Boite à Outils 1
Extraction du texte de la masse de données
La première étape du projet consistait à extraire le contenu de fichiers stockés dans une arborescence.
Présentation de l'arborescence :
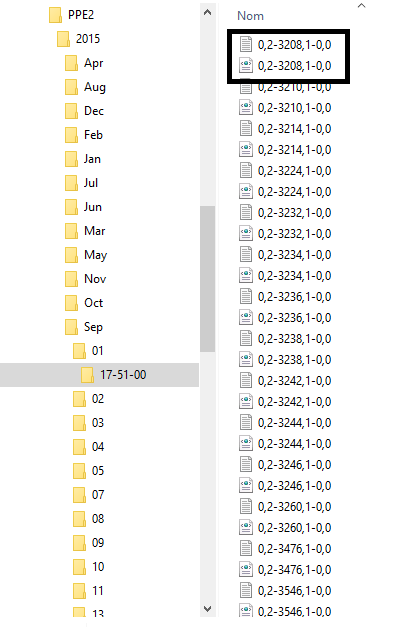
La base de données sur laquelle nous avons travaillé est une arborescence de fichiers classés par date de téléchargement. La racine est l'année couverte par les données, elle contient les dossiers de chaque mois qui contiennent tous les jours dudit mois. C'est dans le dossier journalier que l'on trouve le dossier avec, pour chaque rubrique du fil RSS, un fichier XML contenant la « surface » des articles (c'est à dire leurs titres et leurs descriptions) et un fichier .txt contenant la « profondeur » (c'est à dire le contenu des articles).Voici notre base de données, avec en encadré, les fichiers « surface » et « profondeur » de la rubrique que nous souhaitions extraire :
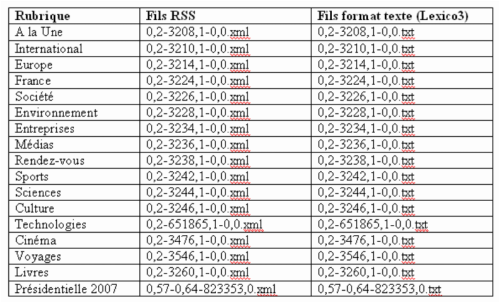
Voici les correspondances entre les Rubriques des fils RSS et leurs numéros de fils RSS (le numéro que l'on entre dans la ligne de commande du début de projet).
Nous choisissons de prendre la rubrique "A la une".
Méthodes employées :
Nous avons utilisé deux méthodes différentes pour extraire le contenu de ces deux fichiers depuis tous les répertoires contenus dans 2015. La première a constisté à développer deux scripts en langage Perl (un pour la « surface » et un pour la « profondeur ») utilisant des expressions régulières. La seconde consistait à écrire des scripts de Perl utilisant des bibliothèques déjà constituées et récupérées depuis CPAN. Cette méthode permet seulement l'extraction de données depuis un fichier XMl, elle n'a donc pas permis d'extraire le contenu des fichiers « profondeur ». L'extraction de la surface avec des expressions régulières nous a permis de d'obtenir un fichier résultat en XML et un fichier résultat en texte brut. Pour l'extraction de la profondeur avec cette même méthode, nous n'avons obtenu qu'un fichier .txt car le fichier d'origine ne prettait pas à une structuration en XML. La seconde méthode, l'extraction via des bibliothèques XML, nous a fait utiliser trois bibliothèques différentes dans trois scripts différents pour obtenir des résultats similaires: XML::RSS, XML::LIBXML et XML::XPATH.
PREMIERE METHODE : SCRIPTS EN PUR PERL
Vous pouvez télécharger le script de cette première methode ici pour la surface mais aussi là pour la profondeur. Ces scripts permettent non seulement d'extraire la surface ou la profondeur mais aussi d'annoter le texte grâce à Treetagger dont nous parlerons dans la Boite à outils 2. Les resultats de ces extractions sont disponibles ici et ici.
SECONDE METHODE : SCRIPTS AVEC DES BIBLIOTHEQUES
XML::RSS : Vous pouvez trouver le lien vers ce premier script ici
La version dump de l'extraction : Pour télécharger le script rendez-vous ici.
XML::LIBXML avec une fonction nettoyage : Pour voir notre script vous pouvez telecharger les fichiers ici.
XML::XPATH avec une fonction nettoyage : Vous pouvez télécharger notre script ici.


