final
L5OTC1
Voici la troisième partie des exercices
I. Exercices sur le « Corpus Prématurés » avec emacs
Attention: Les fichiers ont été convertis en utf-8 pour s'adapter au logiciel Emacs.
Fichier de travail p96.tabQuestions 1-5
1. Rechercher les fiches contenant une interrogation.
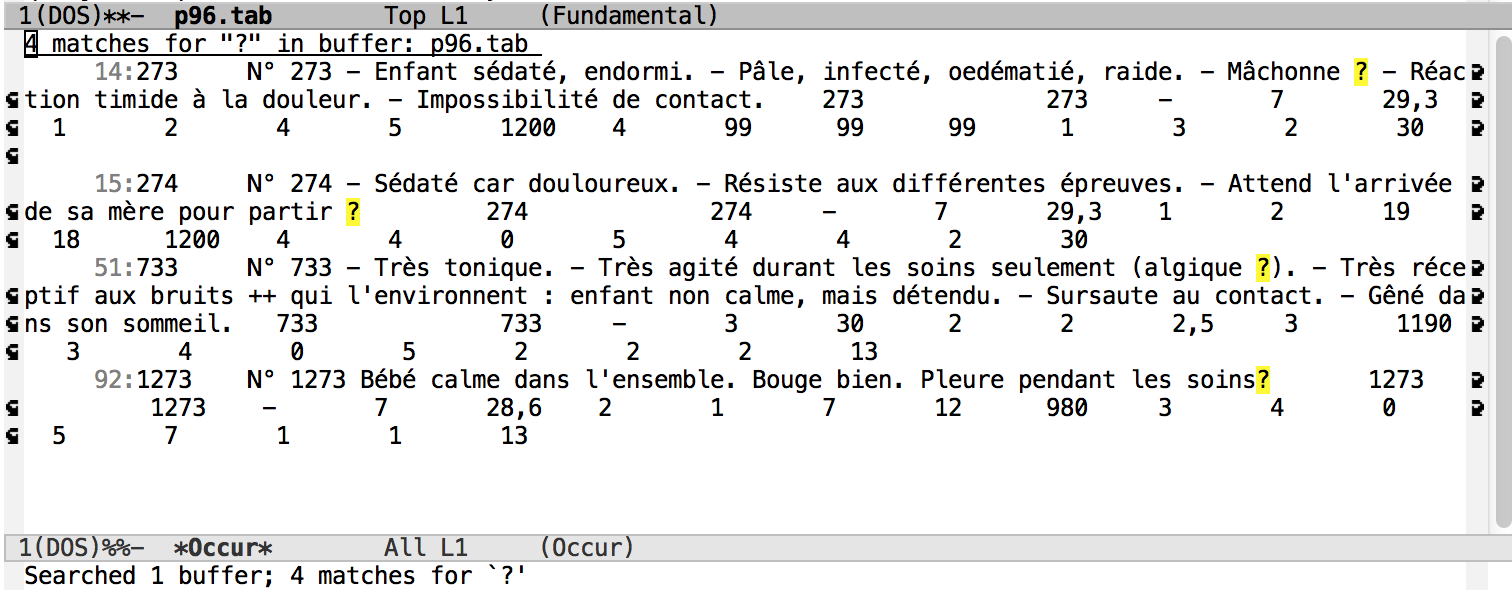
Commentaire: Le motif à utiliser est M-x occur ?. Le point d'interrogation lui-même suffit (il n'est pas interprêté comme regex). Il y a 4 occurrences.
2. Rechercher les fiches correspondant au bébé 12.
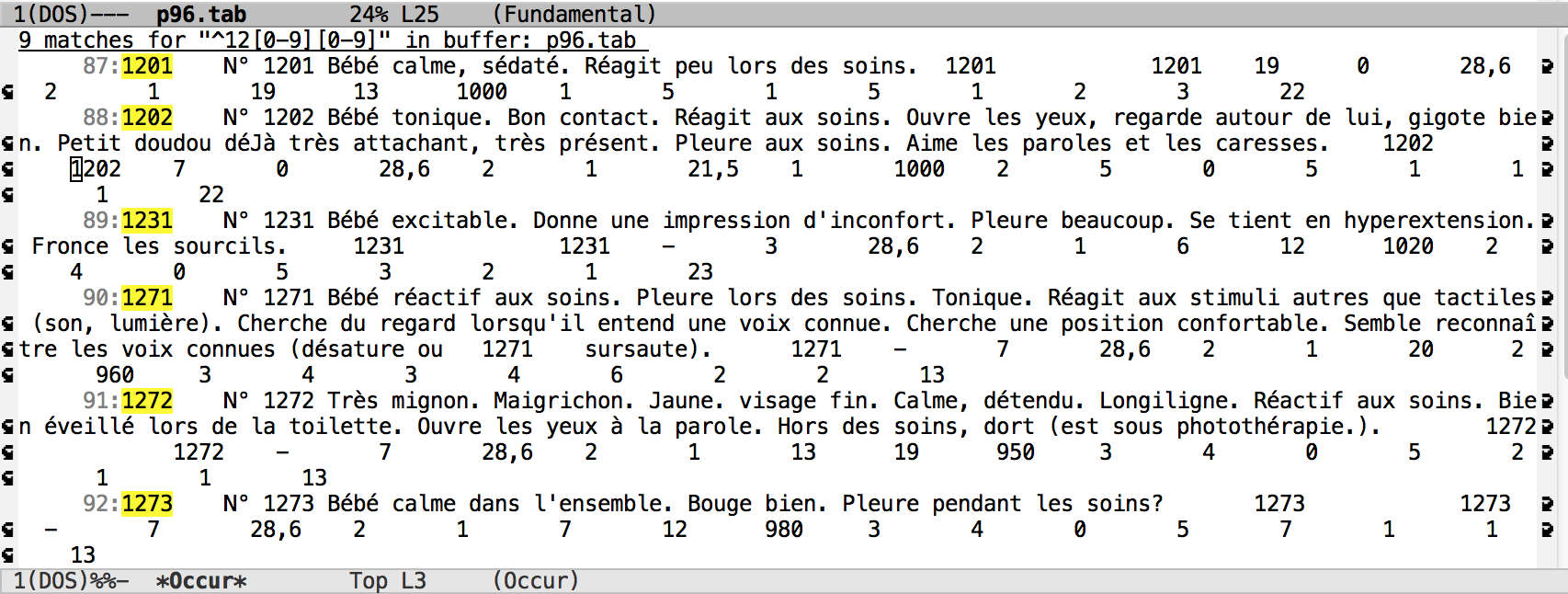
Commentaire: Le motif à utiliser est M-x occur ^12[0-9][0-9]. Ces fiches sont en début de ligne et contiennent 4 ou 5 chiffres. Il y a 9 occurrences.
3. Rechercher les fiches correspondant au bébé 1.
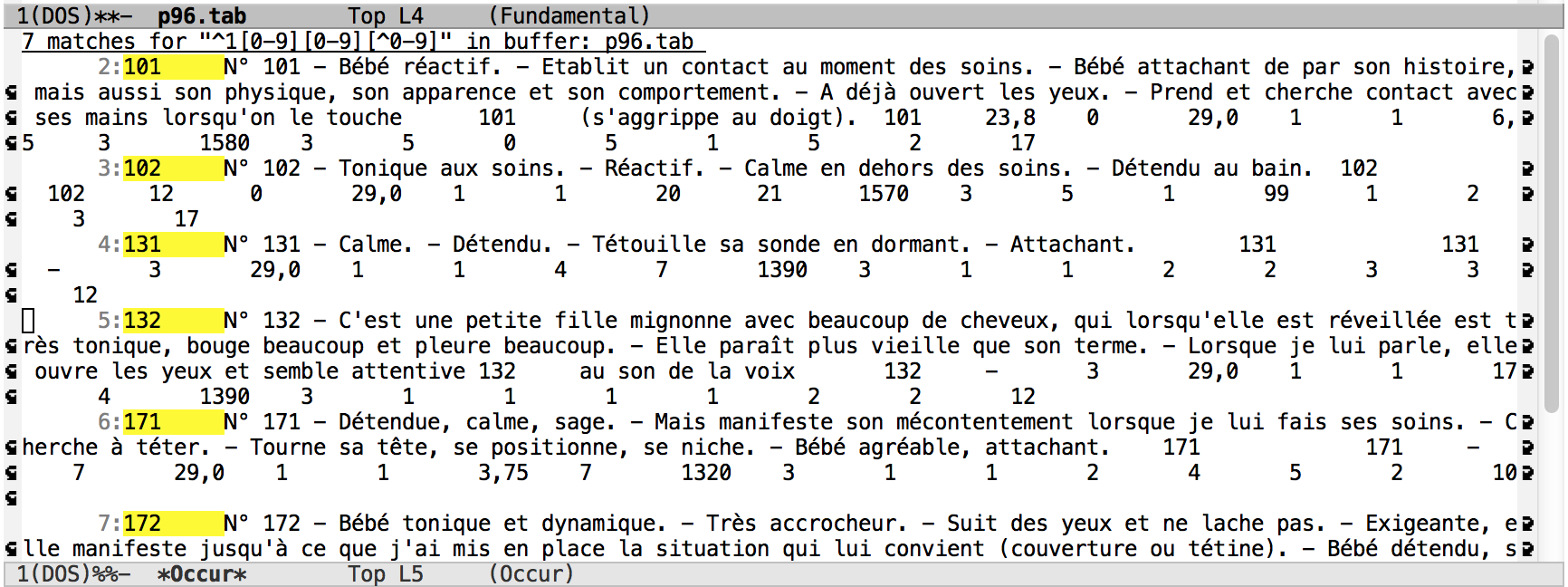
Commentaire: Le motif à utiliser est M-x occur ^1[0-9][0-9][^0-9]. Toutes les fiches concernant le bébé 1 ont 3 chiffres. Alors il ne faut pas que le quatrième soit un numéro entre 0 et 9. Il y a 7 occurrences.
4. Rechercher les fiches pour lesquelles le score médical est de 12.
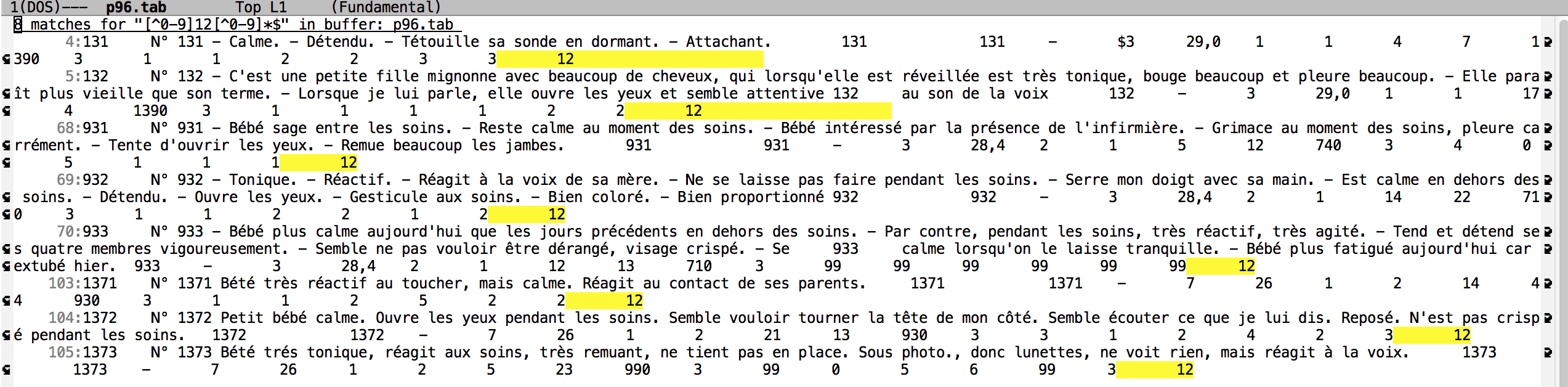
Commentaire: Le motif à utiliser est M-x occur [^0-9]12[^0-9]*$. Les scores médicaux sont en fin de ligne, suivant d'une espace ou non. [^0-9]* est pour éviter les espaces vides en fin de ligne. Il y a 8 occurrences.
5. Faire de même pour un score de 10. Pouvez-vous expliquer le résultat ?

Commentaire: Le motif à utiliser est M-x occur [^0-9]10[^0-9]*$. C'est comme le score de 12 et il n'y pas de résultat particulier. Il y a 3 occurrences.
Fichier de travail p96.bal
Questions 1-7
Attention: Les chevrons sont remplacés par les parenthèses pour raison d'affichage.
1. Rechercher les fiches concernant les bébés 10 à 12.

Commentaire: Le motif à utiliser est M-x occur (BEBE)1[0-2][^0-9]. Le deuxième chiffre peut être entre 0 et 2, et le troisième ne peut pas être un chiffre. Il y a 21 occurrences.
2. Rechercher les fiches concernant les bébés 10 et 12, c'est-à-dire sans 11 et 13.
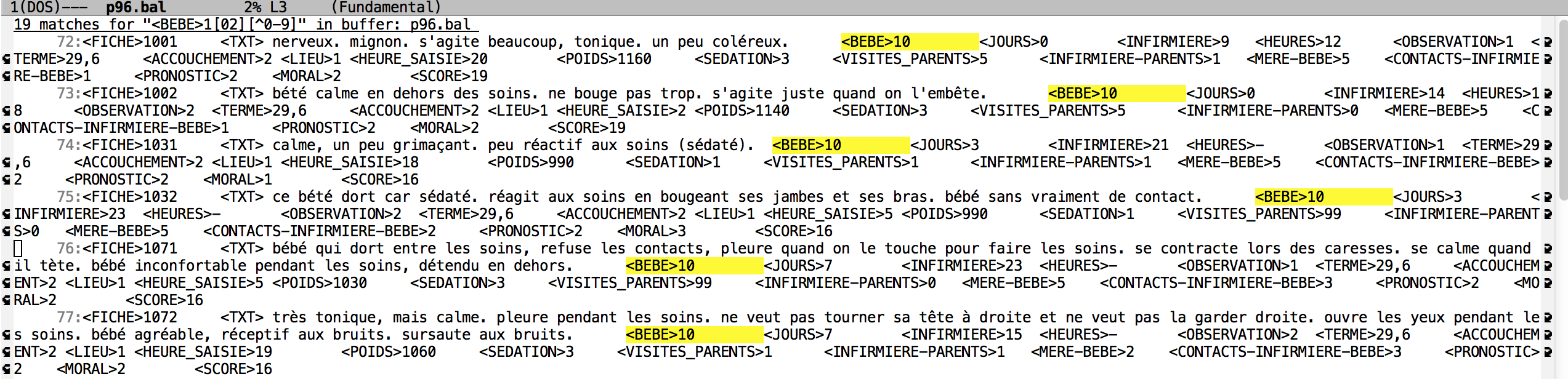
Commentaire: Le motif à utiliser est M-x occur (BEBE)1[02][^0-9]. Le deuxième chiffre est soit 0 soit 2. Il y a 19 occurrences.
3. Rechercher le nombre de bébés de 23, ..., 30 semaines.
Commentaire: Aucun bébé n'a 23 - 30 semaines d'âge.
4. Rechercher les fiches du jour 0 pour lesquels le bébé est né à 28 semaines.

Commentaire: Le motif à utiliser est M-x occur (JOURS)0[^0-9].+(TERME)28. Le jour étant 0 et le terme étant 28, un + peut enchaîner les 2. Il y a 13 occurrences.
5. Rechercher les fiches des bébés nés entre 23 et 29 semaines.

Commentaire: Le motif à utiliser est M-x occur (TERME)2[3-9]. Le numéro doit être entre 23 et 29, alors le deuxième chiffre est compris entre 3 et 9. Il y a 96 occurrences.
6. Rechercher les fiches pour lesquels le bébé à la naissance faisait au moins 1000 grammes.
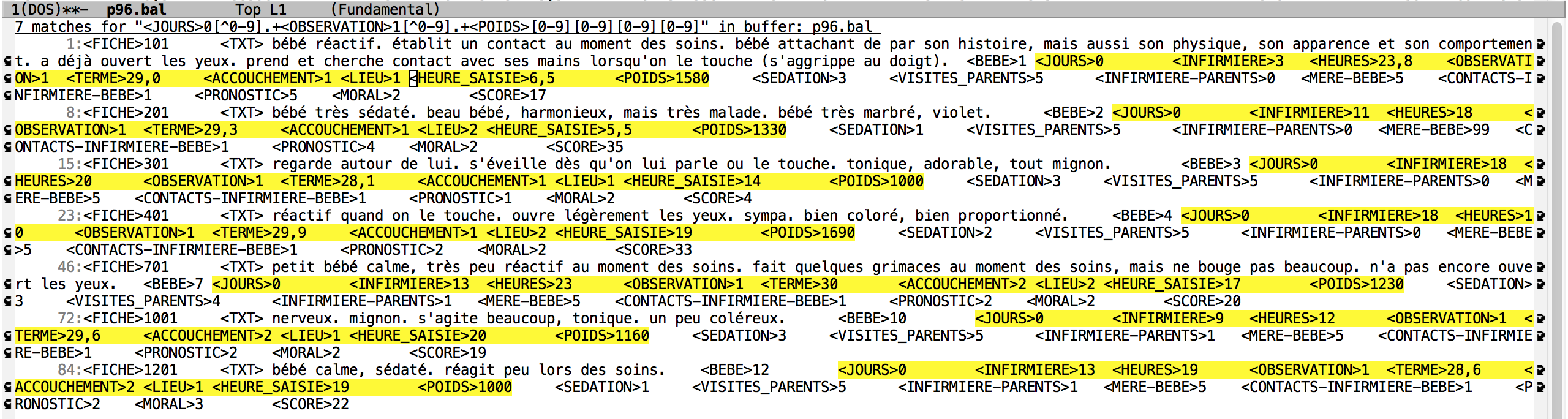
Commentaire: Le motif à utiliser est M-x occur (JOURS)0[^0-9].+(OBSERVATION)1[^0-9].+(POIDS)[1-9][0-9][0-9][0-9]. A la naissance, le jour est 0 et l'observation est 1. Le poids doit avoir 4 chiffres dont le premier n'est pas 0. Il y a 7 occurrences.
7. Rechercher les fiches pour lesquels le bébé à la naissance faisait moins de 1000 grammes.
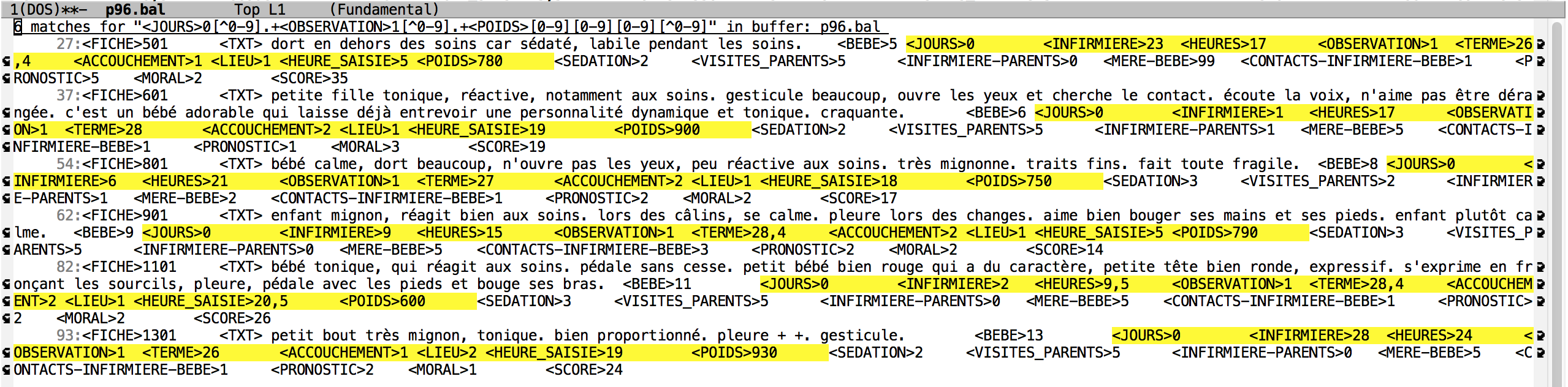
Commentaire: Le motif à utiliser est M-x occur (JOURS)0[^0-9].+(OBSERVATION)1[^0-9].+(POIDS)[0-9][0-9][0-9][^0-9]. Le poids est un numéro à 3 chiffres, alors le quatrième n'est pas 0. Il y a 6 occurrences.
Fichier de travail p96.tab
Questions 1-7
Consigne: Construire des macros sous EMACS pour réaliser les extractions d'informations demandées.
Attention: Les résultats obtenus et les macros utilisées sont dans le fichier txt. Il n'y donc aucun commentaire supplémentaire.
1. Extraire les fiches contenant une interrogation.
2. Extraire les fiches correspondant au bébé 12.
3. Extraire les fiches correspondant au bébé 1.
4. Extraire les fiches pour lesquelles le score médical est de 12.
5. Faire de même pour un score de 10. Pouvez-vous expliquer le résultat ?
6. Quelles fiches vont être extraites si l'on demande les fiches commençant par 13 ? Expliquer ?
7. Extraire les fiches correspondant aux bébés faisant au moins 1000 grammes.
Fichier de travail p96.bal
Questions 1-9
Consigne: Construire des macros sous EMACS pour réaliser les extractions d'informations demandées.
Attention: Les résultats obtenus et les macros utilisées sont dans le fichier txt. Il n'y donc aucun commentaire supplémentaire.
1. Extraire les fiches concernant les bébés 10 à 12.
2. Extraire les fiches concernant les bébés 10 et 12, c'est-à-dire sans 11 et 13.
3. Trouver le nombre de bébés de 23, ..., 30 semaines.
4. Extraire les fiches du jour 0 pour lesquels le bébé est né à 28 semaines.
5. Extraire les fiches des bébés nés entre 23 et 29 semaines.
6. Extraire les fiches pour lesquelles le bébé à la naissance faisait au moins 1000 grammes.
7. Extraire les fiches pour lesquelles le bébé à la naissance faisait moins de 1000 grammes.
8. Extraire les fiches rédigées par les infirmières 12 et 22.
9. Extraire les fiches concernant le bébé 10 et ne correspondant pas au jour 0.
II. Exercices sur le « Corpus Prématurés » avec egrep
Fichier de travail p96.tabQuestions 1-7
Attention: Les fichiers ont été convertis en utf-8 pour s'adapter au logiciel Terminal.
1. Extraire les fiches contenant une interrogation.
Commentaire: Le motif à utiliser est $ egrep "\?" p96-utf8.tab > question1.txt. Il faut mettre un antislash \ avant le point d'interrogation, contrairement au EMACS, pour que cela soit interprêté comme un caractère et non pas une expression régulière. Il y a 4 occurrences.
2. Extraire les fiches correspondant au bébé 12.
Commentaire: Le motif à utiliser est $ egrep "^12[0-9][0-9]" p96-utf8.tab > question2.txt. Idem qu'avec EMACS. Il y a 9 occurrences.
3. Extraire les fiches correspondant au bébé 1.
Commentaire: Le motif à utiliser est $ egrep "^1[0-9][0-9][^0-9]" p96-utf8.tab > question3.txt. Idem qu'avec EMACS. Il y a 7 occurrences.
4. Extraire les fiches pour lesquelles le score médical est de 12.
Commentaire: Le motif à utiliser est $ egrep "[^0-9]12[^0-9]*$" p96-utf8.tab > question4.txt. Idem qu'avec EMACS. Il y a 8 occurrences.
5. Faire de même pour un score de 10.
Commentaire: Le motif à utiliser est $ egrep "[^0-9]10[^0-9]*$" p96-utf8.tab > question5.txt. Idem qu'avec EMACS. Il y a 3 occurrences.
6. Quelles sont les fiches qui vont être extraites si l'on recherche les fiches commençant par 13 ? Expliquer ?
Réponse: Si on utilise le motif $ egrep "^13" p96-utf8.tab, les fichiers correspondant au bébé 1 seront également extraits. Puisque tous les fichiers du bébé 1 ne contient que 3 chiffres, le motif correct est $ egrep "^13[0-9][0-9]" p96-utf8.tab > question6.txt, ce qui nous permet d'obtenir le résultat suivant. Il y a 12 occurrences.
7. Extraire les fiches correspondant aux bébés faisant au moins 1000 grammes.
Commentaire: Le motif à utiliser est $ egrep "([^\A-Za-z.+]){10}[1-9][0-9][0-9][0-9]" p96-utf8.tab > question7.txt. Il faut éviter les fiches qui peuvent aussi avoir un numéro à 4 chiffres. Une des choses qu'on peut noter est que ce dernier suit immédiatement les descriptions, alors exclure les occurrences de lettres avant le numéro est une possibilité pour exclure les fiches à 4 chiffres. Donc il y a 45 occurrences.
Fichier de travail p96.bal
Questions 1-10
Attention: Les chevrons sont remplacés par les parenthèses pour raison d'affichage.
1. Extraire les fiches concernant les bébés 10 à 12.
Commentaire: Le motif à utiliser est $ egrep "(BEBE)1[0-2][^0-9]" p96-utf8.bal > questionbal1.txt. IDEM qu'avec EMACS. Il y a 21 occurrences.
2. Extraire les fiches concernant les bébés 10 et 12, c'est-à-dire sans 11 et 13.
Commentaire: Le motif à utiliser est $ egrep "(BEBE)1[02][^0-9]" p96-utf8.bal > questionbal2.txt. IDEM qu'avec EMACS. Il y a 19 occurrences.
3. Trouver le nombre de bébés de 23, ..., 30 semaines.
Commentaire: Problème de formulation de question.
4. Extraire les fiches du jour 0 pour lesquels le bébé est né à 28 semaines.
Commentaire: Le motif à utiliser est $ egrep "(JOURS)0[^0-9].+(TERME)28" p96-utf8.bal > questionbal4.txt. IDEM qu'avec EMACS. Il y a 13 occurrences.
5. Extraire les fiches des bébés nés entre 23 et 29 semaines.
Commentaire: Le motif à utiliser est $ egrep "(TERME)2[3-9]" p96-utf8.bal > questionbal5.txt. IDEM qu'avec EMACS. Il y a 96 occurrences.
6. Extraire les fiches pour lesquels le bébé à la naissance faisait au moins 1000 grammes.
Commentaire: Le motif à utiliser est $ egrep "(JOURS)0[^0-9].+(OBSERVATION)1[^0-9].+(POIDS)[1-9][0-9][0-9][0-9]" p96-utf8.bal > questionbal6.txt. IDEM qu'avec EMACS. Il y a 7 occurrences.
7. Extraire les fiches pour lesquels le bébé à la naissance faisait moins de 1000 grammes.
Commentaire: Le motif à utiliser est $ egrep "(JOURS)0[^0-9].+(OBSERVATION)1[^0-9].+(POIDS)[0-9][0-9][0-9][^0-9]" p96-utf8.bal > questionbal7.txt. IDEM qu'avec EMACS. Il y a 6 occurrences.
8. Extraire les fiches rédigées par les infirmières 12 et 22.
Commentaire: Le motif à utiliser est $ egrep "(INFIRMIERE)[12]2" p96-utf8.bal > questionbal8.txt. Il y a 15 occurrences.
9. Si l'on veut extraire les fiches rédigées par les infirmières 2, 12 et 22, quel est l'inconvénient de la solution suivante : egrep '(INFIRMIERE)(2|12|22)' p96.bal ?
Commentaire: Le motif $ egrep "(INFIRMIERE)(2|12|22)" p96-utf8.bal > questionbal9.txt qui donne le résultat ci-dessus comprend également les fiches rédigées par les infirmières 21, 23 etc. Ce n'est pas le résultat qu'on cherchait. L'explication peut être le fait que la barre droite | ne délimite pas la frontière des chiffres de ces numéros.
10. Extraire les fiches concernant le bébé 10 et ne correspondant pas au jour 0.
Commentaire: Le motif à utiliser est $ egrep "(BEBE)10.(JOURS)[^0]" p96-utf8.bal > questionbal10.txt. Le numéro suivant BEBE doit être 10 et JOURS tous sauf 0. Ils ne sont séparés que par une espace, alors un . suffit pour connecter les deux. Il y a 8 occurrences.
III. Exercices sur le « Corpus Prématurés » (textutils niveau 0)
Questions 1-21. Déterminer les différentes catégories présentes dans le corpus (leur nombre et leur fréquence)
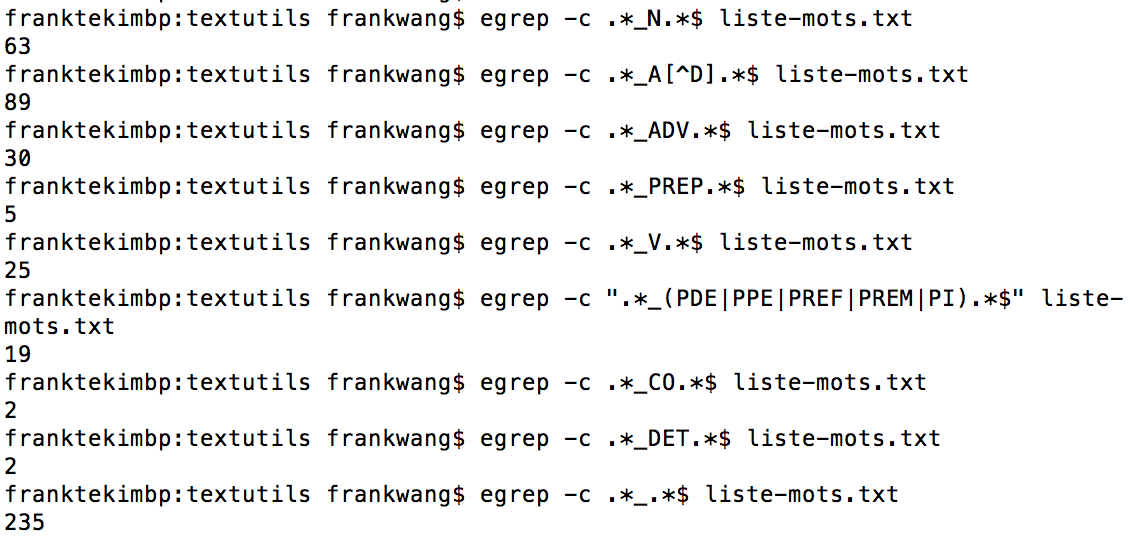
Commentaire: Le corpus contient 235 mots au total, dont 63 noms, 89 adjectifs, 30 adverbes, 5 prépositions, 25 verbes, 19 pronoms, 2 conjonctions et 2 déterminants.
2. Pour chaque catégorie déterminer tous les mots associés.

Réponse: L'image correspond aux étapes pour obtenir les fichiers ci-dessous. Cliquez sur la catégorie pour le fichier en format txt contenant tous les mots de cette catégorie.
NOM ADJECTIF ADVERBE PREPOSITION VERBE PRONOM CONJONCTION DETERMINANT
IV. Exercices sur le « Corpus Prématurés » (niveau 1)
Textes de travail : p96.tab, p96.tagEtape 1 : un index des adjectifs
Essayer de construire un index de tous les adjectifs présents dans le corpus.
Dans une première commande on peut commencer par filtrer les adjectifs dans p96.tag et subsituer dans le résultat les blancs par un dièse et les slash par un underscore pour obtenir des lignes du type :
très_ADV#bon_AMS#contact_NMS#._YPFOR#
! commandes utilisées : egrep, tr
on pourra ensuite projeter les pseudos colonnes et ne garder que les lignes qui contiennent les adjectifs
commandes utilisées : cut, egrep
On concatènera l’ensemble des adjectifs trouvés avant de les trier…
commandes utilisées : cat, sort
Réponse:

Etape 2 : filtrages
Après avoir choisi 5 adjectifs de cet index :
extraire les zones textuelles contenant les adjectifs choisis et le numéro de l'infirmière associée
extraire le premier mot des zones textuelles précédentes, les classer par infirmière, en faire le tri et les compter
Réponse: Les 5 adjectifs choisis sont "actif", "adorable", "agressifs", "algique" et "attentif".

Fin de la troisième partie. Retour en haut de page ou Retour à l'accueil
I. Exercices sur le « Corpus Prématurés » avec emacs
-Fichier de travail p96.tab Question 1-5
-Fichier de travail p96.bal Questions 1-7
-Fichier de travail p96.tab Question 1-7
-Fichier de travail p96.bal Questions 1-9
II. Exercices sur le « Corpus Prématurés » avec egrep
-Fichier de travail p96.tab Question 1-7
-Fichier de travail p96.bal Questions 1-10
III. Exercices sur le « Corpus Prématurés » (textutils niveau 0)
-Questions 1-2
IV. Exercices sur le « Corpus Prématurés » (niveau 1)
-Etape 1 : un index des adjectifs
-Etape 2 : filtrages