S0 : "Initiation à Perl"
Initiation à Perl scalaire ; liste ; hash ; fonctions sur les listes ; parcours de liste ; split de chaîne lecture/écriture de fichier recherche dans un texte, les expressions régulières et perl
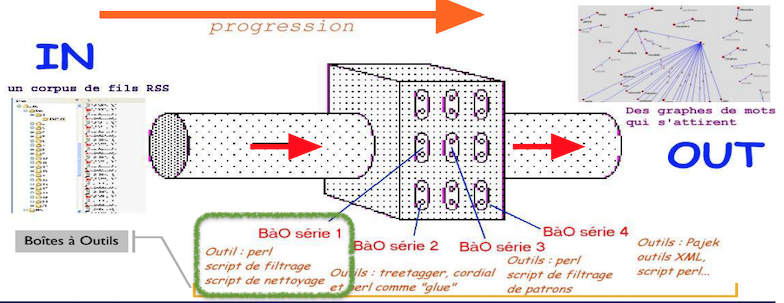
‐ Extraire le texte avec des méthodes « rustiques » : les expressions régulières
‐ Extraire le texte avec des outils adaptés : la bibliothèque XML ::RSS
‐ Intégrer ces traitements dans le programme de parcours d’une arborescence de fils RSS
‐ Préparer au moins 2 types de sortie : texte brut (sortie pour étiquetage avec Cordial), texte structuré en XML
‐ Problèmes d’encodage des fils en entrée (utf‐8, iso‐8859‐1…)
‐ Certains fils contiennent des scories d’encodage…
‐ Pour certains fils RSS en format XML, les fichier sont écrit sur une seule ligne ou plusieurs lignes…
‐ Une des sorties doit être en XML : s’assurer de construire du xml bien formé ou une feuille de style
1. Perl et les RegExp
script
résultats
Ce script perl prend en entrée le nom du fichier contenant tous les fils RSS de l'année 2020 ainsi que le numéro de la rubrique à traiter. Il réalise d'abord un parcours sur l'ensemble des sous fichiers afin de trouver les fichiers dont on a besoin pour l'extraction. Ensuite, grâce à une expression régulière, le programme identifie les contenus entre les balises "titre" et les balises "description" puis les extrait.
2. Perl et la bibliothèque XML::RSS
script
résultats
Cette méthode prend en considération la structuration logique du texte (sous la forme d'un arbre de "la famille RSS" ) et sa modélisation dans un programme pour au final n'avoir qu'à "cueillir" les feuilles textuelles visées !
3. Comparaison
Les deux méthodes donnent des résultats identiques mais le temps de traitement nécessaire pour chacun ne l'est pas ! Généralement, la méthode regex est 8 fois plus rapide que la méthode avec XML:RSS !
| rubrique | regex | xml:rss |
| 3208 | 0.674318s | 5.982587s |
| 3224 | 0.683699s | 5.388945s |
| 3232 | 0.641284s | 5.421392s |
| 3234 | 0.608737s | 5.480011s |
| 3246 | 0.586095s | 5.374622s |
| 3546 | 0.562697s | 5.362816s |