
Les étapes ardues du script bash
Voici les différentes étapes de la construction du script bash :
Chemins et variables
Tous les chemins sont stockés dans des variables, ce sera donc les seules modifications à apporter au script en fonction des arborescences de travail.

Aspiration des pages
Première boucle de traitement : à chaque fichier sera créé un tableau d’analyse. Deuxième boucle : pour chaque ligne du fichier (correspondant à une URL) la page web est aspirée et l’encodage récupéré.

Encodage et téléchargement
Dans le cas où la page est encodée en UTF-8 : téléchargement du contenu de la page web grâce à lynx -dump puis extraction du contexte du mot cible grâce à egrep.
On compte ensuite avec la commande wc le nombre de mot du contexte : s’il est vide, on l’indique dans le tableau d’analyse, sinon, on le nettoie.

Dans le cas où l’encodage de la page web ne serait pas en UTF-8 : on le convertit vers l’UTF-8 au moyen de la commande iconv.

On réeffectue ensuite les mêmes traitements.
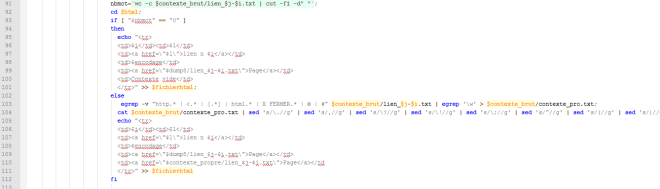
Contexte : contenu et nettoyage
Le contenu des fichiers contextes est à nouveau vérifié et les contextes sont, s’ils existent, nettoyés.

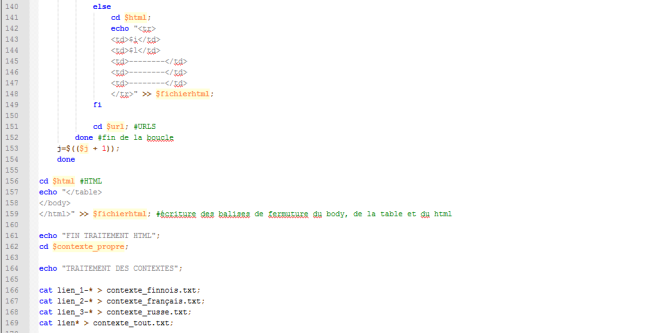
En cas d'erreur + fin du script
Dans le cas où l’aspiration de la page web par wget aurait échoué : affichage de pointillés dans le tableau. On sort ligne 152 de la deuxième boucle : toutes les lignes du fichier ont été traitées.
On rajoute 1 au compteur de tableau puis on ferme la première boucle. L’ensemble des fichiers étant traité, on ferme le fichier résultat. Les dernières lignes de code permettent de fusionner les
fichiers de contexte tous ensembles et en fonction de la langue.
Vous pouvez trouver plus d'illustrations et d'explications en consultant les billets du blog sur la question.