Les étapes du projet
On trouvera ici un commentaire de certaines des étapes et des problèmes importants rencontrés au cours de la réalisation du projet (les éléments directement liés au script sont rangés dans la page Script).
Problèmes spécifiques posés par le japonais
Le choix du mot
Après quelques errements (voir Epaves), j'ai finalement choisi de travailler sur le mot "société". A partir des différentes acceptions trouvées dans le TLF, j'en ai sélectionné cinq qui me semblaient les plus pertinentes. La "pertinence" a été jugée sur deux critères : (1) fréquence d'utilisation, (2) spécificité de l'acception (voir plus bas les choix effectués).
Acceptions
- 1. La société au sens de groupement humain (acception sociologique)
- 2. La société en tant que contrat entre plusieurs parties à but lucratif (entreprise)
- 3. La société comme association d'individus partageant des mêmes centres d'intérêts (société savante)
- 4. La société comme ensemble des relations mondaines (danses de société, briller en société)
- 5. [un cas particulier] la Société des Nations (SdN)
Traductions
Pour lesquelles j'ai adopté les traductions suivantes en japonais :
- 1. shakai 社 会
- 2. kaisha 会 社
- 3. gakkai 学 会
- 4. shakô 社 交
- 5. Kokusai renmei 国 際連盟
Choix
(a) J'ai choisi d'abandonner l'acception de "société" signifiant la "compagnie de quelqu'un" (ex : Il préfère la société des femmes) : cet emploi assez littéraire est extrêmement peu fréquent sur le web, d'une part ; et d'autre part, il m'a semblé avoir un sens assez proche de celui de l'acception 4 (et ce aussi bien en français qu'en japonais d'ailleurs).(b) La traduction de l'acception 3 par gakkai 学会 ("société savante") n'est, d'un strict point de vue linguistique, pas très satisfaisante (très restrictive), mais elle relève d'un choix pratique. En effet, si le terme kai 会 convient mieux (car il regroupe tous les types de "sociétés" potentiellement désignées : société savantes, militantes, d'amateurs de courses hippiques, des Amis de Machin Truc, etc.), c'est également un mot minimal qui entre en composition dans beaucoup d'autres mots en japonais (shûkai 集会 "réunion", kôenkai 講 演会 "conférence", kaiin 会 員 "membre", etc.), ce qui laissait présager des difficultés considérables dans la phase de recherche du mot dans le contexte.
(c) Le choix de shakô et non kôsai 交際, pourtant plus souvent donné dans les dictionnaires japonais-français comme traduction de l'acception 4 ("fréquentations, relations") est la conséquence d'un constat : sur le web ce dernier terme, lui-même polysémique, est massivement employé dans le sens de "relations sexuelles" et non dans le sens recherché.
Sélection des URL
L'idée du projet étant d'obtenir des contextes de traductions comparables, il fallait sélectionner 50 URL (25 en français / 25 en japonais) de manière à ce que chaque URL trouve un équivalent de traduction dans l'autre langue (ex : 5 URL pour le sens x en français = 5 URL pour le sens x en japonais).Comme on le verra dans le tableau, la répartition des URL par acception est fortement déséquilibrée. En effet, plutôt que de chercher à obtenir, de manière un peu artificielle, un nombre équivalent d'URL pour chaque sens, nous avons préféré conserver les proportions des occurrences réelles de chaque sens sur le web.
Arborescence
| L'arborescence du
projet achevé est la suivante : un répertoire
principal (projet_MASTER1)
contenant 5 répertoires sous-répertoires (programmes, listes_URL, contextes, pages_aspirees, dump) dont certains
(marqués avec une étoile) comprennent deux
répertoires de langue (FR
et JP)
contenant 5 sous-répertoires de sens ("sens1",
"sens2", ...,
"sens5"), comme on peut le voir sur l'image ci-contre (fig.2) Certains de ces répertoires sont présents à la base (en jaune sur fig.1) :
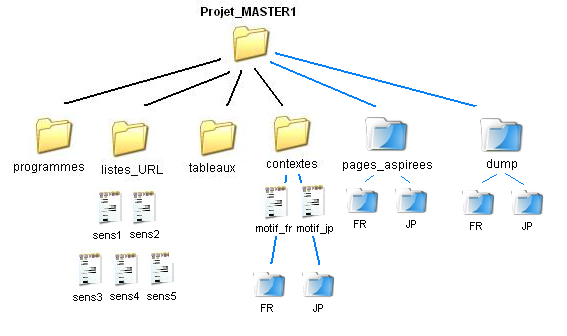 fig.1
|
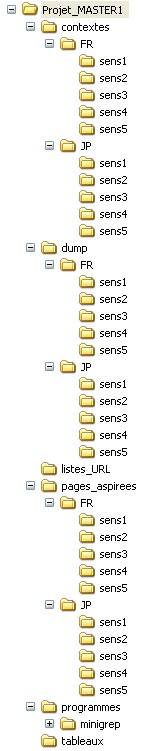 fig.2 |
Comment obtenir un tableau bilingue
Le problème : On veut obtenir en sortie un unique tableau bilingue avec les données en japonais en regard (horizontalement) des données en français. Or les tableaux html sont des successions de lignes (et non de colonnes, ce qui aurait permis de traiter simplement le français puis le japonais). Il est donc nécessaire de pouvoir accéder alternativement à une URL française puis à une URL japonaise pour pouvoir remplir parallèllement les colonnes "français" et "japonais".
La solution (soufflée par SF) exige (1) d'organiser les données en entrée d'une manière un peu particulière et (2) de créer dans le script un compteur qui permettra de discriminer le français du japonais.
(1) Organisation des fichiers d'URL
L'organisation de nos fichiers d'URL ne présente pas la même arborescence interne que les pages aspirées ou que les dump : d'abord séparés par langue puis par sens. En effet, si on veut pouvoir accéder successivement à une URL française puis à une URL japonaise, il faut que celles-ci se trouvent dans les mêmes fichiers. On range ainsi les 50 URL dans 5 fichiers par sens :
Et à l'intérieur de ces fichiers on fait alterner URL françaises et URL japonaises, une ligne sur deux :
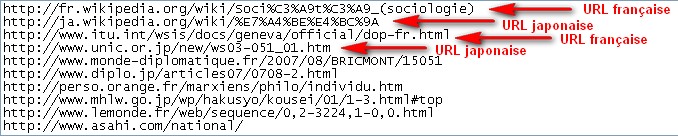
(2) $cptlg : le "compteur langue"
Ainsi, il suffit de mettre en place un compteur ($ctplg dans le script) dans une structure de deux tests if permettant d'exécuter alternativement (en fonction de la valeur de la variable : 1=français, 2=japonais) le traitement des URL françaises et japonaises.J'ai essayé d'expliciter ce fonctionnement par le schéma ci-dessous :
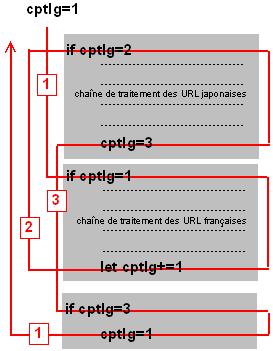
Problèmes spécifiques du japonais
Segmentation des mots
Il n'existe pas de blanc typographique entre les mots en japonais, ce qui pose problème à tout traitement automatique d'un texte en japonais (mais également en chinois, en thai, etc.). Dans le cadre de notre travail, où il s'agit de rechercher automatiquement un motif donné dans un texte, il n'est pas possible de savoir si le motif isolé est bien un mot ou seulement une partie d'un mot.
exemple : on croit avoir trouvé shakai 社会 (société) dans un texte, mais on ne peut pas savoir s'il ne s'agit pas en fait de shakaishugi 社会主義 (socialisme), de shakaiminshuto 社 会民主党 (parti social-démocrate), de shakaigaku 社 会学 (sociologie), etc.
Ce problème --qui pourrait être plus ou moins réglé par un bricolage (lors de la recherche du motif, demander d'exclure du contexte gauche une liste de caractères donnée) ou "manuellement" par vérification visuelle-- est en fait une question centrale et critique dans la recherche en TAL dans de nombreux pays asiatiques, en particulier lorsqu'il s'agit de travailler sur de grands corpus.
Nous avons, pour notre part, laissé ce problème de côté (nous lançons en effet 5 motifs à rechercher simultanément et il y existait un risque qu'un caractère exclu du contexte pour tel motif ne doive pas l'être pour tel autre motif, etc.), estimant qu'il valait mieux produire trop de bruit que de rater des occurrences.
Multiplicité des encodages
Le web japonais présente deux sympathiques caractéristiques : (1) une grande hétérogénéité dans les codages, (2) une sous-utilisation d'Unicode. On se retrouve ainsi à travailler sur des pages codées en shift_JIS, d'autres en euc-jp, d'autres encore en ISO-2022-JP et seulement quelques unes en UTF-8. Or le programme qui nous permet de faire la recherche du mot (v. mini-grep-multilingue ci-dessous) exige qu'on lui spécifie l'encodage utilisé dans le fichier en entrée. Nous avions trouvé un test pour remédier à cela (voir Epaves), que nous n'avons finalement pas intégré à notre script en raison d'un autre problème, également lié aux questions d'encodage (voir le bug n°1 plus bas)
Le mini-grep-multilingue
Le mini-grep-multilingue est un script en perl créé par M. Fleury en cours de projet afin de permettre aux étudiants ayant choisi de travailler avec des langues "rares" (arabe, chinois, bulgare, japonais, etc.) d'appliquer la commande egrep à leurs fichiers présentant des codages "inhabituels" (unicode surtout, mais également shift-jis ou euc-jp pour le japonais p. ex.).
Fonctionnement : Le mini-grep-multilingue cherche un motif donné (stocké dans un fichier texte) dans un fichier texte et produit en sortie un document html qui affiche chaque ligne du fichier comportant le motif recherché.
Syntaxe : le mini-grep-multilingue exige trois arguments (dans l'ordre) :
- l'encodage du fichier d'entrée
- le fichier d'entrée (le fichier texte dans lequel on va cherche le motif)
- un fichier texte contenant le motif (sous la forme : MOTIF=aloha) avec le même encodage que le fichier d'entrée
ex : pl mini-grep-multilingue "UTF-8" unsitejaponais.txt motif-jp.txt
NB : si on ne cherche que le motif "société" sur les pages en français, c'est 5 motifs différents (puisqu'on a une traduction différente pour chaque acception) qu'il nous faut chercher sur les pages en japonais. Nous aurions pu intégrer à notre script un test qui aurait permis de lancer le mini-grep avec un motif différent à chaque changement de fichier d'URL, mais faute de temps nous avons choisi une solution de facilité : chercher les 5 motifs en même temps (on a donc pour certaines pages pas mal de bruit en sortie) :

Bugs
Je signale ici plusieurs autres problèmes non résolus :
(1) Il ne nous a pas été possible de dumper les URL japonaises de notre ordinateur (problème d'encodage), nous avons donc obtenu nos fichiers dumpés d'un autre ordinateur (merci Pierre). Conséquences :- arbo : la suite de répertoires et les fichiers dumpés du japonais sont présents avant l'exécution du script
- script : les commandes mkdir et lynx -dump sont donc superflues pour le traitement du japonais (je les laisse néanmoins en commentaire dans le script)
- encodage : les fichiers dumpés sont tous passés en UTF-8 (conséquence inattendue)
(2) Un problème d'encodage survient lors de l'exécution du mini-grep-multilingue sur certaines pages en français et toutes les pages en japonais (fig.5). Conséquence : certains caractères apparaissent sous forme de code, et ceci de manière non sytématique (ce n'est pas le même caractère qui est à chaque fois mal codé : un caractère normalement affiché à un endroit ne l'est pas ailleurs) : fig.6.
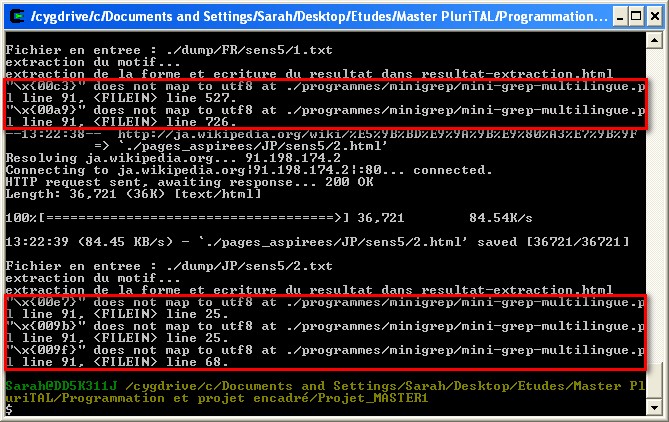
fig.5

fig.6