Machine à écrire Perl
Consigne :
Voici une machine à écrire électronique en Perl. Essayez la , tapez CONTROL-D pour arrêter.
while(
{ print $_;
}
Chaque fois que vous tapez ENTER une ligne est acceptée et imprimée sur lécran. La variable spéciale $_ contient chaque ligne dentrée.
Changez le programme de manière suivante : au lieu dafficher la lettre ligne par ligne on veut afficher toute la lettre lorsquon a fini. On indique à notre machine quon a fini en tapant STOP (suivi par ENTER, naturellement).
Réponse :
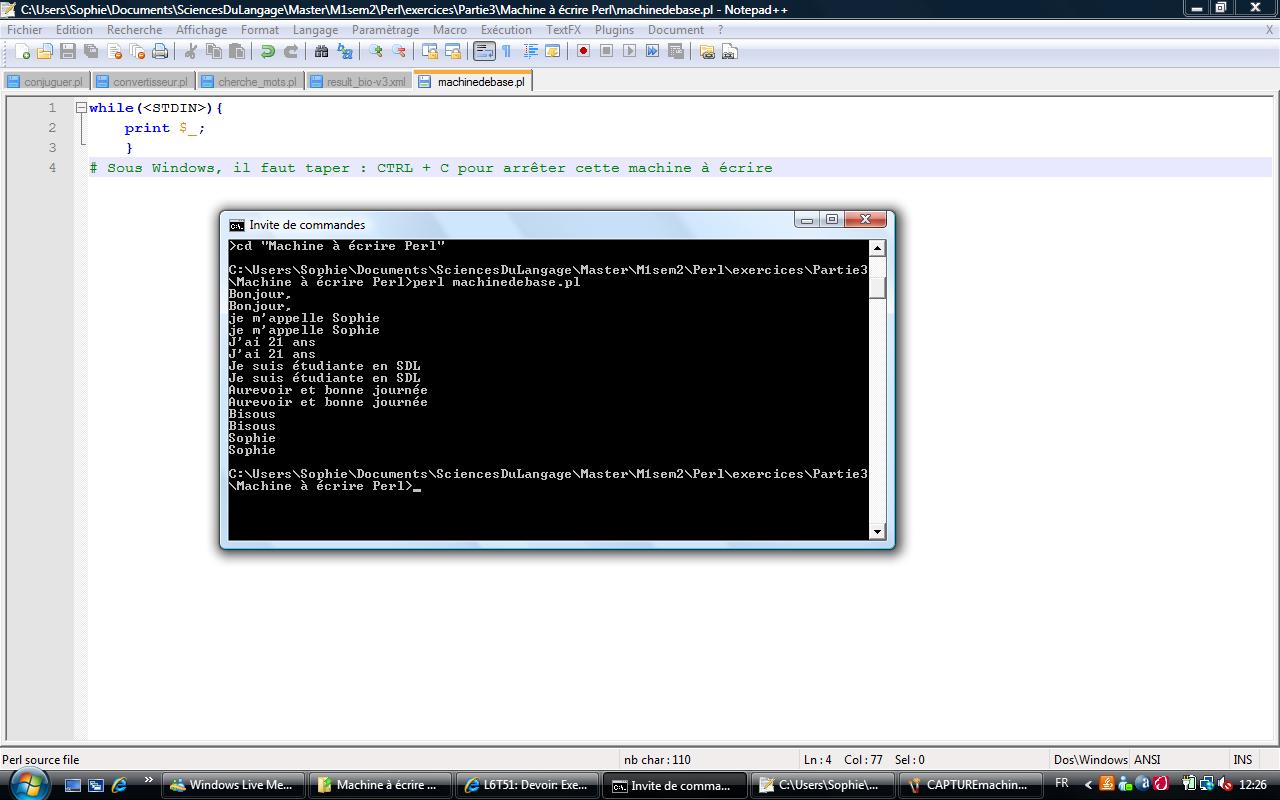
Voici le script de la machine à écrire de base :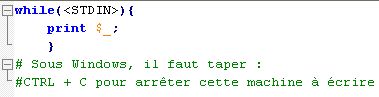
Télécharger le script (clic droit + enregistrer la cible sous)
Voir le résultat
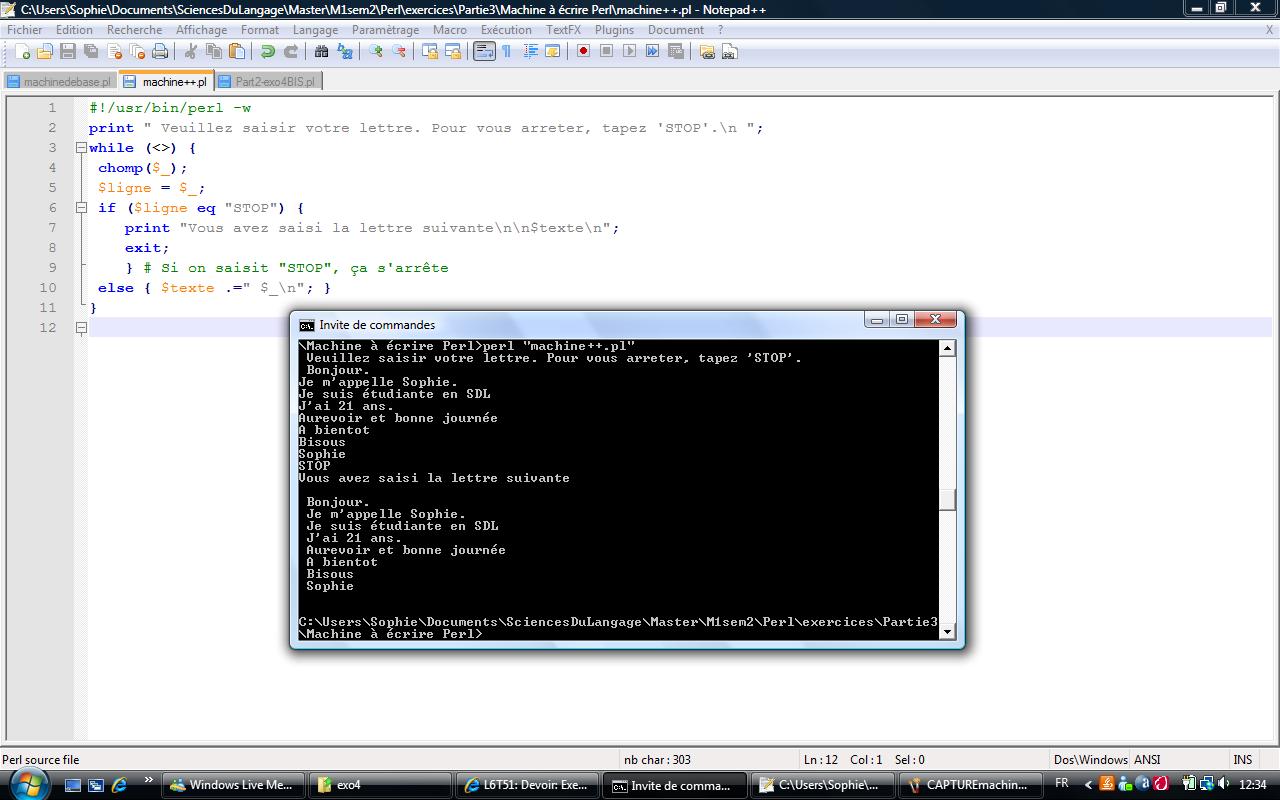
Voici le script amélioré de la machine à écrire :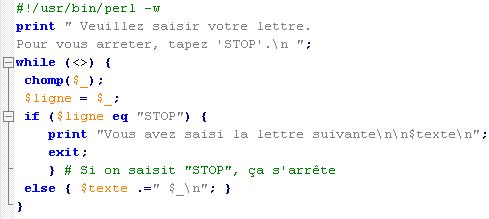
Télécharger le script (clic droit + enregistrer la cible sous)
Voir le résultat
Retourner en haut de la page
{kind=link}
{kind=link}
Compter les mots
Consigne :
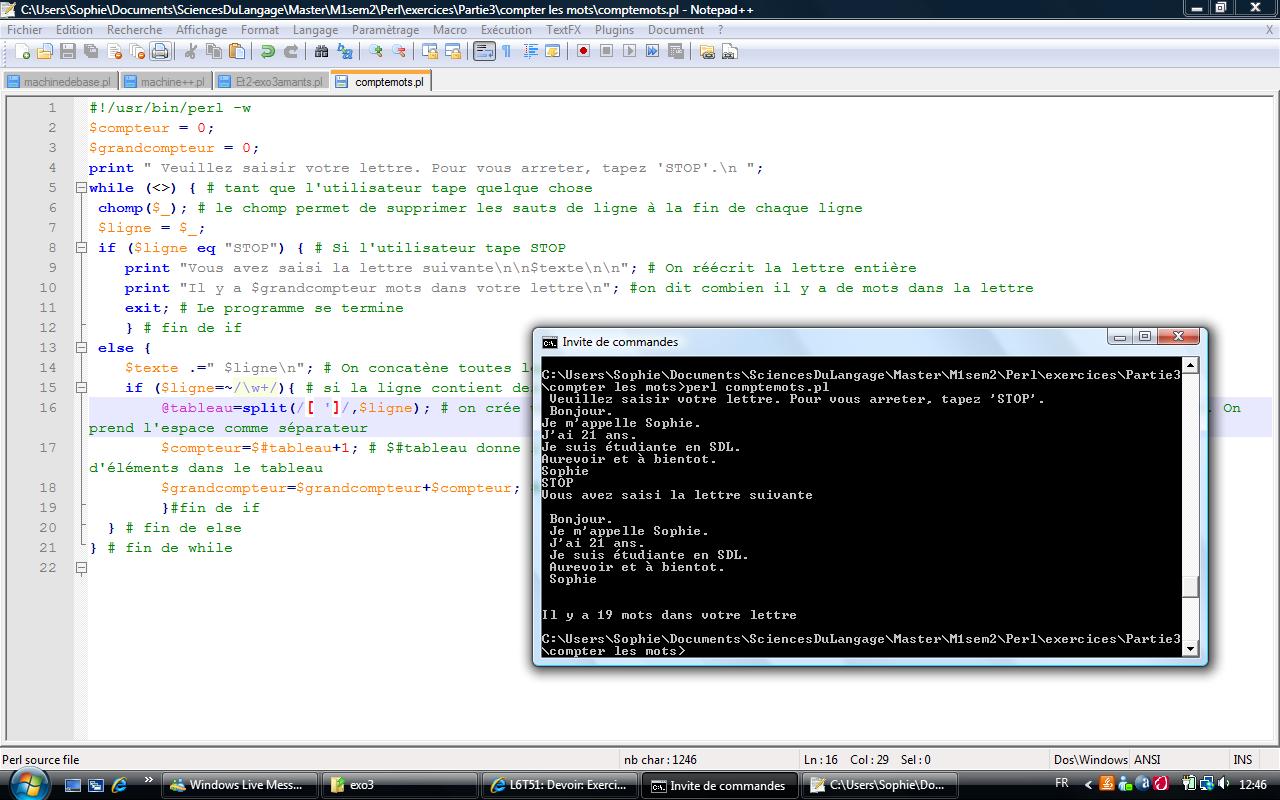
Servez-vous de split pour calculer et afficher le nombre de mots dans votre lettre du programme précédent.
Réponse :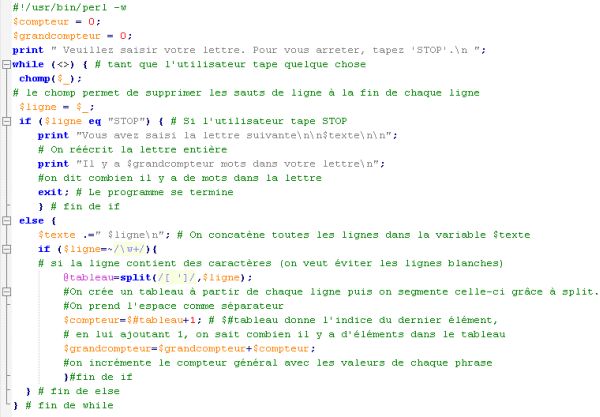
Télécharger le script (clic droit + enregistrer la cible sous)
Voir le résultat
Retourner en haut de la page
{kind=link}
Comptage des lignes
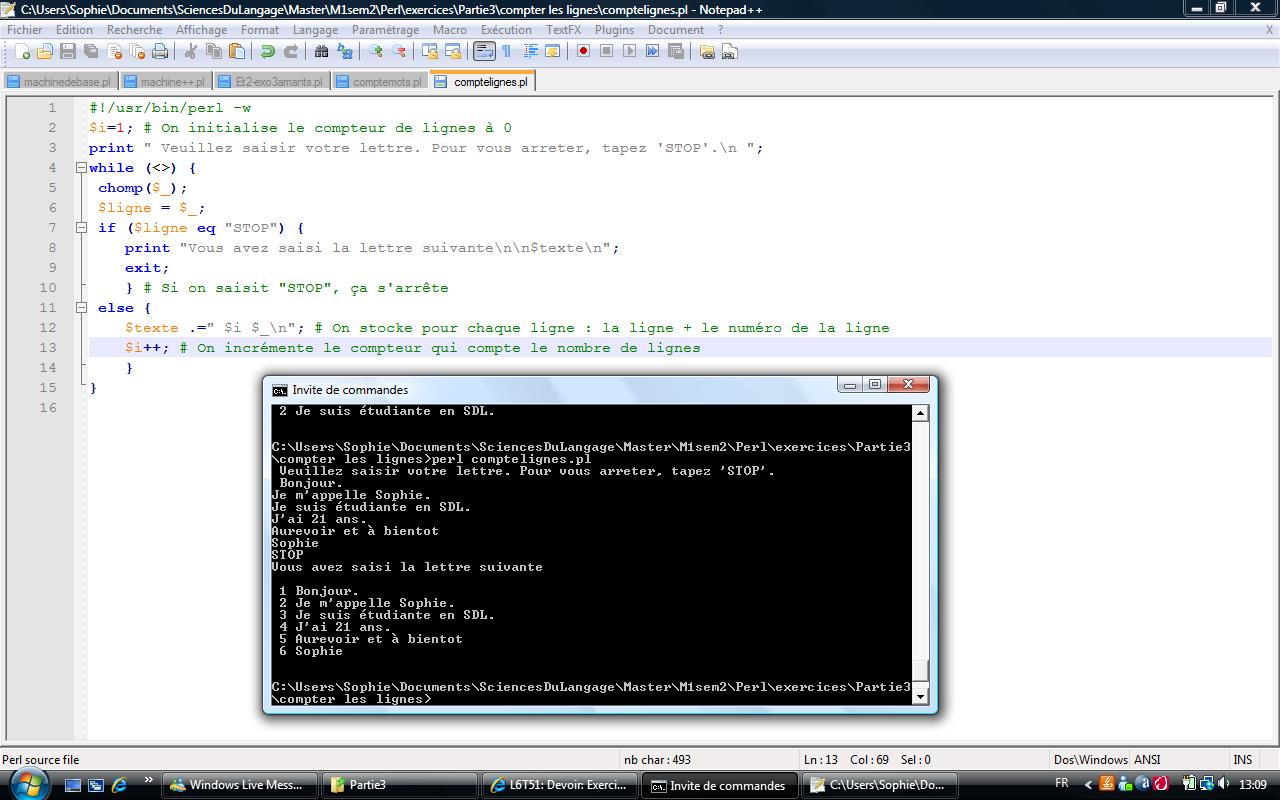
Consigne :
Affichez la lettre entière de votre programme précédent avec un compteur de lignes au début de la ligne.
Réponse :
Télécharger le script (clic droit + enregistrer la cible sous)
Voir le résultat
Retourner en haut de la page
{kind=link}
Manipulation, constitution de dictionnaires et de nouveaux corpus
Consigne :
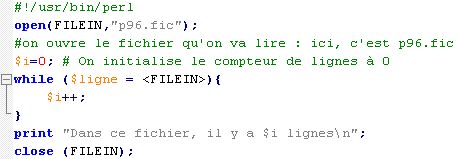
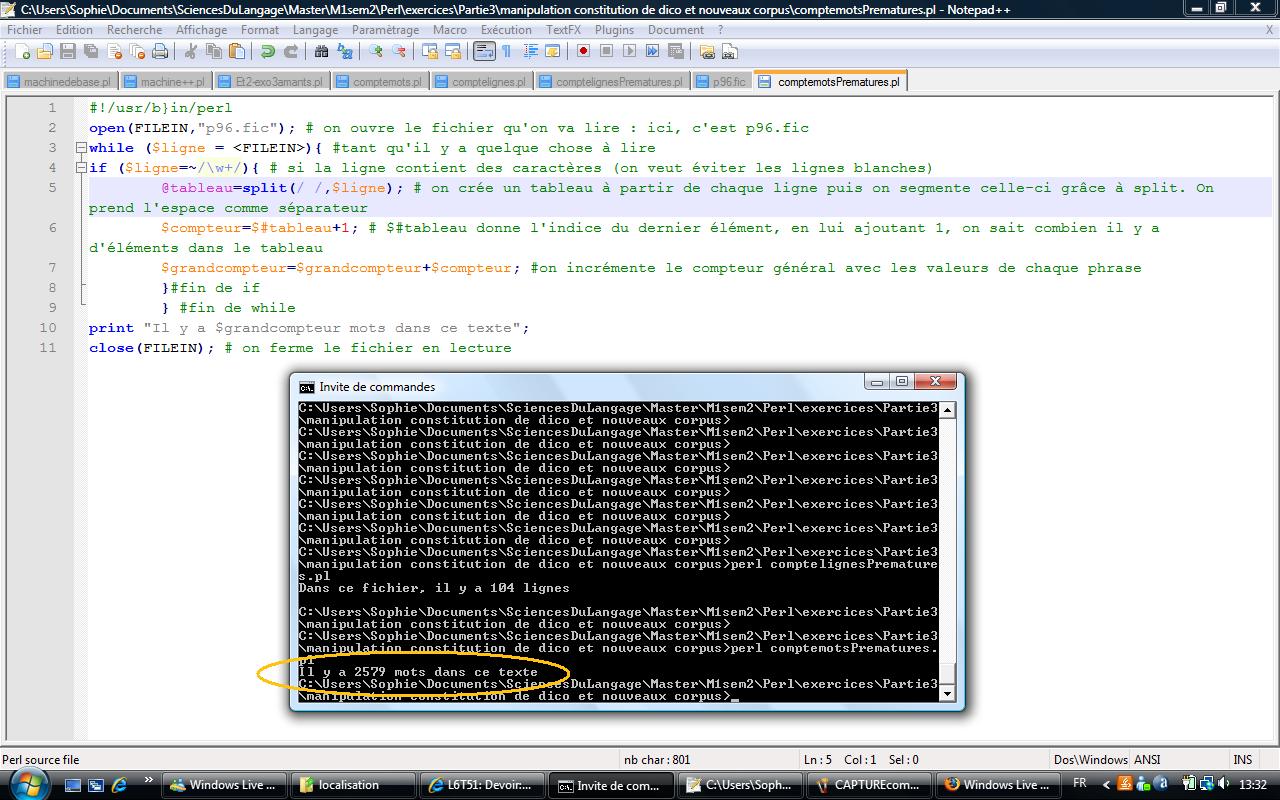
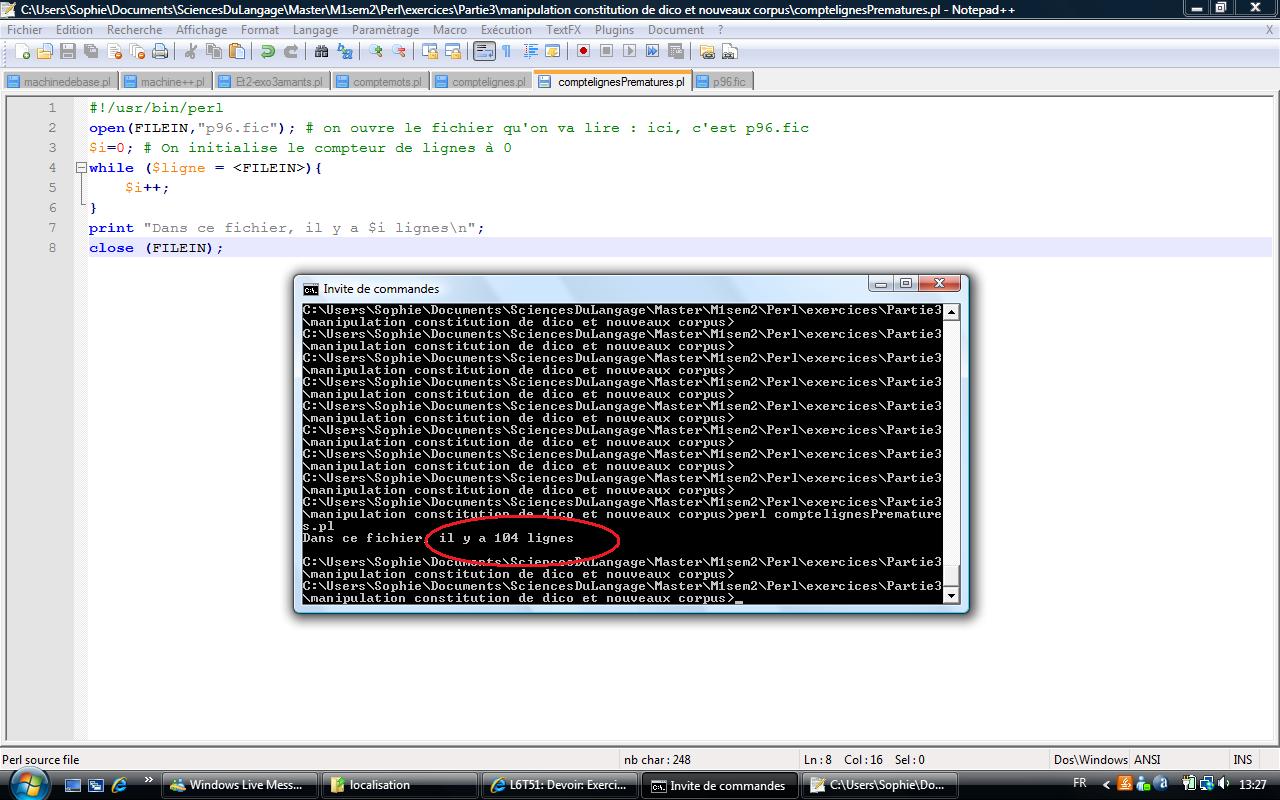
- Construire un programme qui lit un état quelconque du corpus Prématurés et compte le nombre de lignes du fichier lu.
- Construire un programme qui lit un état quelconque du corpus et compte le nombre de mots du fichier lu : pour obtenir le nombre de mots d'une phrase, il suffit de compter le nombre d'espaces et d'ajouter 1.
Réponse :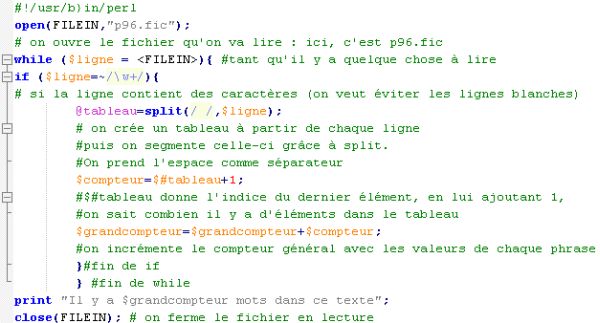
Télécharger le script (clic droit + enregistrer la cible sous)
Voir le résultat
Télécharger le script (clic droit + enregistrer la cible sous)
Voir le résultat
Retourner en haut de la page
{kind=link}
{kind=link}
Construction de dictionnaires
Consigne :
Construire un (ou plusieurs) programme(s) qui doit lire les corpus bébés et infirmières et construire pour chacun de ces corpus un dictionnaire contenant toutes les formes graphiques de ces corpus.
Réponse :
Voici le script pour le fichier p96.bal: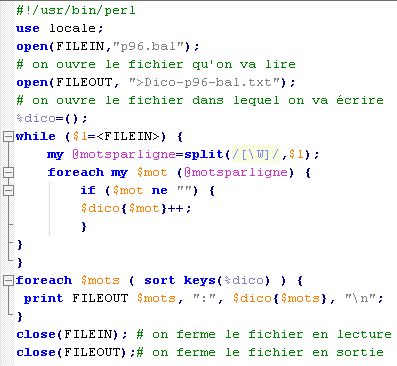
Télécharger le script (clic droit + enregistrer la cible sous)
Voir le résultat
Voici le script pour le fichier p96.fic: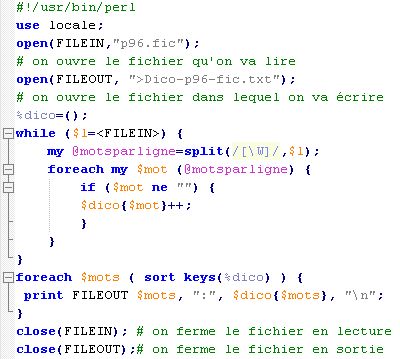
Télécharger le script (clic droit + enregistrer la cible sous)
Voir le résultat
Voici le script pour le fichier p96.tab:
Télécharger le script (clic droit + enregistrer la cible sous)
Voir le résultat
Voici le script pour le fichier p96.tag: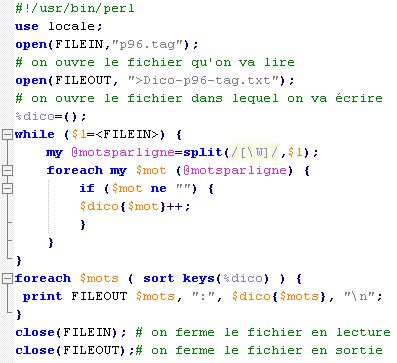
Télécharger le script (clic droit + enregistrer la cible sous)
Voir le résultat
Retourner en haut de la page
Constitution des corpus
Consigne :
Cette partie vise à la construction de nouveaux états du corpus à partir de données textuelles diverses. Il s'agira en particulier de voir comment a été construit la version HTML du corpus : i.e. comment passer des fichiers au format TXT vers des fichiers au format HTML.
- Construire un programme qui prend en entrée le fichier p96.bal et produit une version HTML de ce fichier.
- Construire un programme qui prend en entrée le fichier p96.bal et produit une version HTML de ce fichier. Les noms des champs devront apparaître dans la version HTML produite.
Réponse :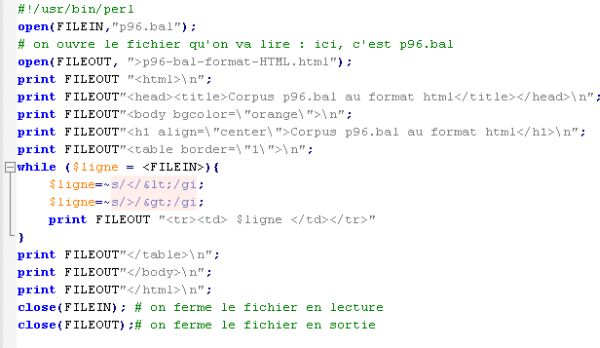
Télécharger le script (clic droit + enregistrer la cible sous)
Voir le résultat
Retourner en haut de la page
Fréquence des mots
Consigne :
Afficher une liste des mots d'un état quelconque du corpus Prématurés en ordre alphabétique :
- Combien de types de mots différents il y a dans le texte ?
- Afficher une liste des types de mots en ordre de fréquence descendant.
- Quelle est la fréquence la plus haute ?
- Combien de mots ont une fréquence de 1 ?
- Combien de mots ont une fréquence inférieure à 10 ?
Réponse :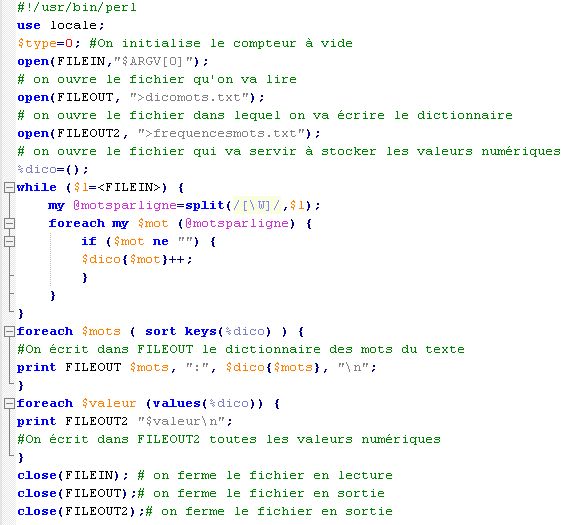
Ce premier script prend en argument dans la ligne de commande : p96.fic. Il crée un dictionnaire : dicomots.txt et aussi une liste de valeurs numériques qui correspondent au nombre d'apparitions de chaque mot : frequencesmots.txt.
Télécharger le script (clic droit + enregistrer la cible sous)
Voir dicomots.txt
Voir frequencesmots.txt
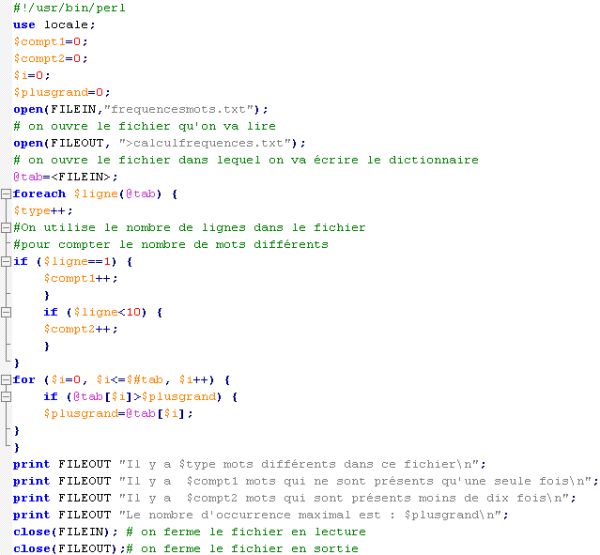 Ce deuxième programme fait des calculs à partir de frequencemots.txt et écrit ces calculs dans calculfrequences.txt.
Ce deuxième programme fait des calculs à partir de frequencemots.txt et écrit ces calculs dans calculfrequences.txt.
Télécharger le script (clic droit + enregistrer la cible sous)
Voir calculfrequences.txt
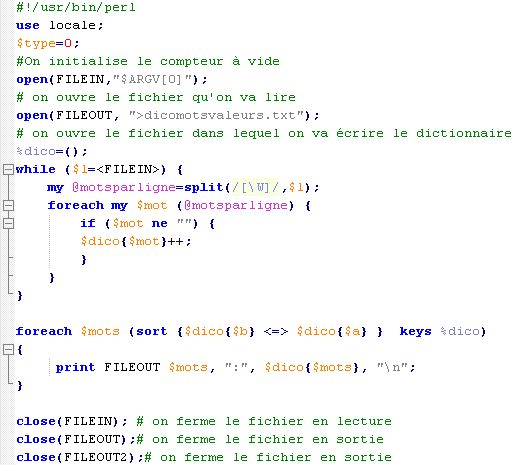
Enfin, ce troisième programme trie par valeur le dictionnaire et donne la sortie : dicomotsvaleurs.txt.
Télécharger le script (clic droit + enregistrer la cible sous)
Voir dicomotsvalueurs.txt
Retourner en haut de la page
Fréquence des mots sur corpus
Consigne :
Choisir sur le web, 2 textes en anglais (le texte d'un journal (1 ou plusieurs articles) et le texte d'un pièce de théâtre par exemple un extrait d'une pièce de Shakespeare) et les sauvegarder dans 2 fichiers.
- Construisez les listes de fréquences de mots de chacun, comparez.
- Quelles différences sont liées au hasard (choix du texte), lesquelles montrent les évolutions de la langue, lesquelles des différences de genre ?
Réponse :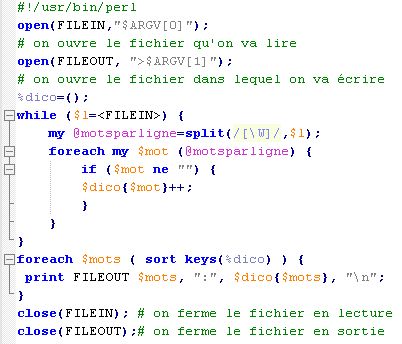
Télécharger le script (clic droit + enregistrer la cible sous)
Pour le texte NewYorkTimes.txt : Voir le résultat
Pour le texte Othello.txt : Voir le résultat
Afin que la comparaison entre les deux fichiers soit juste, nous avons pris deux fichiers de la même taille. Othello.txt est un extrait de la première scène de la pièce de Shakespeare : Othello. NewYorkTimes.txt est un article pris sur le site du New York Times.
On constate des différences liées au hasard. Le verbe be est plus présent dans la pièce de théâtre que dans l'article de journal. Cette différence semble dûe au hasard. Le fait que le mois April soit dans l'article de journal et pas dans la pièce de théâtre est complètement lié au hasard.
On constate des différences liées au genre. On remarque que dans le texte de la pièce de théâtre, on trouve des prénoms qui sont ceux des personnages. Il est normal de ne pas trouver ça dans un article de journal. Le pronom I est également beaucoup plus fréquent dans la pièce de théâtre que dans l'article de journal car chaque personnage parle à la première personne alors que dans un journal, on utilise plutôt des pronoms à la troisième personne comme le pronom he qui est beaucoup plus fréquent dans l'article. Le mot house est très présent dans l'article de journal car le thème abordé est 'la décoration de maison'. C'est pourquoi on trouve 10 occurrences dans l'article contre seulement 2 dans la pièce de théâtre. Il est également normal de ne pas trouver le mot poison dans un article de journal qui parle de décoration, alors qu'il est dans la pièce de théâtre. On constate également que la pièce de théâtre contient beaucoup plus de mots interrogatifs en wh- que l'article de journal. En effet, les personnages se posent des questions mutuellement, ce qui n'est pas le cas dans un article de journal, sauf s'il s'agit d'une interview.
On constate des différences liés aux évolutions de la langue. En effet, dans le journal, on trouve des mots comme : TV.
Retourner en haut de la page
Création d'un moteur de recherche documentaire
Consigne :
Question 1 : Ecrire un programme qui lit un fichier texte, et renvoie un hachage contenant le nombre d'apparitions de chaque mot du fichier.
Question 2 : Ecrire un programme qui demande un répertoire contenant des fichiers texte, et qui renvoie un tableau de hachages, où on stocke les comptages d'apparitions de chaque mot pour chacun des fichiers présents dans le répertoire.
Question 3 : Modifier ce programme pour qu'il crée en plus un hachage dont les clés sont tous les mots rencontrés, et dont les valeurs représentent le nombre de documents où apparaît un mot donné.
Question 4 : On appelera tf(w,d) le nombre de fois où apparaît un mot w dans un document d et df(w) le nombre de documents où apparaît w. On définit alors la fréquence inverse d'apparition par idf(w)=log N/df(w), où N est le nombre de documents. On peut calculer une similarité entre deux documents d et d' en calculant : (sum_w tf(w,d).tf(w,d').idf(w)^2) / ((sum_w tf(w,d)idf(w)) (sum_w tf(w,d')idf(w))). Ecrire une fonction qui renvoie la similarité entre deux documents.
Question 5 : Demander à l'utilisateur de saisir une requête. On considérera que cette requête constitue un document, et par conséquent la fonction doit calculer le hachage correspondant à cette requête, puis renvoyer le numéro du document dont la similarité avec la requête est la plus forte.
Question 6 : Ecrire un programme, qui lit un répertoire contenant des fichiers textes puis demande des requêtes à l'utilisateur et y répond en renvoyant le document le plus pertinent.
Réponse :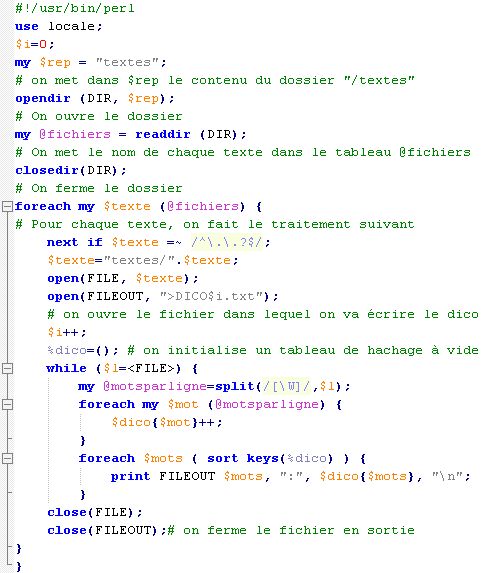 Malheureusement, nous n'avons pu faire que les deux premières questions de cet exercice.
Malheureusement, nous n'avons pu faire que les deux premières questions de cet exercice.
Télécharger le script (clic droit + enregistrer la cible sous)
Voir le résultat
Retourner en haut de la page