entities;
# le premier argument en ligne de commande sera le dossier 2015 contenant tout notre corpus
my $repertoire="$ARGV[0]";
# le second argument en ligne de commande sera la rubrique qui nous intéresse
my $rubrique="$ARGV[1]";
$repertoire=~ s/[\/]$//;
# on s'assure que le nom du répertoire ne se termine pas par un "/".
my %dico_titre=() ;
my %dico_description=() ;
#----------------------------------------------------------------------------------------------
# création du dossier qui contiendra les fichiers XML de sortie
$dir="XML-RSS-Bibli-$rubrique";
mkdir $dir;
# création des fichiers de sortie selon leur rubrique et ajout de leur entête en XML
my $output1="./$dir/XMLRSS-$rubrique.xml";
if (!open (OUT1,">:encoding(utf-8)", $output1)) {die "Pb à l'ouverture du fichier $output1"};
print OUT1 "\n" ;
print OUT1 "\n" ;
print OUT1 "BOTHUA 2016 \n" ;
#-----------------------------------------------------------------------------------------------
# num servira d'argument dans nos balises xml "item" pour les numéroter : cela peut être très utile pour effectuer des requêtes XPATH
$num=0;
&parcours_arborescence_fichiers($repertoire);
#---------------------------------------------------------------------------------------------
print OUT1 " \n" ;
close (OUT1) ;
#-------------------------------------------------
sub parcours_arborescence_fichiers
{
#création d'une variable du répertoire
my $path = shift(@_);
# ouvrir ce dossier
opendir(DIR, $path) or die "Impossible d'ouvrir $path: $!\n";
#créer une liste qui contient les éléments du répertoire
my @files = readdir(DIR);
closedir(DIR);
# pour chaque élément de cette liste
foreach my $file (@files)
{
# si le rép est . ou .., on passe au suivant
next if $file =~ /^\.\.?$/;
# chemin absolu de l'élément
$file = $path."/".$file;
# si c'est un répertoire
if (-d $file)
{
# on relance la procédure
&parcours_arborescence_fichiers($file);
}
# si c'est un fichier => c'est ce qui nous intéresse
if (-f $file)
{
# si c'est un fihier xml et la taille du fichier n'est pas 0
if (($file=~/.+-$rubrique,.+\.xml$/) && (-s $file !=0))
{
my $rss=new XML::RSS;
eval{$rss->parsefile($file);};
foreach my $item (@{$rss->{'items'}})
{
my $description=$item->{'description'};
my $titre=$item->{'title'};
# on élimine les doublons
if (!(exists $dico_titre{$titre}) and !(exists $dico_description{$description}))
{
$dico_titre{$titre}++;
$dico_description{$description}++;
# on les enregistre s'ils sont vus pour la première fois
# nettoyer les données pour que les entités s'affichent bien
$titre = XML::Entities::decode('all', $titre);
$description = XML::Entities::decode('all', $description);
#supprime balises existantes
$description=~ s/<[^>]+>//g;
$num++ ;
print OUT1 "- \n
$titre \n$description \n \n";
}
}
close (FILE);
}
}
}
}