BAO1 "extraction du texte"
L'objectif de la BAO1 est l'extraction des contenus textuels consernant les titres et les descriptions des articles dans une arborescence de fils RSS du journal Le Monde. Les fils ont été reccueillis une fois par jour à 19h pendant l'année 2021.
Script Perl
Bao1_Jiaxin_He.pl
Voici le détail :
On nettoie le text et extrait les cotenus des titres et des descriptions. Pour éviter d'extraire les doublons, on a ajouté un dictionnaire dans ce script par rapport qu'on avait fait en cours.
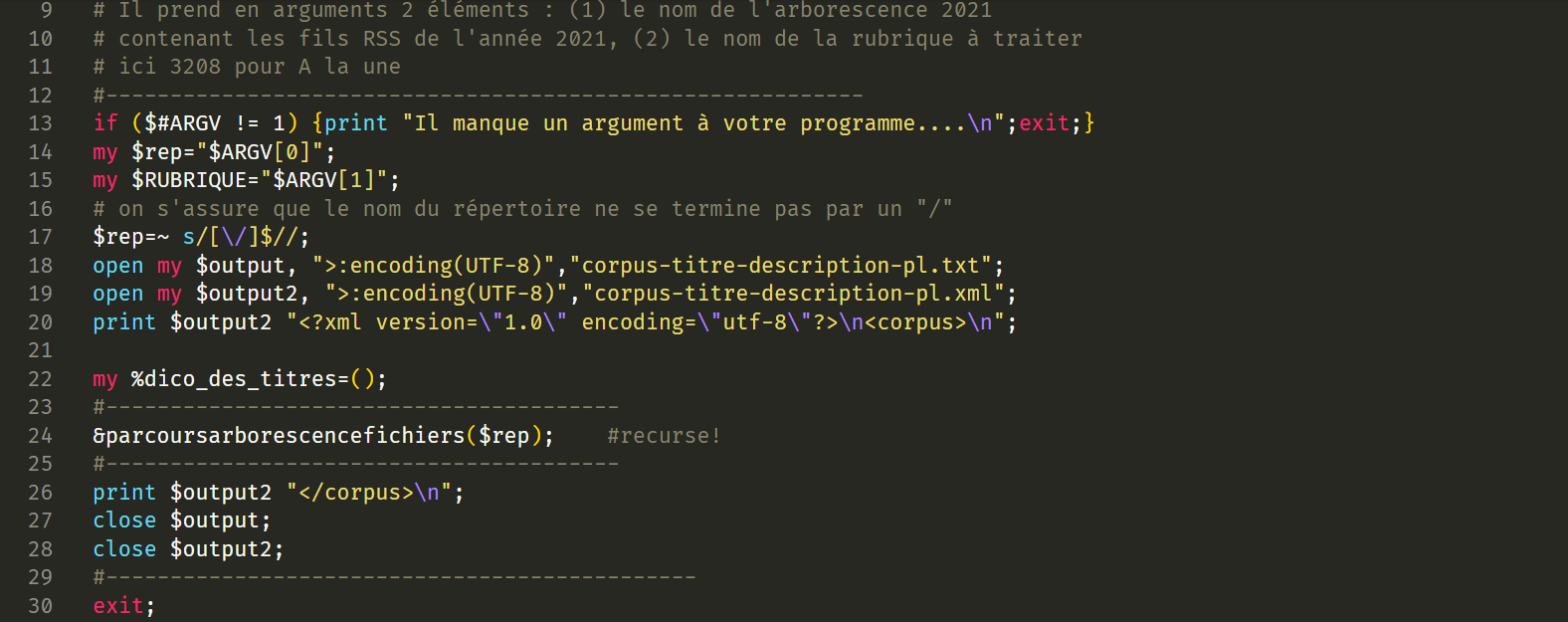
Commande Perl

Script Python
Bao1_Jiaxin_He.py
Voici le détail :
On fait le même traitement que perl pour supprimer prendre les phrases deux fois et on programme une fonction pour parcourir les fichiers à traiter plus tard.
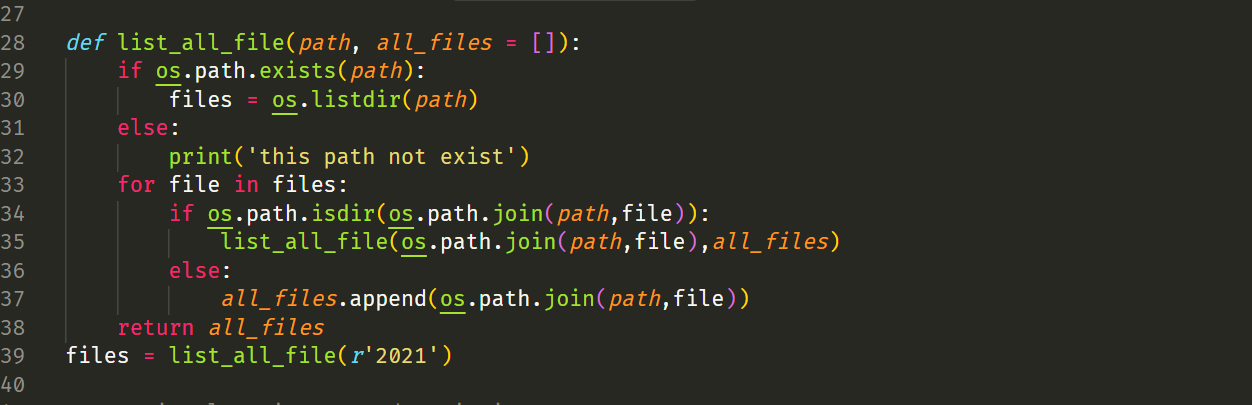
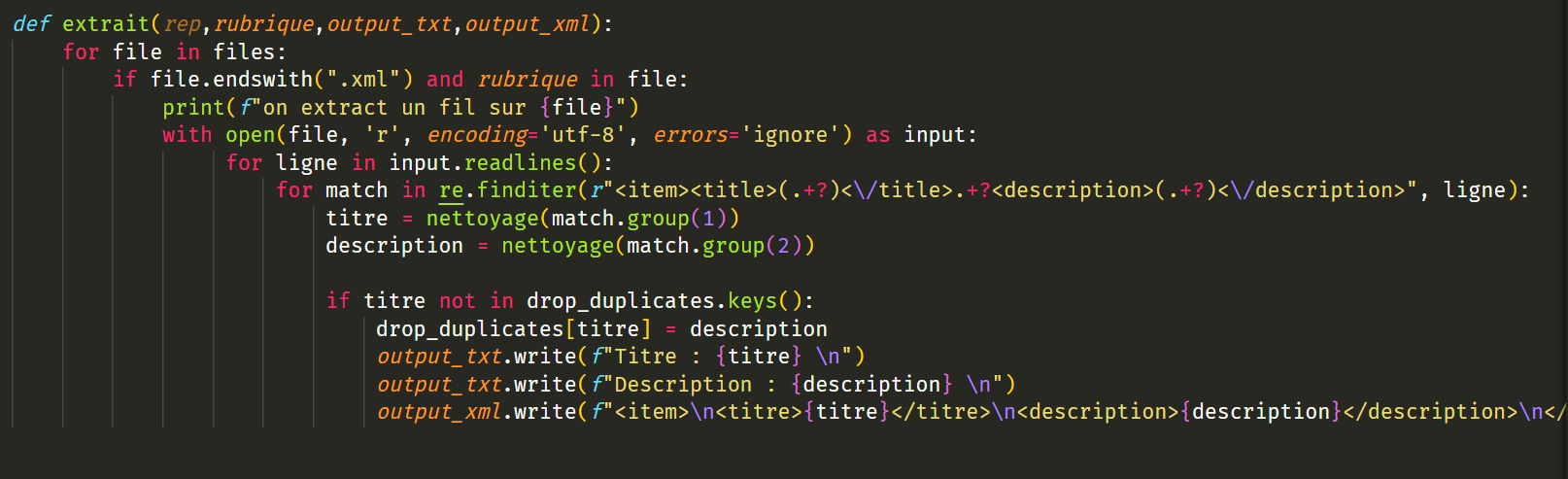
Commande Python

Fichiers sortis :
On obtient deux fichiers au format txt et au format xml qui sont nécessaires pour la phase suivant.
Le fichier txt :
Le fichier xml :