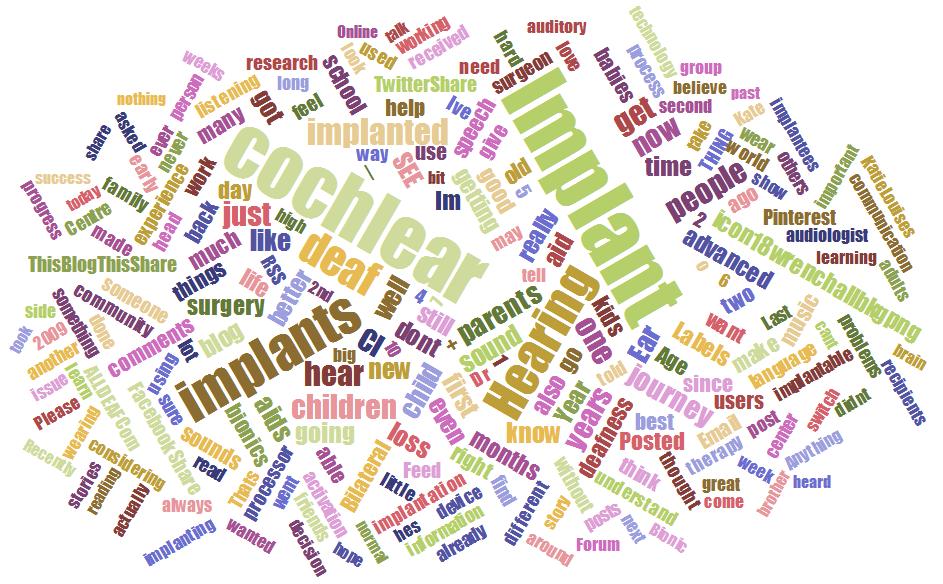
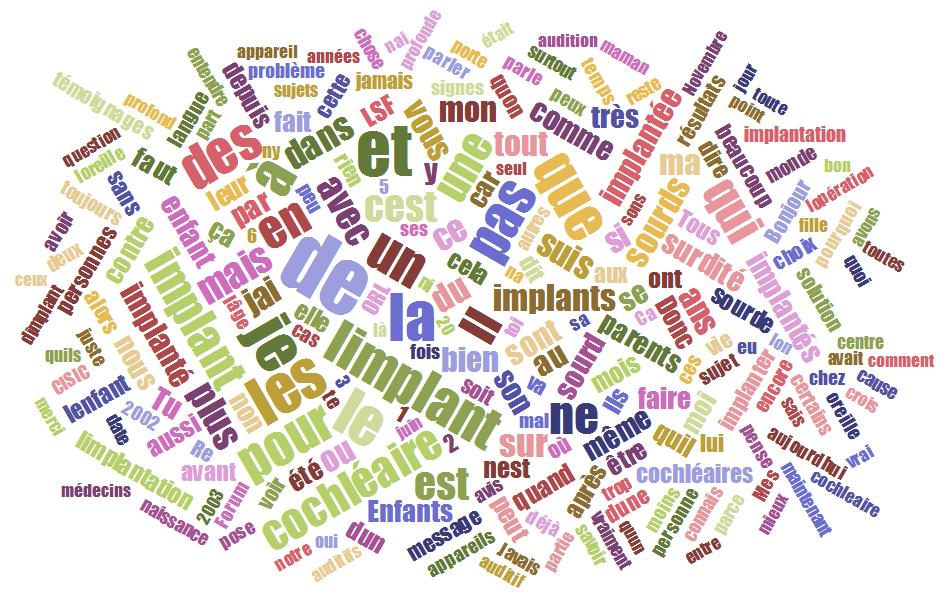
After having obtained the dumped texts and the contexts that constitute our corpus, we may use cloud generators to get this sort of representation of the most used words (or tags) with a proportional font size according to the number of times used.