L'objectif de la seconde boîte à outils est de procéder à deux étiquetages sur les données textuelles extraites dans la BAO1: un étiquetage morpho-syntaxique d'abord, un étiquetage en syntaxe de dépendances ensuite. Les programmes écrits en PERL et en Python réalisent également le parcours et l'extraction de la BAO1 avant de procéder à cette phase d'étiquetage.
Pour l'étiquetage morpho-syntaxique, nous utiliserons l'étiqueteur Treetagger, dont nous ne conserverons que les trois annotations que sont la POS, le lemme et la forme. Pour rappel, la POS désigne ce que les grammaires scolaires nomment la nature catégorielle, le lemme correspond à la forme générique à laquelle le mot se rapporte et la forme est l'apparence sous laquelle le mot se présente, pourvue de ses marques flexionnelles, de genre, de temps ou de nombre.
Pour l'annotation en dépendances, nous utilisons le module Udpipe qui exploite les conventions d'annotations en dépendances UD (universal dependencies).
Le script PERL reprend le programme écrit à la BAO1 du parcours de l'arborescence auquel on ajoute les processus de tokenisation et des deux étiquetages.

On reprend le script là où on l'a laissé à la fin de la BAO1, dans la fonction de parcours de l'arborescence, après le nettoyage des titres et des descriptions, au lieu d'envoyer les titres et les descriptions "nets" dans les fichiers de sortie, on les fait maintenant passer par la fonction segmentationTD qui tokenise et verticalise le texte. Treetagger a en effet besoin d'un token par ligne pour annoter correctement.
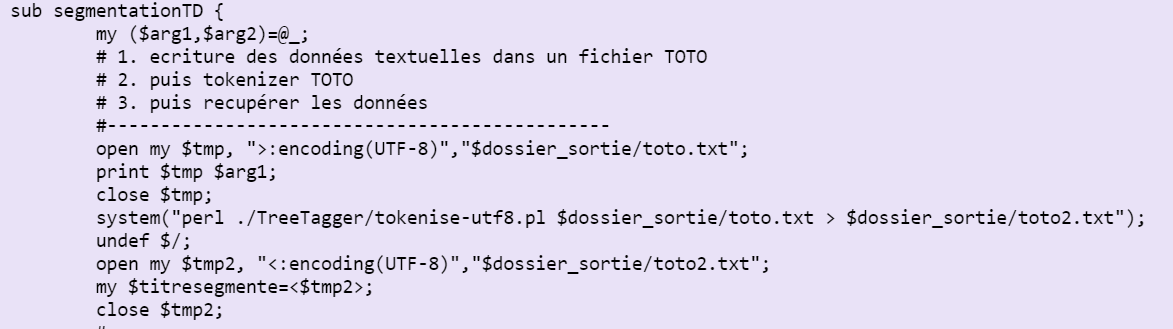
On récupère dans un premier temps les deux arguments que l'on donne à la fonction (les contenus nettoyés du titre et de la description) en vidant la liste. L'argument 1 est le titre, l'argument 2 est la description. Nous ne montrons ci-dessus que le processus de segmentation d'un titre, celui de la segmentation d'une description étant parfaitement identique. On ouvre un fichier temporaire toto.txt dans lequel on stocke le titre fraîchement nettoyé. On exécute le script tout-fait de tokenisation sur le fichier que l'on vient de créer Et on envoie le résultat dans un second fichier temporaire : toto2.txt.
On renvoie en sortie le titre et la description segmentés.

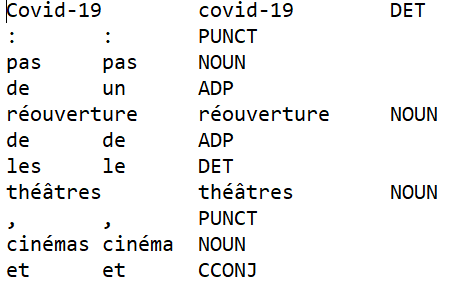
On obtient en sortie un fichier "verticalisé" comme ci-dessus, avec un token par ligne, prêt à être étiqueté.

Maintenant que nous avons des titres et des descriptions tokenisés et verticalisés, nous procédons à l'étiquetage morphosyntaxique via une fonction dédiée. La fonction prend en entrée le pré-corpus verticalisé et fait appel à des scripts tout-faits que nous avons récupérés en téléchargement sur icampus.

Le programme labelise dans un premier temps chaque token en trois étiquettes : la forme, la POS et le lemme.

La fonction fait ensuite appel à un programme PERL qui transforme un étiquetage Treetagger en fichier XML et produit le fichier XML ci-dessus dans lequel chaque étiquette est balisée au format XML.
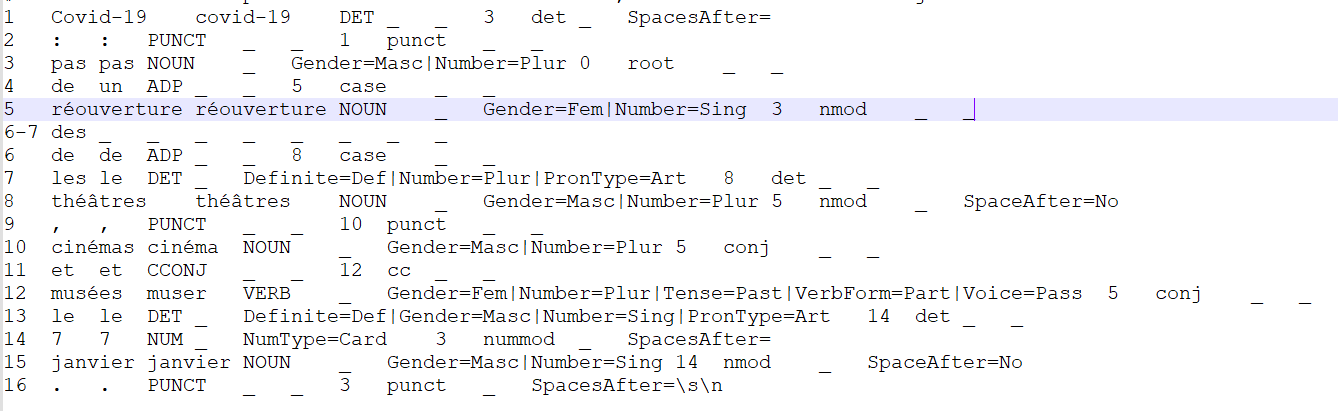
Concernant l'étiquetage en syntaxe de dépendances, la fonction etiquetageUD prend en entrée le fichier txt contenant les titres et les descriptions au format texte brut que le programme parcoursarborescence de la BAO1 générait et produit en sortie un fichier dans lequel les phrases ont été annotées en POS, lemmes et dépendances syntaxiques, selon les conventions UD.
Au début du semestre, Pierre Magistry avait proposé un script qui extrayait un fil RSS unique. Sa solution pour la BAO1 consistait en un un script qui parcourt l'arborescence et fait appel à ce script d'extraction de fil RSS pour chacun des fichiers rencontrés comme on peut le voir ci-dessous.
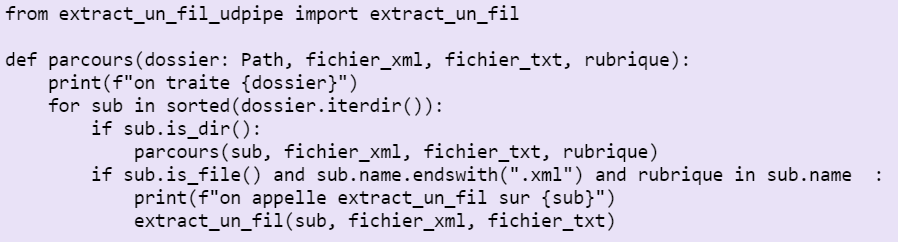
C'est dans ce script d'extraction du fil RSS que les modifications de cette BAO2 ont été apportées.

Là où le script de la BAO1 s'arrêtait au nettoyage (on envoyait dans les fichiers de sortie txt et xml les titres et descriptions nettoyés), on soumet désormais nos titres et descriptions nettoyés à deux fonctions : analyse_txt pour le fichier txt et analyse_xml pour le fichier xml. Voyons en quoi consistent ces fonctions.

Les deux fonctions que nous allons présenter exploitent le module python spacy_udpipe, qui permet de produire des fichiers CONLL mettant au jour les dépendances syntaxiques.
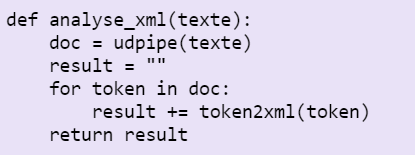
La fonction récupère tour à tour les titres et descriptions nets. On applique l'analyse en dépendances à notre texte via la fonction spacy_udpipe que l'on a préalablement stockée dans la variable udpipe et on fait de l'analyse produite un objet python nommé doc. Pour chaque token contenu dans doc, on le soumet à la fonction de balisage en xml et on le renvoie en sortie.

La fonction à laquelle on vient de faire appel dans la fonction analyse_xml insère la POS, le lemme et la forme du token dans des balises XML.


La fonction analyse_txt fonctionne de la même manière, on ne balise cependant pas le texte au format xml et on renvoie simplement la POS, le lemme et la forme du token séparés par des tabulations.