Ce document (ici l'original)
a été remis en page et modifié à partir de
celui écrit par Jean Marc FEDOU.
Algorithme et Complexité
Notion d'algorithme
-
Algorithme : Un algorithme est une procédure de calcul bien définie
qui prend en entrée une ou plusieurs valeurs et qui délivre
en sortie un résultat. On distingue la notion de calculabilité
(problèmes pour qui il existe un algorithme qui délivre une
valeur numérique) et la décidabilité (problèmes
pour qui il existe un algorithme qui délivre une valeur VRAI ou
FAUX)
-
Exemples d'algorithmes
-
Algorithme d'Euclide (IIIème siécle) pour calculer le pgcd
de deux nombre entiers
-
Multiplication décimale
-
Changements de base d'écriture d'un nombre
-
Algorithmes de tri
-
Recherche d'une chaîne de caractère dans un texte (Logiciels
de traitement de texte).
-
Remarque. Les algorithmes dépendent beaucoup de la forme sous laquelle
la donnée est fournie au programme. Un autre paramètre important
est le choix de la structure utilisée pour manipouler ces données.
On parle en général de structure de données.
-
Test de parité : si le nombre est fournie sous forme décimale,
il suffit de tester la dernière. Si il est décrit sous forme
binaire, c'est encore plus simple.
-
Tableaux, listes chainées, piles, files, arbres sont des structures
de données.
-
Attention, certains problèmes n'admettent pas de solution algorithmique
exacte et utilisable. On utilise dans ce cas des algorithmes heuristiques
qui fournissent des solutions convenables.
Complexités d'un algorithme
La complexité d'un algorithme se mesure essentiellement
en calculant le nombre d'opérations élémentaires pour
traiter une donnée de taille n. Les opérations élémentaires
considérées sont
-
le nombre de comparaisons (algorithmes de recherche)
-
le nombre d'affectations (algorithmes de tris)
-
Le nombre d'opérations (+,*) réalisées par l'algorithme
(calculs sur les matrices ou les polynômes).
Le coût d'un algorithme A pour une donnée D est
le nombre d'opérations élémentaires nécessaires
au traitement de la donnée D et est noté 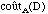
-
Complexité dans le pire des cas
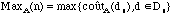
-
Complexité dans le meilleur des cas
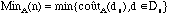
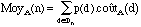
où p(d) est la probabilité d'avoir en entrée la
donnée d parmi toutes les données de taille n.
Si toutes les données sont équiprobables, alors on a,
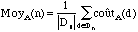
Il est quelquefois nécessaire d'étudier la complexité
en mémoire lorsque l'algorithme requiert de la mémoire supplémentaire
(tableau auxiliaire de même taille que le tableau donné en
entrée par exemple).
Exemple de calcul de complexité d'un algorithme : apparition
d'un nombre dans un tableau.
Soit T un tableau de taille N contenant des nombres entiers de 1 à
k. Soit a un entier entre 1 et k.
La fonction suivante retourne 1 lorsque l'un des éléments
du tableau est égal à a, et 0 sinon.
Trouve:=proc(T,n,a)
local i;
for i from 1 to n do
if T[i]=a then RETURN(i) fi;
od;
RETURN(0);
end;
Cas le pire : N (le tableau ne contient pas a)
Cas le meilleur : 1 (le premier élément du tableau est
a)
Complexité moyenne : Si les nombres entiers de 1 à k
apparaissent de manière équiprobable, on peut montrer que
le cout moyen de l'algorithme est
N
k (1 - (1 - 1/k) ).
De fait les cas où l'on peut explicitement calculer la complexité
en moyenne sont rares. Cette étude est un domaine à part
entière de l'algorithmique que nous aborderons assez peu ici. Toutefois,
il est indispensable, après avoir écrit un algorithme, de
calculer sa complexité dans le pire des cas et dans le meilleur
des cas.
Analyse asymptotique
-
Analyse du temps d'un calcul d'un programme
-
Valeur approchée Le temps de calcul d'un programme dépend
trop de la vitesse de l'ordinateur et du compilateur utilisés.On
peut donc calculer les performances d'un algorithme à facteur multiplicatif
constant. Des programmes de complexités n, 2n ou 3n sont quasiment
équivalents.
-
Rêgle des 90/10 : 90% du temps de calcul d'un programme est réalisé
dans 10% du code. Inutile donc d'essayer de perdre trop de temps à
optimiser les 90% qui ne prennent que 10% du temps. Autant se consacrer
à ce qui est le plus pénalisant.
-
Exemple : comparaisons d'un algorithme A de complexité 100 n et
d'un algorithme B de complexité 2n^2 (cf Aho-Ullman)
-
Notations
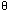 et
O :
et
O :
-
Définitions.
On dit que f=(g)
lorsqu'il
existe deux constantes c1 et c2 positives (f et g sont égalements
supposées à valeurs positives) telles que, pour n assez grand
c1.g(n) < f(n) < c2.g(n).
Remarquons que cette relation est réflexive.
-
On dit que f=O(g) lorsqu'il existe une constante c positive telles
que, pour n assez grand
f(n) < c.g(n),
c'est dire que f est bornée par g à un facteur
multiplicatif près.
Cette relation n'est pas réflexive.
-
Propriétés.
Un polynôme est de l'ordre de son degré. On distingues
les fonctions linéaires (en O(n) ), les fonctions quadratiques (en
O(n^2)) et les fonctions cubiques (en O(n^3)).
Les fonctions d'orde exponentiell sont les fonctions en O(a^n) ou a
>1.
Les fonctions d'ordre logarithmique sont les fonctions en O(log(n))
(Remarquons que peu importe la base du logarithme).
-
Une classe intéressante d'algorithme est en n log(n). Comparaison
de nlog(n) et de n^2.
-
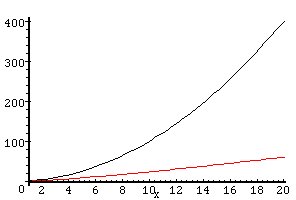
-
Comparaison des asymptotiques classiques.
-
Rappellons que log(n)^i << n^k << a^n (f<<g lorsque limite(g/f)
=0).
-
Fractions rationnelles
-
Factorielle : formule de Stirling
-
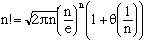
-
Nombres de Fibonacci
-
Calcul de complexité dans les structures de contrôle.
-
Les intructions élémentaires (affectations, comparaisons)
sont et temps constant, soit en O(1).
-
Tests :
O(if A then B else C fi) = O(A)+max(O(B),O(C))
-
Boucles
O(for i from 1 to n do Ai od) = somme(O(Ai))
Lorsque O(Ai) est constant à O(A), on a
O(for i from 1 to n do A od) = nO(A)
-
Cas particuliers : boucles imbriquées
-
O(for i from 1 to n do
for j from 1 to n do A od
od ) = n^2. O(A)
-
Le fait que la borne sup de la boucle intérieure soit i plutot que
n ne change rien :
O(for i from 1 to n
do
for j from 1 to i do A od
od ) = (1+2+...+n). O(A).
Or 1+2+...+n=O(n^2) et on n'a presque rien gagné.