BAO 1
BAO 1
Parcourir toute l'arborescence et extraire les contenus textuels de tous les fils (classement des textes extraits par rubrique)
Quel est le but de cette boîte à outil?
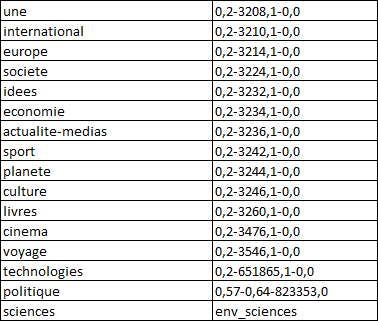
Le Monde produit chaque jour des flux rss (des fichiers xml) pour ses 17 rubriques :
Un flux RSS est un fichier xml qui présente les articles récents de la rubrique.
Un extrait de ce fichier xml :
Dans cette boîte à outil, on souhaite extraire les titres et les descriptions de chaque article présenté dans chaque fichier xml de chaque rubrique choisie.
Comme les fils rss s'organisent en sous-parties de sous-parties de fichiers, on va donc devoir faire un programme qui soit récursif. C'est-à-dire qu'il va ouvrir des dossiers qui seront contenus dans d'autres dossiers qui seront contenus dans d'autres dossiers... On va ensuite devoir trier selon le nom de notre fichier car chaque rubrique a un xml avec des chiffres précis. De plus, on devra faire attention à ne sélectionner que les fichiers xml de ces derniers.
Le Monde produit chaque jour des flux rss (des fichiers xml) pour ses 17 rubriques :
Un flux RSS est un fichier xml qui présente les articles récents de la rubrique.
Un extrait de ce fichier xml :
<?xml version="1.0" encoding="UTF-8"?>
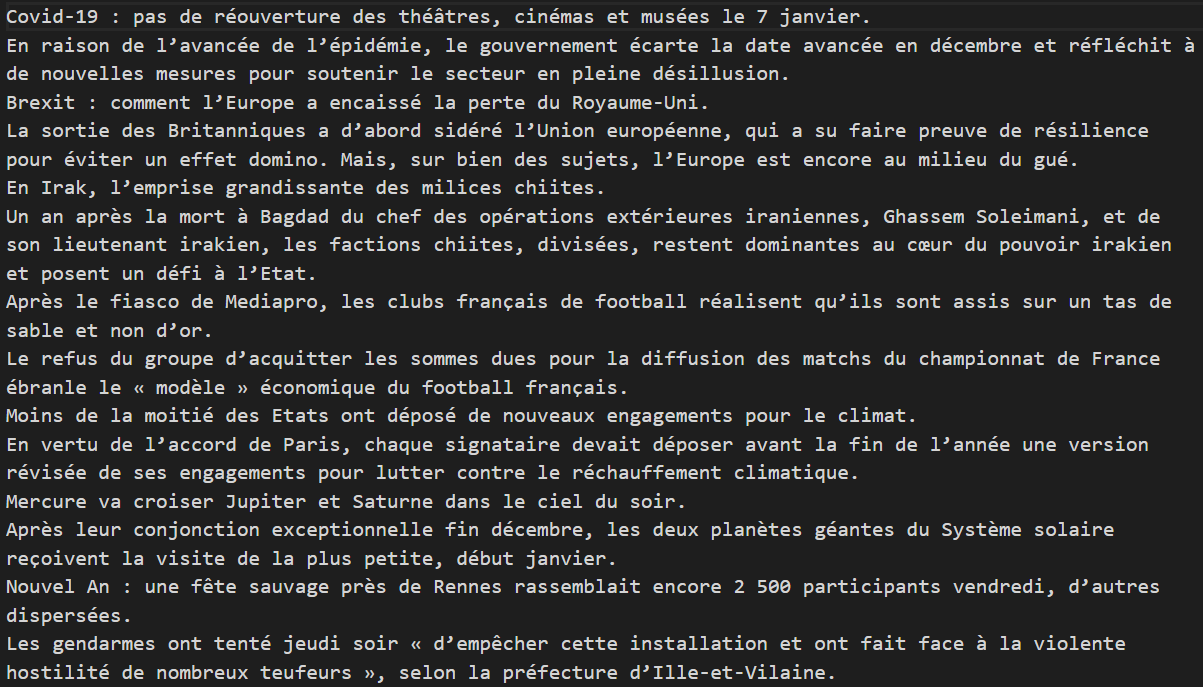
<rss version="2.0" xmlns:atom="http://www.w3.org/2005/Atom" xmlns:media="http://search.yahoo.com/mrss/"><channel><title>Le Monde.fr - Actualités et Infos en France et dans le monde</title><description>Le Monde.fr - 1er site d’information. Les articles du journal et toute l’actualité en continu : International, France, Société, Economie, Culture, Environnement, Blogs ...</description><copyright>Le Monde - L’utilisation des flux RSS du Monde.fr est réservée à un usage strictement personnel, non professionnel et non collectif. Toute autre exploitation doit faire l’objet d’une autorisation et donner lieu au versement d’une rémunération. Contact : droitsdauteur@lemonde.fr</copyright><link>https://www.lemonde.fr/rss/une.xml</link><pubDate>Fri, 01 Jan 2021 17:56:34 +0000</pubDate><language>fr</language><atom:link href="https://www.lemonde.fr/rss/une.xml" rel="self" type="application/rss+xml"/><item><title><![CDATA[Covid-19 : pas de réouverture des théâtres, cinémas et musées le 7 janvier]]></title><pubDate>Fri, 01 Jan 2021 16:48:30 +0100</pubDate><description><![CDATA[En raison de l’avancée de l’épidémie, le gouvernement écarte la date avancée en décembre et réfléchit à de nouvelles mesures pour soutenir le secteur en pleine désillusion.]]></description><guid isPermaLink="true">https://www.lemonde.fr/culture/article/2021/01/01/culture-pas-de-reouverture-des-theatres-cinemas-et-musees-le-7-janvier_6064985_3246.html</guid><link>https://www.lemonde.fr/culture/article/2021/01/01/culture-pas-de-reouverture-des-theatres-cinemas-et-musees-le-7-janvier_6064985_3246.html</link><media:content url="https://img.lemde.fr/2021/01/01/449/0/5385/2692/644/322/60/0/722db00_429528356-260088.jpg" width="644" height="322"><media:description type="plain">La façade du cinéma parisien le Grand Rex, le 15 décembre 2020.</media:description><media:credit scheme="urn:ebu">ALAIN JOCARD / AFP</media:credit></media:content></item></channel></rss>
Dans cette boîte à outil, on souhaite extraire les titres et les descriptions de chaque article présenté dans chaque fichier xml de chaque rubrique choisie.
Comme les fils rss s'organisent en sous-parties de sous-parties de fichiers, on va donc devoir faire un programme qui soit récursif. C'est-à-dire qu'il va ouvrir des dossiers qui seront contenus dans d'autres dossiers qui seront contenus dans d'autres dossiers... On va ensuite devoir trier selon le nom de notre fichier car chaque rubrique a un xml avec des chiffres précis. De plus, on devra faire attention à ne sélectionner que les fichiers xml de ces derniers.
Perl
Le code ci-dessous est commenté. La version téléchargeable : ici
#/usr/bin/perl
# utilisation : perl bao1.pl ./2021 3208
# Il prend en arguments 2 éléments : (1) le nom de l'arborescence 2021 contenant les fils RSS de l'année 2021, (2) le nom de la rubrique à traiter (ici 3208 pour la rubrique A la une)
#-----------------------------------------------------------
use utf8;
use strict;
binmode(STDOUT, ":encoding(UTF-8)");
#-----------------------------------------------------------
if ($#ARGV != 1) {print "Il manque un argument à votre programme....\n";exit;} # on s'assure qu'il ne manque aucun argument
my $rep="$ARGV[0]"; #le répertoire 2021 sera le premier argument
my $RUBRIQUE="$ARGV[1]"; #la rubrique choisie est le deuxième argument
$rep=~ s/[\/]$//;# on s'assure que le nom du répertoire ne se termine pas par un "/"
#ouverture des fichiers#
open my $output, ">:encoding(UTF-8)","corpus-titre-description.txt"; #on créé un fichier txt qui recevra les titres et descriptions
open my $output2, ">:encoding(UTF-8)","corpus-titre-description.xml"; #on créé un fichier xml qui recevra les titres et descriptions
print $output2 "<?xml version=\"1.0\" encoding=\"utf-8\"?>\n<corpus>\n"; #on écrit le début de notre fichier xml final
#----------------------------------------
&parcoursarborescencefichiers($rep); #on appelle notre fonction de récursivité
#----------------------------------------
print $output2 "</corpus>\n"; #on écrit la fin de notre fichier xml final
#fermeture des fichiers#
close $output;
close $output2;
#----------------------------------------------
exit;
#----------------------------------------------
#définition de la fonction#
sub parcoursarborescencefichiers {
my $path = shift(@_); #on récupère le path, ici 2021 et on le supprime de la liste
opendir(DIR, $path) or die "can't open $path: $!\n"; #on ouvre le dossier
my @files = readdir(DIR); #on le lit
closedir(DIR); #on le ferme
foreach my $file (@files) { #pour chaque fichier
next if $file =~ /^\.\.?$/; #on skip si le path du fichier est ../
$file = $path."/".$file; #on ajoute le path récupéré au fichier
if (-d $file) { #si le fichier est en fait un répertoire
print "On entre dans le REPERTOIRE : $file \n"; #on écrit dans le terminal pour qu'on voit ce qu'il se passe
&parcoursarborescencefichiers($file); #on fait une récursivité
print "On sort du REPERTOIRE : $file \n"; #on écrit dans le terminal pour qu'on voit ce qu'il se passe
}
if (-f $file) { #si le fichier est vraiment un fichier
if ($file =~ /$RUBRIQUE.+\.xml$/) { #si le fichier est la rubrique qui m'intéresse
print "Traitement du fichier $file \n"; #on écrit dans le terminal pour qu'on voit ce qu'il se passe
open my $input, "<:encoding(UTF-8)",$file; #on ouvre le fichier
$/=undef; # par défaut cette variable contient \n donc on supprime le saut de ligne
my $ligne=<$input> ; #on sauvegarde les lignes du fichier dans une variable
close($input); #on ferme le fichier
while ($ligne=~/<item><title>(.+?)<\/title>.+?<description>(.+?)<\/description>/gs) { #on va chercher cette expression jusqu'à ce qu'il n'y en ait plus dans le fichier (grâce à g), s sert à transformer les . en potentiel caractère non imprimable donc on ne peut rater aucun item avec cette expression
#on va sauvegarder le texte contenu entre ()
my $titre=&nettoyage($1); #on appelle la fonction nettoyage sur la première "variable" sauvegardé dans l'expression matchée
my $description=&nettoyage($2); #on appelle la fonction nettoyage sur la deuxième "variable" sauvegardé dans l'expression matchée
print $output "$titre \n"; #on écrit dans le fichier txt final le titre de l'article
print $output "$description \n"; #on écrit dans le fichier txt final la description de l'article
print $output2 "<item><titre>$titre</titre><description>$description</description></item>\n"; #on écrit dans le fichier xml final le titre et la description de l'article
}
}
}
}
}
#----------------------------------------------
#définition de la fonction qui va permettre de ne récupérer que le texte des titres et des descriptions#
sub nettoyage {
my $texte=shift @_; #on récupère la valeur et on la supprime de la liste
$texte=~s/(^<!\[CDATA\[)|(\]\]>$)//g; #on va supprimer les éléments qui ne sont pas du véritable texte
$texte.=".";
$texte=~s/\.+$/\./;
return $texte; #on retourne la valeur textuelle finale
}
#----------------------------------------------
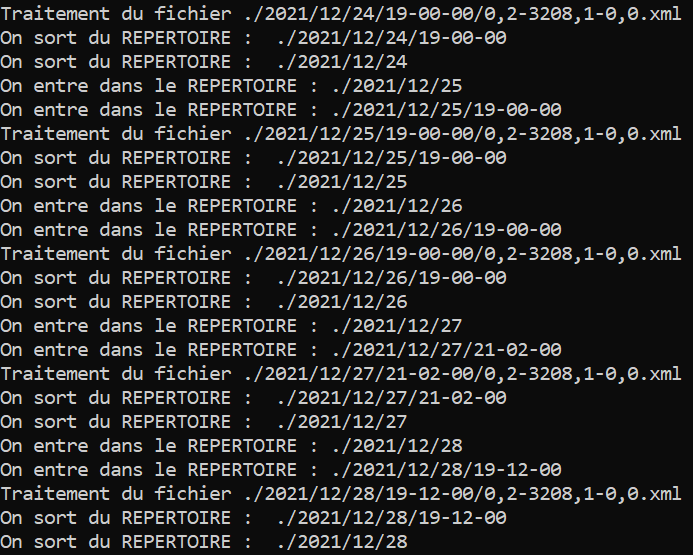
Lorsqu'on lance le programme voici ce qui s'affiche dans le terminal :
Voici les deux fichiers par rubrique en output : - rubrique à la une : fichier txt et fichier xml.
- rubrique livres : fichier txt et fichier xml.
- rubrique cinema : fichier txt et fichier xml.
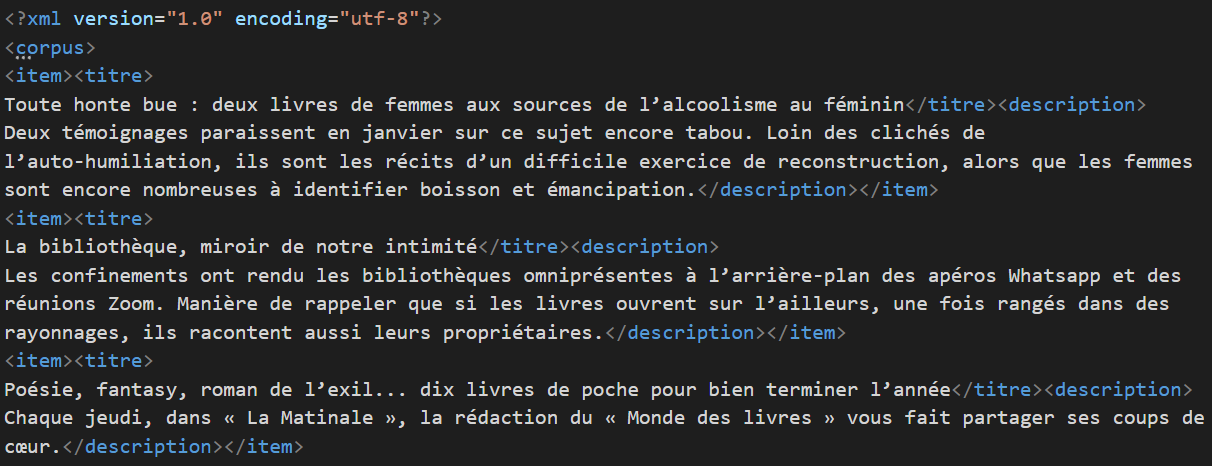
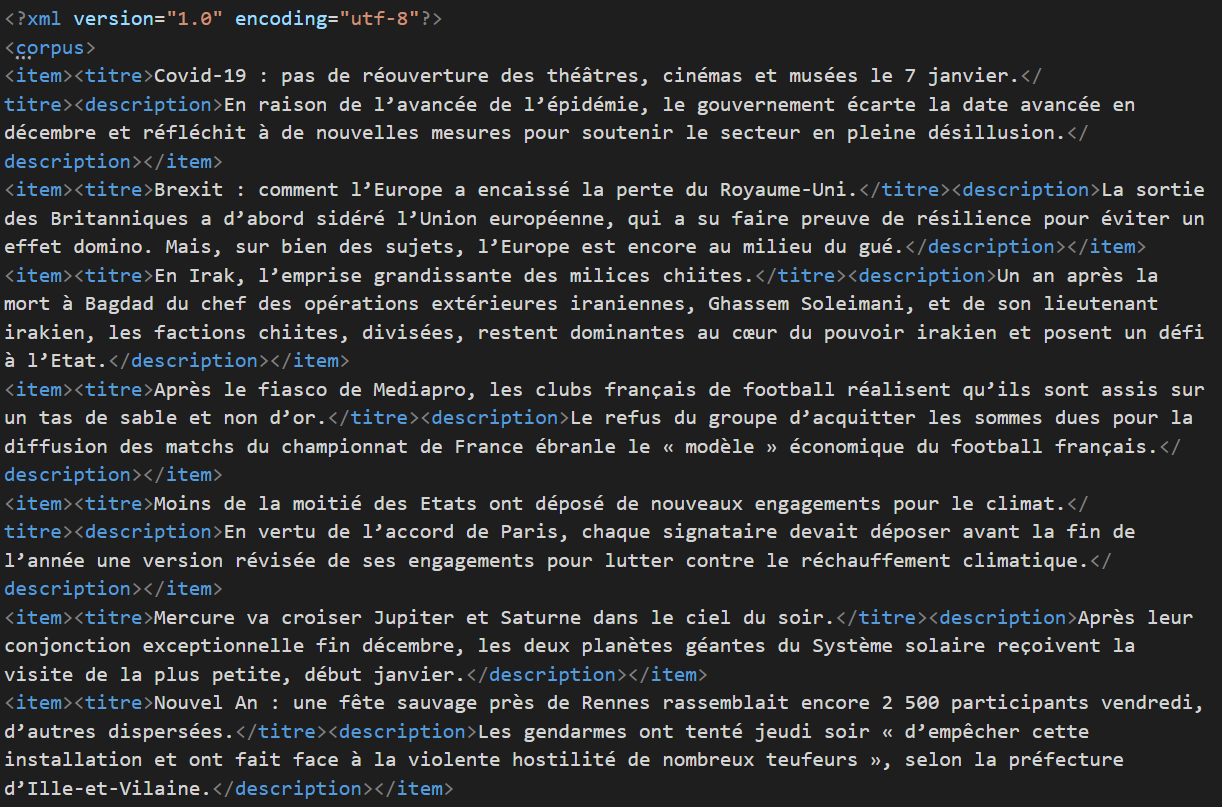
Un aperçu des résultats txt et xml :
txt :
xml :
Python
Le code ci-dessous est commenté. La version téléchargeable : ici et ici
#!/usr/bin/python3
import sys
from pathlib import Path
from bao1bis import extractionsur1fil
#utilisation : python3 bao1.py ./2021 corpus-titre-descriptionbao1py.xml corpus-titre-descriptionbao1py 3208
def parcours(dossier:Path,fichier_xml,fichier_txt,rubrique,doublons): #fonction de récursivité
print(f"on traite {dossier}") #on affiche dans le terminal où on en est dans le traitement
for fichier in sorted(dossier.iterdir()):
if fichier.is_dir(): #si c'est pas un vrai fichier, on appelle la récursivité
parcours(fichier,fichier_xml,fichier_txt,rubrique,doublons)
if fichier.is_file() and fichier.name.endswith(".xml") and rubrique in fichier.name: #si le fichier est un véritable fichier, que c'est un fichier xml et qu'il est de la rubrique qu'on cherche
extractionsur1fil(fichier,fichier_xml,fichier_txt,doublons) #on applique l'extracteur de titre/description
def main():
dossier=Path(sys.argv[1]) #on récupère le path du dossier
rubrique=sys.argv[4] #on récupère la rubrique
doublons=[] #on met les titres et les descriptions dans cette liste pour éviter les doublons
with open (sys.argv[2],'w') as fichier_xml: #on ouvre notre fichier xml final
with open (sys.argv[3],'w') as fichier_txt: #on ouvre notre fichier txt final
fichier_xml.write("<?xml version=\"1.0\" encoding=\"utf-8\"?>\n<corpus>\n") #on écrit le début de notre fichier xml
parcours(dossier,fichier_xml,fichier_txt,rubrique,doublons) #on appelle la fonction de récursivité
fichier_xml.write("</corpus>") #on écrit la fin de notre fichier xml
if __name__=="__main__": #manière un peu spéciale pour lancer le programme
main() #on appelle la fonction main
#######################################################
# 2ème programme #
#######################################################
#!/usr/bin/python3
import sys
import re
regex_item = re.compile("<item><title>(.*?)<\/title>.*?<description>(.*?)<\/description>") #avec () on récupère les titres et les descriptions
def nettoyage(texte): #fonction pour ne garder que le véritable texte
texte_net = re.sub("<!\[CDATA\[(.*?)\]\]>","\\1",texte)
texte_net = re.sub(" ","",texte_net)
texte_net = re.sub("[a-z] ","",texte_net)
texte_net = re.sub("&","E",texte_net)
texte_net = re.sub("&","E",texte_net)
return texte_net
def extractionsur1fil(dossier,output_xml, output_txt,doublons): #fonction qui écrit les titres et les descriptions dans un fichier final
with open(dossier, "r") as input_rss: #on ouvre le fichier à traiter
texte = "".join(input_rss.readlines()) #on garde toutes les lignes dans une variable
#pour chaque élément qui dans le texte correspond à la regex définie (regex_item)
for m in re.finditer(regex_item,texte): #on cherche les titres et descriptions
if m.group(1) not in doublons: #s'il n'est pas déjà dans la liste des doublons
doublons.append(m.group(1)) #on l'ajoute à la liste
titre_net = nettoyage(m.group(1)) #on appelle la fonction nettoyage sur le titre qui est le 1er argument gardé par la regex
description_net = nettoyage(m.group(2)) #on appelle la fonction nettoyage sur la description qui est le 2eme argument gardé par la regex
output_txt.write(f"{titre_net}\n{description_net}\n") #on écrit le titre et sa description dans le fichier txt final
output_xml.write(f"<item><titre>\n{titre_net}</titre><description>\n{description_net}</description></item>\n") #on écrit le titre et sa description dans le fichier xml final
if __name__=="__main__":
dossier=sys.argv[1] #chemin du dossier
fichier_xml=sys.argv[2] #fichier xml final
fichier_txt=sys.argv[3] #fichier txt final
extractionsur1fil(dossier, fichier_xml, fichier_txt,doublons) #on appelle la fonction d'extraction des titres et descriptions
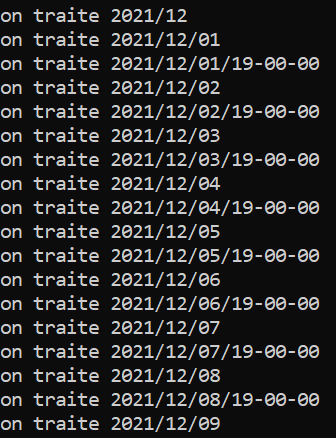
Lorsqu'on lance le programme voici ce qui s'affiche dans le terminal :
Voici les deux fichiers par rubrique en output : - rubrique à la une : fichier txt et fichier xml.
- rubrique livres : fichier txt et fichier xml.
- rubrique cinema : fichier txt et fichier xml.
Un aperçu des résultats txt et xml :
txt :
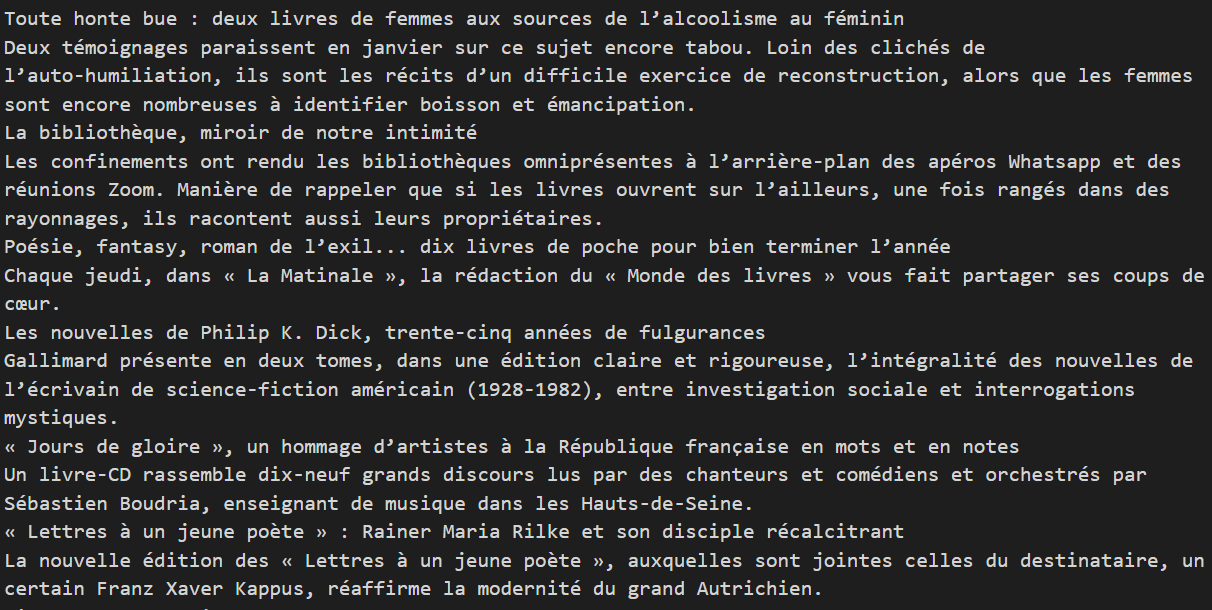
xml :