Cours Projet encadré - plurital.org
Projet "La vie multilingue des mots sur le web"
Les différentes étapes d'écriture des scripts
de traitement des pages contenant les mots choisis
(retour page d'accueil du cours)
Rappel : notre parcours de travail... ("en allant vers les scripts d'automatisation")
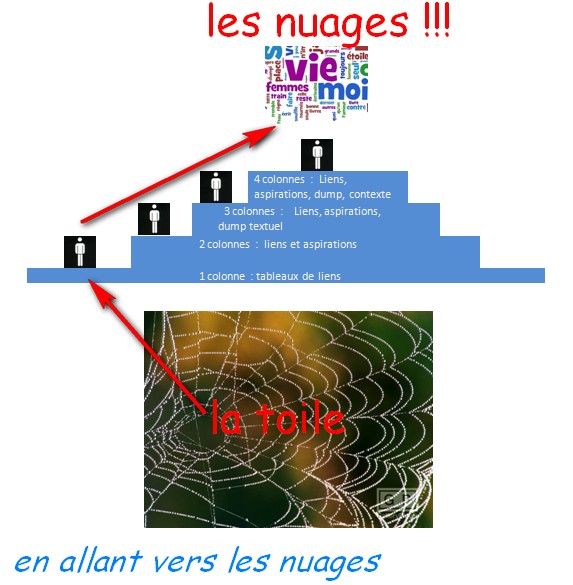 |
| Les marches (les colonnes...) de la gloire !!!! |
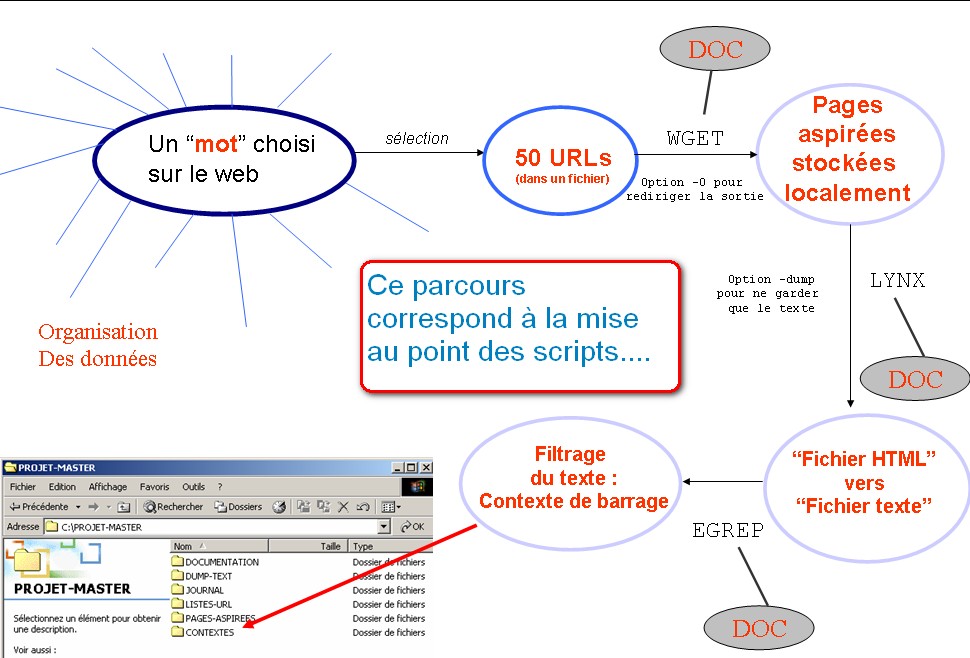
Ci-dessous, la chaîne de traitements à mettre en oeuvre sur une URL :
Figure(s) 0 : Schéma(s) du projet
Objectifs
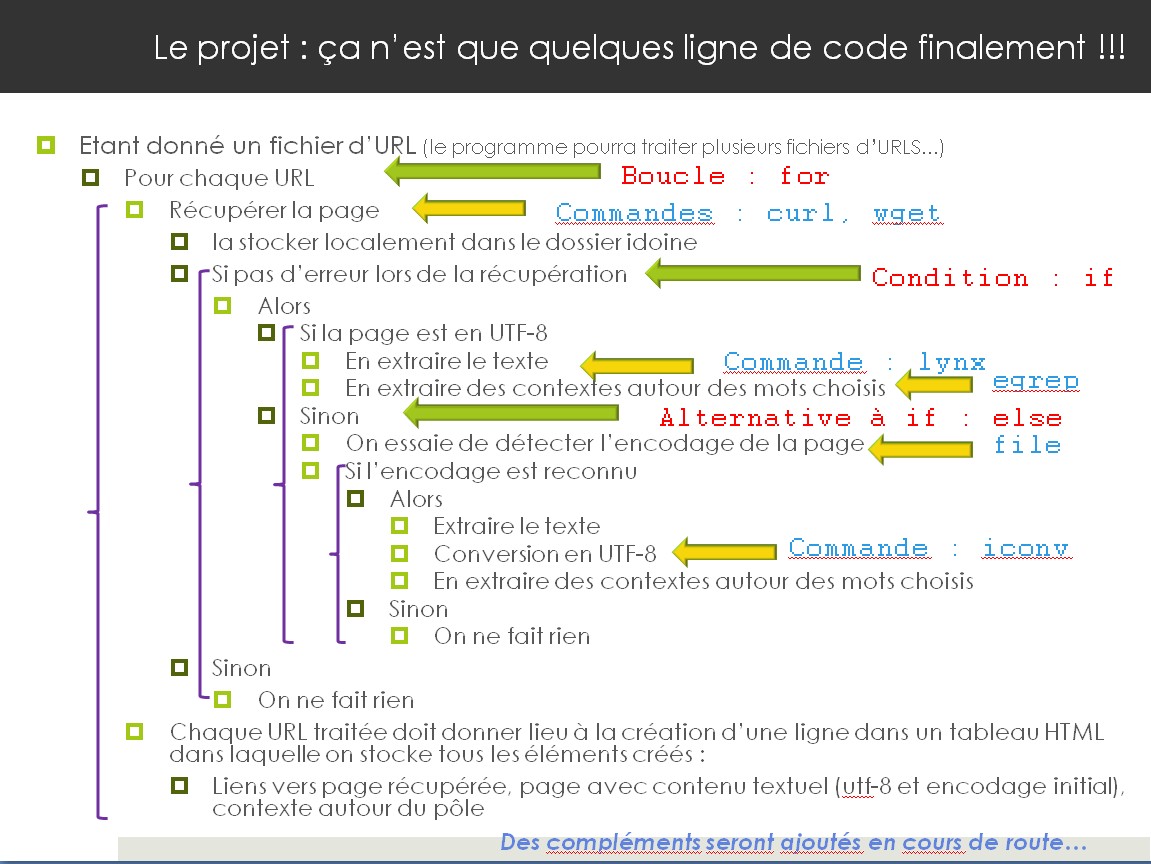
On décrit ci-dessous le parcours à suivre pour mener à bien ce projet. Le code présenté infra (qui sera détaillé en cours et à mettre en oeuvre sur ses propres données) est essentiellement du bash. Le projet vise aussi à construire des scripts en Perl pour arriver à des résultats similaires.
Au final, on devra donc construire 2 séries de script (une en Bash et l'autre en Perl), ces scripts devront réaliser les différentes tâches décrites au fur et à mesure du cours (voir aussi le fil de la progression ci-dessous illustré ci-dessous avec Bash).
Des exemples (solutions) de script Perl seront ajoutés au fil du projet sur cette page pour vous aider à progresser (à l'image des scripts bash déjà disponibles) .
Bonus : on n'hésitera pas à aller regarder très souvent ce travail réalisé par certains de vos prédécesseurs qui ont déjà réalisé ce double parcours Bash/Perl :
http://www.tal.univ-paris3.fr/plurital/travaux-2009-2010/projets-2009-2010-S1/AxelKunMarjo/SITE/perl.html
Une lecture nécessaire pour démarrer : "Unix for the Beginning Mage"
Préambule : préparation du parcours
Répertoire et arborescence de travail
La figure ci-dessous donne un exemple de ce que pourrait être l'arborescence des fichiers constituant le projet. Chaque dossier porte un nom donnant une indication sur le type de fichiers qu'il contiendra :
- le dossier CONTEXTES regroupe les fichiers issus de l'extraction contextuelle par egrep des mots traités dans les fichiers du dossier DUMP-TXT,
- le dossier DUMP-TEXT regroupe les fichiers issus du traitement par lynx sur les pages aspirées du dossier PAGES-ASPIREES,
- le dossier PAGES-ASPIREES regroupe les fichiers issus de l'"aspiration" par wget des urls contenues dans les fichiers situés dans le dossier URLs,
- le dossier PROGRAMMES regroupe l'ensemble des scripts construits pour ce projet,
- le dossier TABLEAUX regroupe l'ensemble des tableaux construits par les scripts, ces tableaux regroupant in fine 4 colonnes : l'url initiale, la page aspirée, le dump textuel, le contexte,
- le dossier URLs regroupe le ou les fichiers contenant les urls à traiter etc.
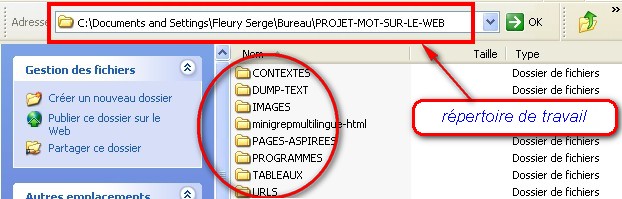
Figure 1 : Arborescence de travail
Premier exercice : création de l'arborescence de travail dans un script
En prenant comme modèle l'arborescence de travail décrite dans la figure ci-dessus, écrire un script qui va construire cette arborescence... (solution)
L'arborescence étant créée, déposez vos fichiers d'urls dans le dossier idoine.
Positionnement de travail dans la fenêtre de commandes
Les scripts utilisés infra ont été construits de telle sorte que leur exécution nécessite que l'on se positionne au préalable à la racine de l'arborescence précédente (le dossier PROJET-MOT-SUR-LE-WEB). Dans l'exemple traité ici, ce dossier se situe sur le bureau du compte utilisateur (sous Windows). La première commande passée ci-dessous (la commande cd...) consiste donc à se déplacer dans le dossier de travail :
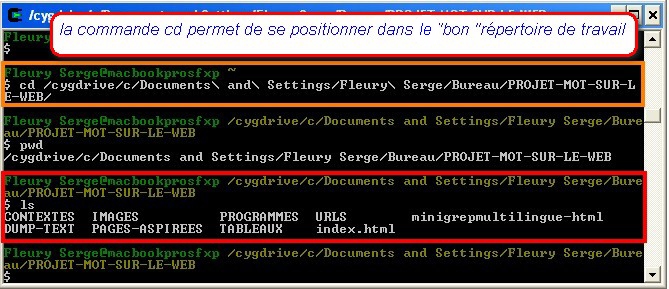
Figure 2 : Positionnement dans le répertoire de travail
PHASE 1 : Construction progressive de la chaîne de traitement
Premier script : créer un tableau de liens
Objectif : Lire un fichier contenant une liste d'URL et produire un fichier HTML contenant un tableau (à 1 colonne) regroupant ces URLs
- 1. le script (solution alternative)

Figure 3 : Premier script, un tableau de liens
Figure 3 bis : Premier script (version alternative), un tableau de liens
- 2. le résultat

Figure 4 : Lancement du premier script
- 3. Mises à jour à faire pour la prochaine séance
- Insérer une nouvelle colonne en y insérant le numéro de l'URL lue
- Modifier le codage HTML pour établir un lien vers l'URL lue
Résultats attendus : - Modifier le script pour traiter 2 (ou plusieurs) fichiers d'URLs et construire en sortie dans le même fichier 2 (ou plusieurs) tableaux
- SOLUTIONS : Script 1 (pour régler les points 1 et 2) ; Script 2 (pour le point 3)
| 1 | http://lien1.com |
| 2 | http://lien2.com |
| 3 | http://lien3.com |
| 4 | http://lien4.com |
- 4. Les outils utilisés :
- (1) Script bash (cf DOC en ligne : Guide avancé d'écriture des scripts Bash, sur le Site de traduction français pour le guide ABS Advanced Bash Scripting Guide)
- (2) Langage HTML : on regardera par exemple cette page sur webplatform.org. On regardera aussi sur ce site : [1] Apprendre le langage HTML ("site réservé aux débutants") et ici : [2] Maîtrisez le langage HTML ("cours pour niveau avancé en HTML") ou encore ici sur le site de l'académie de Créteil.
- ASTUCE : concernant les pbs de codage (Windows versus Unix), on pensera à regarder la commande dos2unix (et unix2dos) soit en consultant directement le man, soit en utilisant votre moteur de recherche habituel...
Second script : créer un tableau de liens avec des liens externes vers les pages visées et des liens internes vers les pages correspondantes aspirées
Objectif : Lire un fichier contenant une liste d'URL, produire un fichier HTML contenant un tableau (à 2 colonnes) regroupant (1) ces URLs et (2) les pages aspirées correspondantes. Etablir les liens vers les 2 ressources (URL, page locale).
- 0. Préambule : la commande wget
On commencera par regarder les transparents du cours (slides 78-79).

Figure 5 : Utilisation de wget...
Dans l'exemple précédent, on utilise wget (puis d'autres commandes) pour récupérer des adresses mails dans une page HTML...
- 1. le script
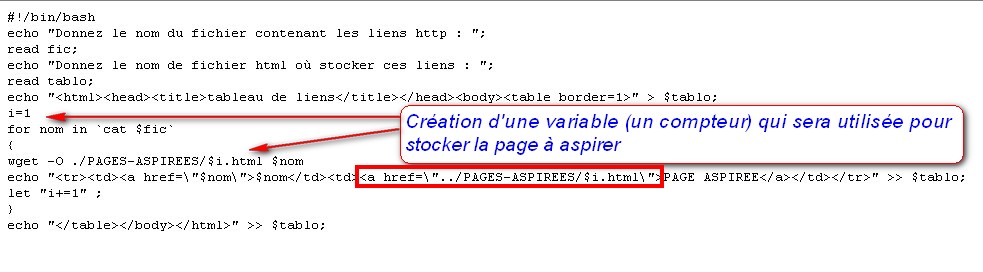
Figure 6 : Second script, un tableau de liens "actifs"
- 2. le résultat
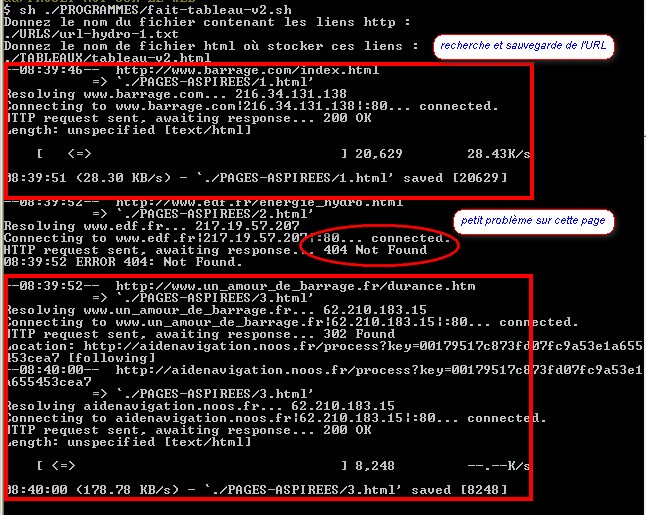
Figure 7 : Exécution du second script
- 3. Les outils utilisés :
- (1) Script bash "amélioré" (cf DOC en ligne : Guide avancé d'écriture des scripts Bash, sur le Site de traduction français pour le guide ABS Advanced Bash Scripting Guide)
- (2) wget : aspirateur en ligne de commandes (cf transparents du cours).
- (3) Langage HTML : on regardera par exemple cette page sur webplatform.org. On regardera aussi sur ce site : [1] Apprendre le langage HTML ("site réservé aux débutants") et ici : [2] Maîtrisez le langage HTML ("cours pour niveau avancé en HTML") ou encore ici sur le site de l'académie de Créteil.
Troisième script : un tableau de liens avec 3 colonnes (URL, fichier aspiré, dump)
Objectif : Lire un
fichier contenant une liste d'URL, produire un fichier HTML
contenant un tableau (à 3 colonnes)
regroupant (1)
ces URLs, (2)
les pages aspirées
correspondantes,(3)
les DUMPS des pages aspirées obtenus avec lynx. Etablir
les liens vers les 3 ressources (URL, page
locale, dump).
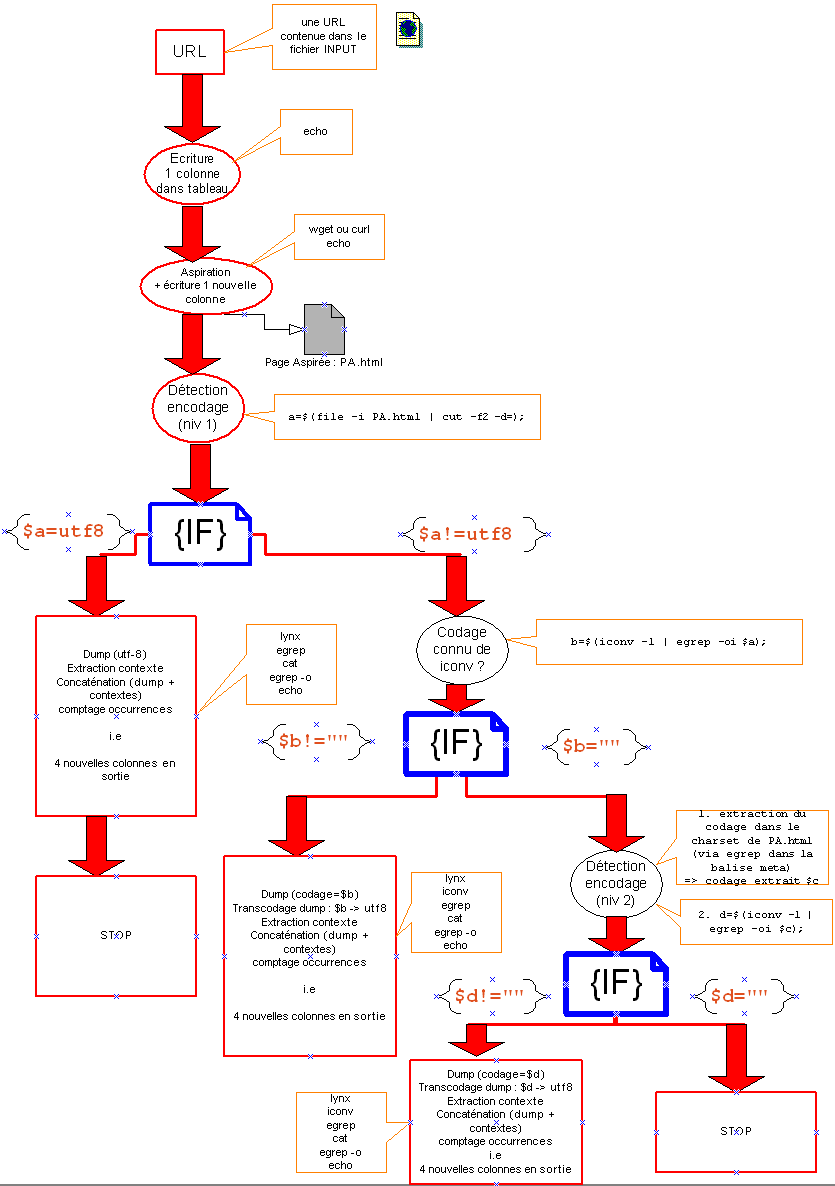
Contrainte supplémentaire : le fichier dump devra être converti en utf8 i.e conversion d'encodage en utf8 si nécessaire
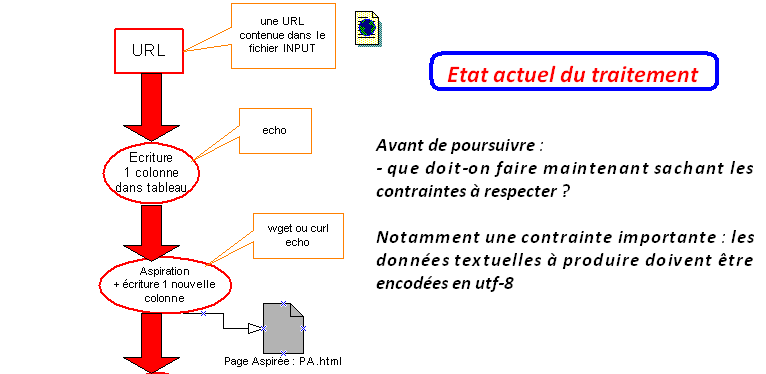
Figure 8 : Etat des traitements avant troisième étape...
-
Le tableau final pourra donc compter à ce stade 2 colonnes pour le fichier dump : une pour le "fichier dumpé" avec l'encodage initial, l'autre pour le "fichier dumpé" avec transcodage en utf8.
- l'option -display_charset de lynx,
- le contenu de l'attribut charset dans la page initiale,
- Problème à résoudre en amont : la détection de l'encodage d'un fichier : possible ou pas ? on ira voir la commande file par exemple... Plusieurs solutions seront évoquées en cours... Voir aussi ce petit programme (readme fourni dans le zip) qui a priori détecte l'encodage d'un fichier TXT...
Plusieurs pistes sont à explorer :
Des solutions ont été mises en oeuvre dans les années passées pour le repérage de l'encodage, ne pas hésiter à aller voir...
Exemple de résultat attendu :
| n° | URL | PAGES ASPIREES | DUMP initial | DUMP utf-8 |
| 1 | http://www.madore.org/~david/weblog/ | 1.html | 1-utf8.txt | |
| 2 | http://tal.univ-paris3.fr/plurital/ | 2.html | 2.txt (iso-8859-1) | 2-utf8.txt |
| 3 | http://tal.univ-paris3.fr/trameur/ | 3.html | 3.txt (ISO-8859-1) | 3-utf8.txt |
- 0. Préambule : la commande lynx
On commencera par regarder les transparents du cours (slides 83-88).
- 1. le script initial et le résultat obtenu
- 2. le script amélioré (intégrant des éléments liés à "la contrainte complémentaire" ...). Les résultats de ce script sont lisibles ici
- 3. Solution alternative :
- Script Perl : solution partiellement équivalente écrite en Perl
- 4. Les outils utilisés :
- (1) Script bash "amélioré" (cf DOC en ligne : Guide avancé d'écriture des scripts Bash, sur le Site de traduction français pour le guide ABS Advanced Bash Scripting Guide)
- (2) wget : "aspirateur" en ligne de commandes (cf transparents du cours).
- (3) lynx : "navigateur" en ligne de commandes (cf transparents du cours).
- (4) Langage HTML : on regardera par exemple cette page sur webplatform.org. On regardera aussi sur ce site : [1] Apprendre le langage HTML ("site réservé aux débutants") et ici : [2] Maîtrisez le langage HTML ("cours pour niveau avancé en HTML") ou encore ici sur le site de l'académie de Créteil.

Figure 8 bis : Troisième script, un tableau à 3 colonnes
Quatrième script : plusieurs tableaux de liens avec 3 colonnes (URL, fichier aspiré, dump)
Objectif : Lire un (ou plusieurs) fichier(s) contenant une liste d'URL, produire un fichier HTML contenant un (ou plusieurs) tableau(x) (à 3 colonnes chacun) regroupant (1) ces URLs, (2) les pages aspirées correspondantes, (3) les DUMPS des pages aspirées obtenus avec lynx. Etablir les liens vers les 3 ressources (URL, page locale, dump)
- 1. le script

Figure 9 : Quatrième script, plusieurs tableaux à 3 colonnes
- 2. le résultat
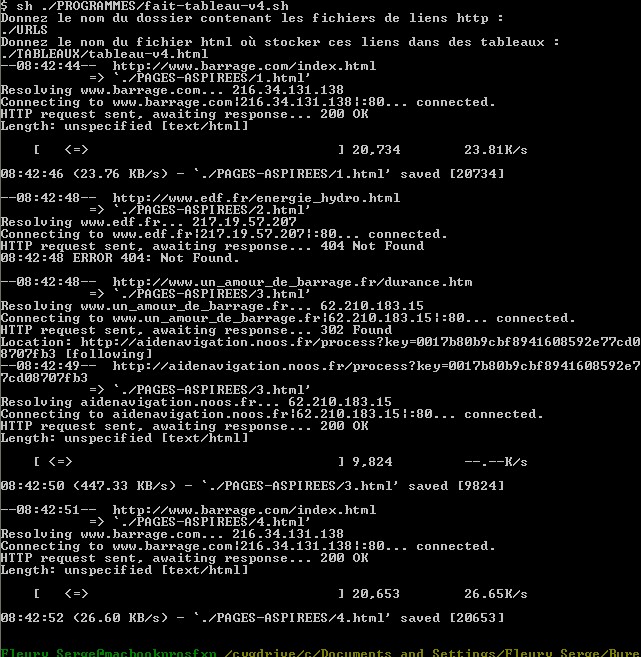
Figure 10 : Exécution du Quatrième script
- 3. Les outils utilisés :
- (1) Script bash "amélioré" (cf DOC en ligne : Guide avancé d'écriture des scripts Bash, sur le Site de traduction français pour le guide ABS Advanced Bash Scripting Guide)
- (2) wget : aspirateur en ligne de commandes (cf transparents du cours).
- (3) lynx : navigateur en ligne de commandes (cf transparents du cours).
- (4) Langage HTML : on regardera par exemple cette page sur webplatform.org. On regardera aussi sur ce site : [1] Apprendre le langage HTML ("site réservé aux débutants") et ici : [2] Maîtrisez le langage HTML ("cours pour niveau avancé en HTML") ou encore ici sur le site de l'académie de Créteil.
Cinquième script : plusieurs tableaux de liens avec 4 colonnes (URL, fichier aspiré, dump, contextes)
Objectif : Lire un (ou plusieurs) fichier(s) contenant une liste d'URL, produire un fichier HTML contenant un (ou plusieurs) tableau(x) (à 4 colonnes chacun) regroupant (1) ces URLs, (2) les pages aspirées correspondantes, (3) les DUMPS des pages aspirées obtenus avec lynx, (4) les contextes obtenus avec egrep. Etablir les liens vers les 4 ressources (URL, page locale, dump, contexte)
- 0. Préambule : la commande egrep
On commencera par regarder les transparents du cours ci-dessus (slides 92-104) ou sur iCampus.
- 1. le script n°1 "mimimal"
- 2. le script n°2 dit "amélioré" intégrant toutes les contraintes attendues...

Figure 11-1 : Cinquième script "minimal", plusieurs tableaux à 4 colonnes

Figure 11-1 : Cinquième script : squelette du script "amélioré"
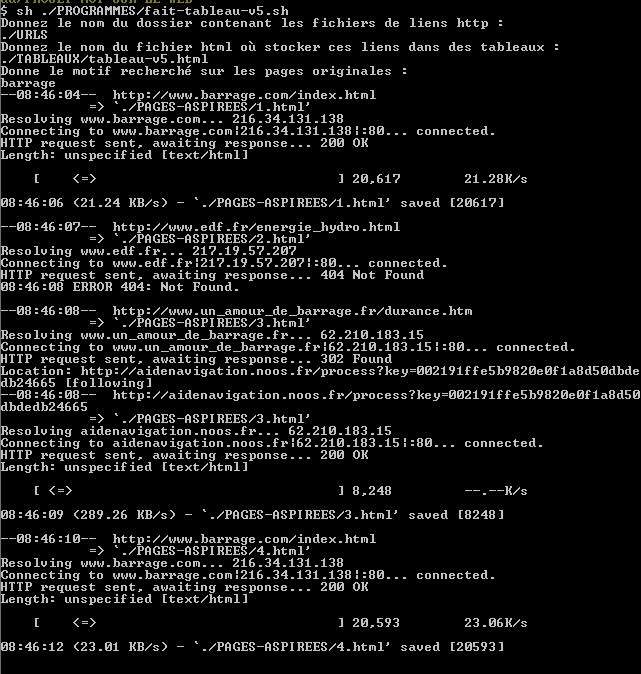
Figure 12 : Exécution du cinquième script
- 5. Les outils utilisés :
- (1) Script bash "amélioré" (cf DOC en ligne : Guide avancé d'écriture des scripts Bash, sur le Site de traduction français pour le guide ABS Advanced Bash Scripting Guide)
- (2) wget : aspirateur en ligne de commandes (cf transparents du cours).
- (3) lynx : navigateur en ligne de commandes (cf transparents du cours).
- (4) egrep : commande unix permettant le filtrage de lignes dans un fichier contenant un motif donné (cf transparents du cours).
- (5) Langage HTML : on regardera par exemple cette page sur webplatform.org. On regardera aussi sur ce site : [1] Apprendre le langage HTML ("site réservé aux débutants") et ici : [2] Maîtrisez le langage HTML ("cours pour niveau avancé en HTML") ou encore ici sur le site de l'académie de Créteil.
Compter
On introduira une colonne supplémentaire dans laquelle on insèrera le nombre d'occurrence de la forme étudiée dans la page (l'URL) associée. On pourra aussi calculer la fréquence totale pour l'ensemble des pages.
Exemple de sorties finales possibles
- Plusieurs fichiers d'URLS traités : une page de tableaux en sortie
- idem ici
- idem ici
- idem ici
Problèmes d'encodage (et solution...)
- Minigrep-multilingue en perl
PHASE 2 : des nuages et des arbres de mots

- Construire des nuages : mode d'emploi
Lectures
- Présentation du projet : transparents du cours.
- Introduction à Unix : transparents du cours.
- Introduction à HTML : on regardera par exemple cette page sur webplatform.org
- Bash : Manuel Bash en ligne.
- Perl : Tutorial Perl . The tutorial is split into twenty-one sections, although you'll probably find it easier if you start from the beginning, especially if you're new to Perl. Lessons zero to ten deal with the basics, and the rest deal with more advanced topics, like servers, perl's guts, and parsing. Lesson 12 seems particularly popular: it deals with perl under Windows. The tutorial should be in line with modern Perl practices, so hopefully you won't see any more bareword filehandles, two-argument open or -w switches.
- Pour aller plus loin à la suite de ce cours :
- (sur le site "Outils Froids") : Pratiquer la veille multilingue en 4 étapes et 15 outils linguistiques .
- Une analyse réalisée à la suite des débats entre les candidats au cours de la campagne présidentielle américaine 2008 : Lexical Analysis of 2008 US Presidential and Vice-Presidential Debates who's the Windbag ?.
Plurital 2011/2012. Cours Projet Encadré. J.M. Daube, S. Fleury, R. Belmouhoub. http://tal.univ-paris3.fr/plurital/