Boîte à outils 3 - partie 3
Des textes aux graphes
Objectif
Les résultats obtenus dans les parties 1 et 2 de la boîte à outils 3 sont regroupés dans des fichiers au format texte brut. Nous souhaitons maintenant visualiser certaines cooccurrences ou relations sous forme de graphes, ce qui facilitera le travail d'analyse.
Méthode
Le programme patron2graph.exe utilisé et son mode d'emploi sont téléchargeables ici :
Nous travaillons sous Linux (Debian) : ce programme nécessite wine. Il s'utilise de la façon suivante :
wine ./patron2graphe "ENCODAGE_DES_FICHIERS" FICHIER_A_TRAITER FICHIER_MOTIF
Il est tout à fait possible de lancer le programme sans préciser de motif, dans ce cas tous les noeuds du graphe sont affichés. Nous décidons d'appliquer un filtrage préalable avec des motifs qui nous semblent pertinents suivants les rubriques et les patrons.
Attention, les fichiers obtenus lors des deux étapes précédentes sont des listes triées. Pour ce passage des textes aux graphes, nous avons réécrit les script perl, sans trier les résultats. Ce sont sur les fichiers de sortie de ce nouveau script que nous lancerons le programme patron2graphe. De cette manière, l'affichage sera plus net et nous pourrons repérer plus aisément sur chaque branche le nombre d'occurrences des cooccurrents.
Nouveau script Perl pour l'extraction de patrons sans tri :
#!/usr/bin/perl
<<DOC;
Nom -- Elise LINCKER
Date -- AVRIL 2021
Traitement -- extraction de patrons morphosyntaxiques
Utilisation du programme -- perl bao3_extract_patrons_SANS_TRI.pl FICHIER_A_TRAITER FICHIER_MOTIF
Exemple d utilisation -- perl bao3_extract_patrons_SANS_TRI.pl ./sortiesBAO2/BAO2_sortieUDpipe_3244.txt patrons.txt
Entrée -- le nom de la sortie UDPipe reformatée en XML
et le fichier TXT contenant la liste des patrons morpho-syntaxiques à extraire
Sortie -- autant de fichiers TXT que de lignes dans le fichier des patrons
chacun contenant la liste (non triée) des séquences qui correspondent au patron
DOC
use utf8;
binmode STDOUT, ':utf8';
#---------------------------------------------------------------------------------
my $fichierUDPipe="$ARGV[0]";
my $fichierPatrons="$ARGV[1]";
#---------------------------------------------------------------------------------
#on stocke les patrons écrits dans $fichierPatrons
open my $termino,"<:encoding(utf8)","$fichierPatrons";
my @patrons = <$termino>;
close($termino);
#---------------------------------------------------------------------------------
#extraction des patrons....
open my $IN ,"<:encoding(utf8)","$fichierUDPipe";
#on crée deux listes parallèles dans lesquelles on va stocker tous les tokens de chaque phrase et leurs pos
my @token=();
my @pos=();
while (my $ligne=<$IN>) {
#si la ligne commence par un #, ou si le token est une forme contractée
# exemple : 3-4 du
# 3 de
# 4 le
# --> on ignore la ligne qui commence par 3-4
#alors il n'y a rien à traiter, et on passe à la ligne suivante
next if $ligne=~m/^#|\d+-\d+/ ;
$ligne=~s/\r?\n//g;
#si la ligne n'est pas vide, on est toujours dans la même phrase :
if ($ligne ne "") {
#on ajoute aux listes le token et le pos récupérés dans la ligne
my @ligne = split /\t/, $ligne;
push @token, $ligne[1];
push @pos, $ligne[3];
}
#sinon, c'est la fin de la phrase ---> on traite les listes
else {
#pour chaque patron $patron récupéré du fichier des patrons,
foreach my $patron (@patrons) {
$patron=~s/\r?\n//g;
#on stocke dans la variable $longueurPatron la longueur du patron (<=> le nombre de POS à extraire pour ce patron)
my $longueurPatron=0;
while ($patron=~/ /g) {$longueurPatron++}
my $i=0;
#pour chaque POS $element de la liste @pos
foreach my $element (@pos) {
$i++;
#si il correspond au premier POS du patron
if ($patron =~/^$element/) {
#on récupère dans la variable string $suitePOS toute la séquence de POS sur $longueurPatron caractères
my $suitePOS="";
my $j;
for ($j=$i-1;$j<=$longueurPatron+$i-1;$j++) {$suitePOS=$suitePOS.$pos[$j]." "}
#si $suitePOS (la suite de POS de longueur $longueurPatron récupérée) correspond au patron
if ($suitePOS=~/$patron/) {
#on concatène les tokens avec des espaces dans la variable $extract
my $extract = join(" ", @token[$i-1..$j-1]);
#et on l'ajoute au tableau du patron correspondant
#(on crée le tableau si il n'existe pas encore)
$dico{$patron} = [] unless exists $dico{$patron};
push @{$dico{$patron}}, $extract;
}
}
}
}
#on réinitialise les listes de tokens et de pos pour la phrase suivante
@token=();
@pos=();
}
}
#on imprime les résultats obtenus pour chaque patron de manière indépendante
foreach my $patron (keys %dico) {
#on crée un fichier de sortie pour le patron traité
my $nomPatron = join("_",split(' ', $patron));
open my $OUT,">:encoding(utf8)","BAO3_sortie_Perl_SANS_TRI_$nomPatron.txt";
#on récupère le tableau qui correspond au patron traité
my @extract = @{$dico{$patron}};
print $OUT (join("\n",@extract));
close $OUT;
}Nouveau script Perl pour l'extraction d'une relation de dépendances sans tri :
#!/usr/bin/perl
<<DOC;
Nom -- Elise LINCKER
Date -- AVRIL 2021
Traitement -- extraction de dépendances syntaxiques
Utilisation du programme -- perl bao3_extract_dep_1relation_udpipexml_SANS_TRI.pl FICHIER_A_TRAITER "RELATION_DE_DEPENDANCE_A_EXTRAIRE"
Exemple d utilisation -- perl bao3_extract_dep_1relation_udpipexml_SANS_TRI.pl BAO2_sortieUDpipe_3244.txt.xml "nsubj" > sorties_dep_sans_tri/BAO3_sortie_Perl_NSUBJ_SANS_TRI_3244.txt
Entrée -- le nom de la sortie UDPipe reformatée en XML
et le nom de la relation syntaxique de dépendance à extraire
Sortie -- la liste (non triée) des couples Gouv Dep de la relation
Remarque -- selon la relation à extraire, on voudra modifier l ordre d affichage des résultats (Dep Gouv ou Gouv Dep) lignes 57 et 66
DOC
use strict;
use utf8;
binmode STDOUT, ':utf8';
#---------------------------------------------------------------------------------
my $fichier="$ARGV[0]";
my $relation="$ARGV[1]";
#---------------------------------------------------------------------------------
#on découpe le texte par phrase (1 phrase par balise <p>)
$/="</p>";
open my $IN ,"<:encoding(utf8)","$fichier";
while (my $phrase=<$IN>) {
#-----------------------------------------------------------------------------
# on transforme la phrase récupérée en une liste d'items : 1 ligne = 1 balise <item>
#il suffit de segmenter les phrases avec le caractère de retour à la ligne car on a déjà 1 item par ligne dans le fichier
my @LIGNES=split(/\n/,$phrase);
#pour chaque ligne = item :
for (my $i=0;$i<=$#LIGNES;$i++) {
#si la ligne lue contient la relation :
#on utilise les expressions régulières pour récupérer :
# la forme du dépendant dans la variable $formeDep
# la position du dépendant dans la variable $positionDep
# la position du gouverneur dans la variable $positionGouv
if ($LIGNES[$i]=~/<item><a>([^<]+)<\/a><a>([^<]+)<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>([^<]+)<\/a><a>[^<]*$relation[^<]*<\/a><a>[^<]+<\/a><a>[^<]+<\/a><\/item>/i) {
my $formeDep=$2;
my $positionDep=$1;
my $positionGouv=$3;
#on récupère la forme du gouverneur dans la variable $formeGouv
#en fonction de la position du gouverneur par rapport au dépendant (avant ou après)
#et on imprime forme du dépendant + espace + forme du gouverneur + saut de ligne
if ($positionDep > $positionGouv) {
#si le gouverneur est avant le dépendant : on cherche le gouverneur parmi les lignes d'indice entre 0 et i
for (my $k=0; $k<$i; $k++) {
if ($LIGNES[$k]=~/<item><a>$positionGouv<\/a><a>([^<]+)<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><\/item>/) {
my $formeGouv=$1;
print "$formeDep $formeGouv\n";
}
}
}
else {
#si le gouverneur est après le dépendant : on cherche le gouverneur parmi la ligne d'indice i+1 et la fin de la liste
for (my $k=$i+1; $k<=$#LIGNES; $k++) {
if ($LIGNES[$k]=~/<item><a>$positionGouv<\/a><a>([^<]+)<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><\/item>/) {
my $formeGouv=$1;
print "$formeDep $formeGouv\n";
}
}
}
}
}
}
close ($IN);Nouveau script Perl pour l'extraction d'une suite de deux relations de dépendances sans tri :
#!/usr/bin/perl
<<DOC;
Nom -- Elise LINCKER
Date -- AVRIL 2021
Traitement -- extraction de dépendances syntaxiques
séquences Dep1 Gouv Dep2, pour 2 relations et un même gouverneur
Dep1 <- Gouv -> Dep2
Utilisation du programme -- perl bao3_extract_dep_2dep1gouv_udpipexml_SANS_TRI.pl FICHIER_A_TRAITER "RELATION1" "RELATION2"
Exemple d utilisation -- perl bao3_extract_dep_2dep1gouv_udpipexml_SANS_TRI.pl ./udpipe2xml/BAO2_sortieUDpipe_3214.txt.xml "nsubj" "obj" > ./sorties_dep_sans_tri/BAO3_sortie_Perl_SVO_SANS_TRI_3214.txt
Entrée -- le nom de la sortie UDPipe reformatée en XML
le nom de la première relation de dépendances
le nom de la deuxième relation de dépendances
Sortie -- la liste (non triée) des triplets Dep1 Gouv Dep2 de la relation
Remarque -- selon les relations, on voudra changer l ordre d affichage des résultats
Gouv Dep1 Dep2 / Dep1 Gouv Dep2 / Dep2 Gouv Dep1 ...etc, lignes 75 et 84
DOC
use strict;
use utf8;
binmode STDOUT, ':utf8';
#---------------------------------------------------------------------------------
my $fichier="$ARGV[0]";
my $relation1="$ARGV[1]";
my $relation2="$ARGV[2]";
#---------------------------------------------------------------------------------
#on découpe le texte par phrase (1 phrase par balise <p>)
$/="</p>";
open my $IN ,"<:encoding(utf8)","$fichier";
while (my $phrase=<$IN>) {
#-----------------------------------------------------------------------------
# on transforme la phrase récupérée en une liste d'items : 1 ligne = 1 balise <item>
#il suffit de segmenter les phrases avec le caractère de retour à la ligne car on a déjà 1 item par ligne dans le fichier
my @LIGNES=split(/\n/,$phrase);
#pour chaque ligne = item :
for (my $i=0;$i<=$#LIGNES;$i++) {
#on utilise les expressions régulières pour tester :
# si la 8e balise <a> contient la chaîne de caractères dans $relation1
#et, le cas échéant, pour récupérer :
# dans la variable $formeDep1 la forme du dépendant 1
# dans la variable $positionDep2 la position du dépendant 1
# dans la variable $positionGouv la position du gouverneur
if ($LIGNES[$i]=~/<item><a>([^<]+)<\/a><a>([^<]+)<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>([^<]+)<\/a><a>[^<]*$relation1[^<]*<\/a><a>[^<]+<\/a><a>[^<]+<\/a><\/item>/i) {
my $formeDep1=$2;
my $positionDep1=$1;
my $positionGouv=$3;
#on utilise les expressions régulières pour tester si il existe un autre item dans la phrase pour lequel :
# la 8e balise <a> contient la chaîne de caractères dans $relation2
# la 7e balise <a> contient le contenu de la variable $positionGouv
# <=> l'item est gouverné par une relation obj et son gouverneur est le même que celui de Dep1
#et, le cas échéant, pour récupérer :
# dans la variable $formeDep2 la forme du dépendant 2
for (my $j=0;$j<=$#LIGNES;$j++) {
if ($LIGNES[$j]=~/<item><a>[^<]*<\/a><a>([^<]+)<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>$positionGouv<\/a><a>[^<]*$relation2[^<]*<\/a><a>[^<]+<\/a><a>[^<]+<\/a><\/item>/) {
my $formeDep2=$1;
#si on a bien récupéré deux items ayant le même gouverneur
#alors, en fonction de la position du gouverneur par rapport au dépendant 1 (avant ou après)
#on récupère dans la variable $formeGouv la forme du gouverneur
#puis on imprime la concaténation : forme dep1 + espace + forme gouv + espace + forme dep2 + saut de ligne
#!!! cet ordre peut être modifié selon le résultat attendu !!!
if ($positionDep1 > $positionGouv) {
#si le gouverneur est avant le dépendant 1 : on cherche le gouverneur parmi les lignes d'indice entre 0 et i
for (my $k=0; $k<$i; $k++) {
if ($LIGNES[$k]=~/<item><a>$positionGouv<\/a><a>([^<]+)<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><\/item>/) {
my $formeGouv=$1;
print "$formeDep1 $formeGouv $formeDep2\n";
}
}
}
else {
#si le gouverneur est après le dépendant 1 : on cherche le gouverneur parmi la ligne d'indice i+1 et la fin de la liste
for (my $k=$i+1; $k<=$#LIGNES; $k++) {
if ($LIGNES[$k]=~/<item><a>$positionGouv<\/a><a>([^<]+)<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><\/item>/) {
my $formeGouv=$1;
print "$formeDep1 $formeGouv $formeDep2\n";
}
}
}
}
}
}
}
}
close ($IN);Tous les patrons extraits avec Perl sans tri pour toutes les rubriques :

Les dépendances S<-[nsubj]-V et S<-[nsubj]-V-[obj]->O extraites avec Perl sans tri pour toutes les rubriques :
Résultats obtenus
Rubrique Planète (3244)
1er sujet d'actualité de l'année 2020 : comme nous l'avons déjà soulevé auparavant, on s'apperçoit que le thème du COVID-19 revient souvent, tout particulièrement dans cette rubrique !
Nous nous intéressons aux distributions de "Covid" et "Coronavirus" (noms propres) parmi les patrons NOM PREP NOMPR et la relation NSUBJ, et de "pandémie" dans divers autres patrons : nous remarquons qu'il y a très peu de noeuds pour les patrons de type NOM ADJ et ADJ NOM : peu d'adjectifs différents sont utilisés pour qualifier ce mot. Pourtant il apparaît à de nombreuses reprises dans les articles, notamment parmi les patrons NOM PREP DET NOM.
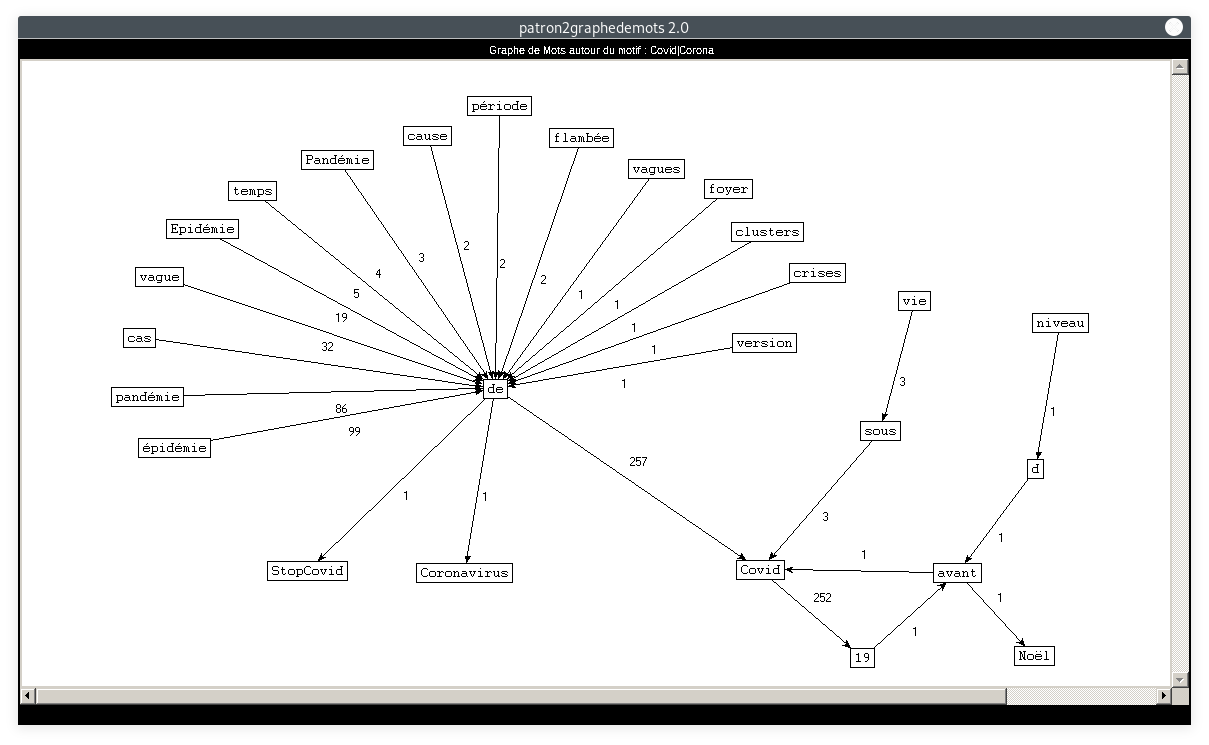
- Motif : Covid|Corona, Patron : NOM PREPOSITION NOMPROPRE
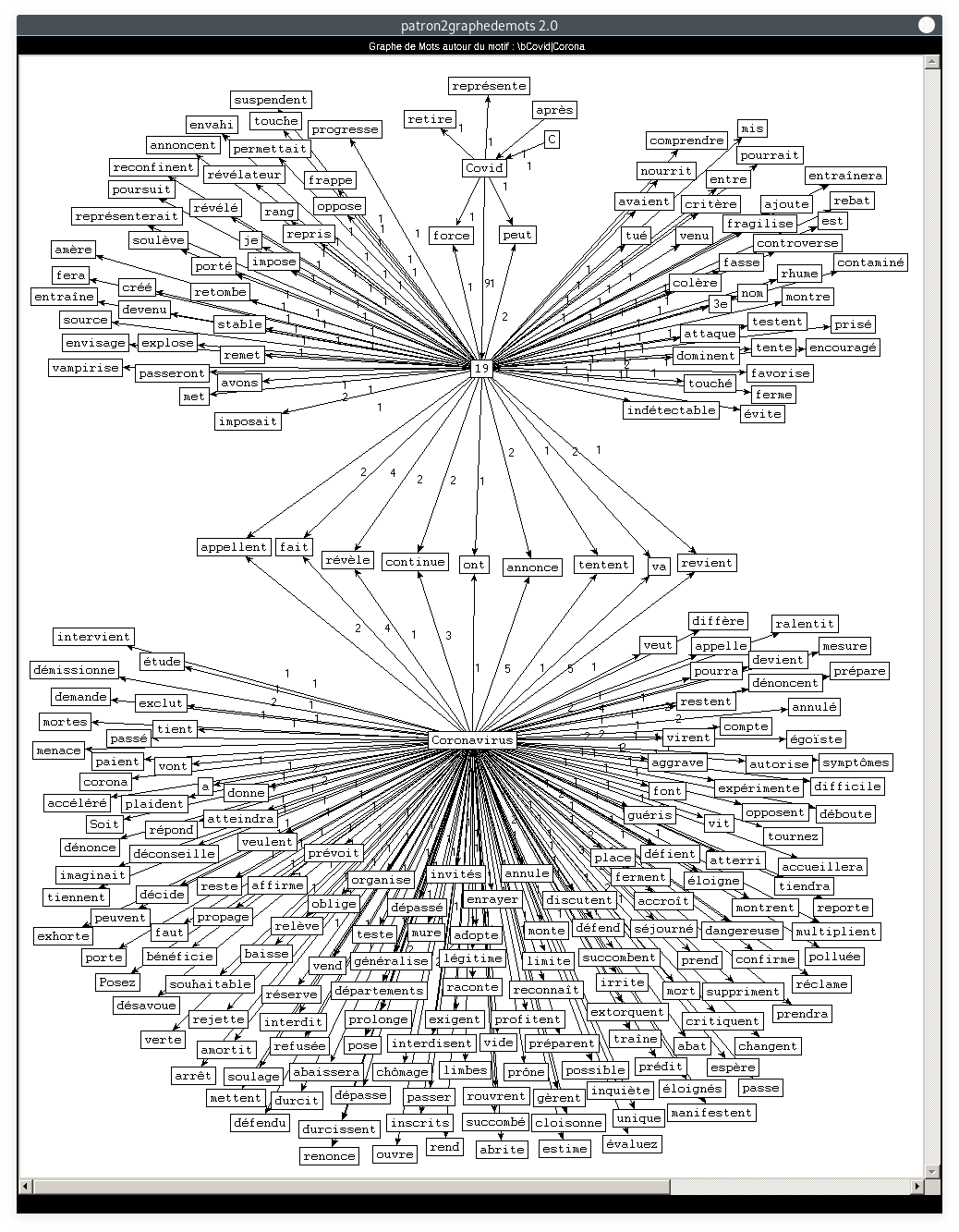
- Motif : Covid|Corona, Relation : SUJET
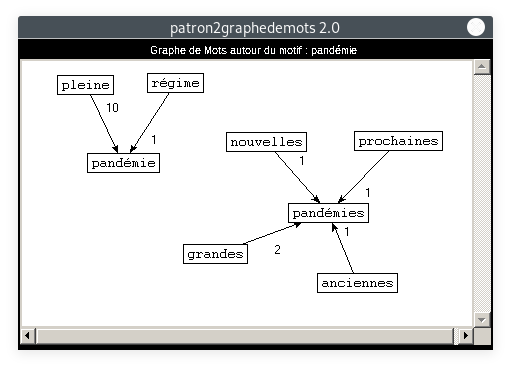
- Motif : pandémie, Patron : ADJECTIF NOM :
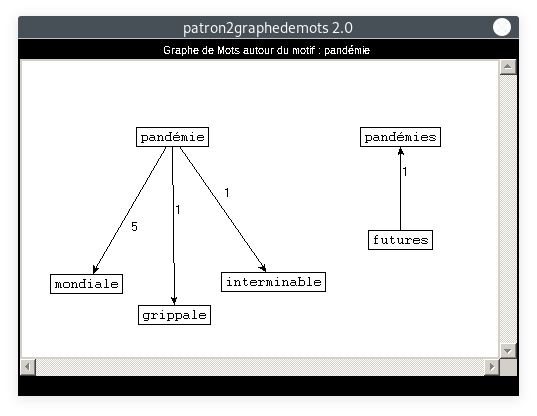
- Motif : pandémie, Patron : NOM ADJECTIF :
- Motif : pandémie, Patron : NOM PREPOSITION DETERMINANT NOM :
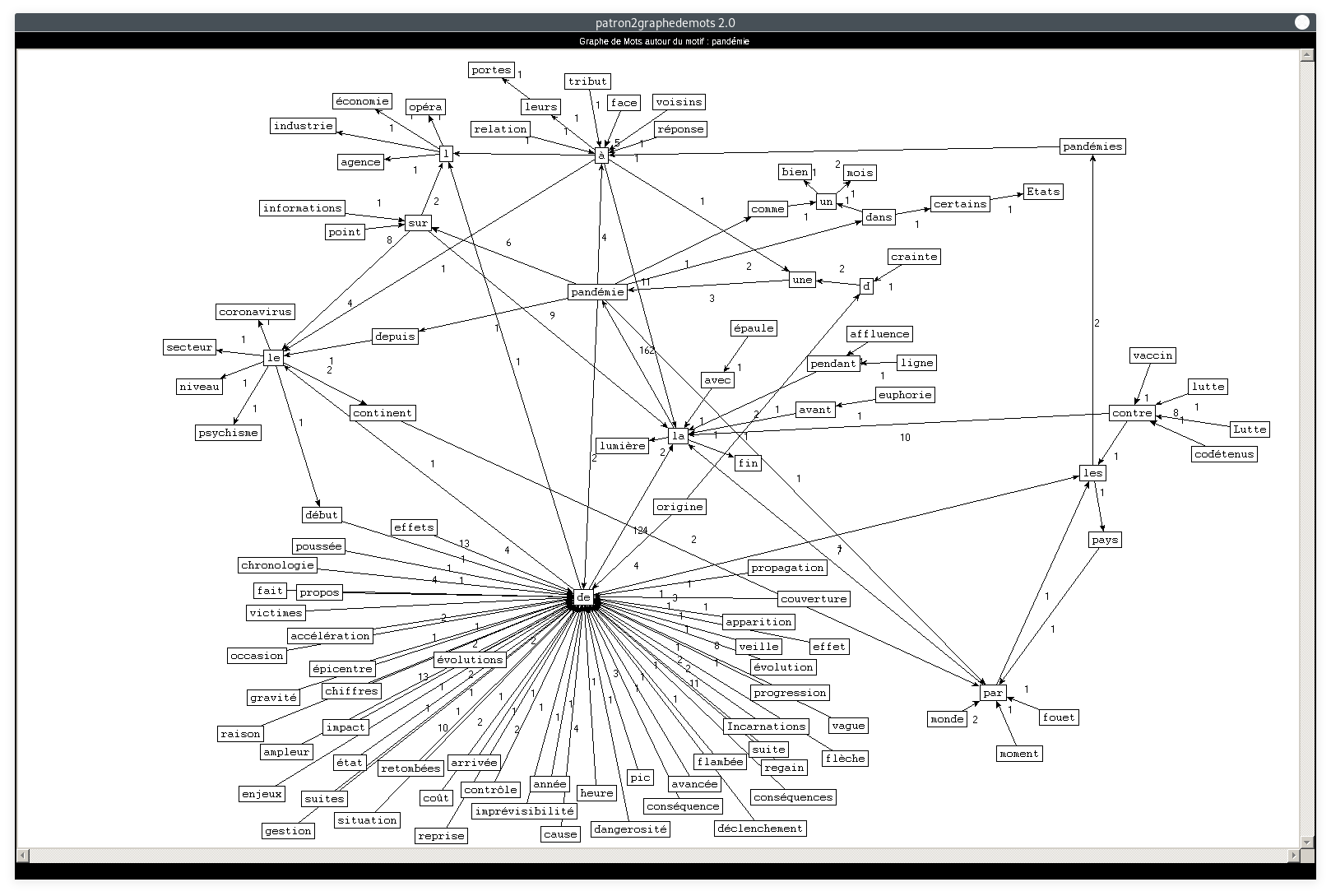
Si les premiers graphes sont clairs, ce-dernier est moins lisible, il y a beaucoup de noeuds qui se croisent et les l'ordre des mots est difficile à voir. Ceci prouve toutefois que c'est un token qui apparaît fréquemment et dans divers contextes. Les adjectifs, noms et verbes cooccurrents mis en avant dans ces graphes sont tout à fait représentatifs du contexte sanitaire vécu en 2020.
Rubrique Culture (3246)
Après avoir jeté un oeil aux patrons extraits, on s'apperçoit que les thèmes sont très divers. Nous décidons de visualiser un certain nombres de motifs différents : "musée", "événement", "ouverture", et "actuel".
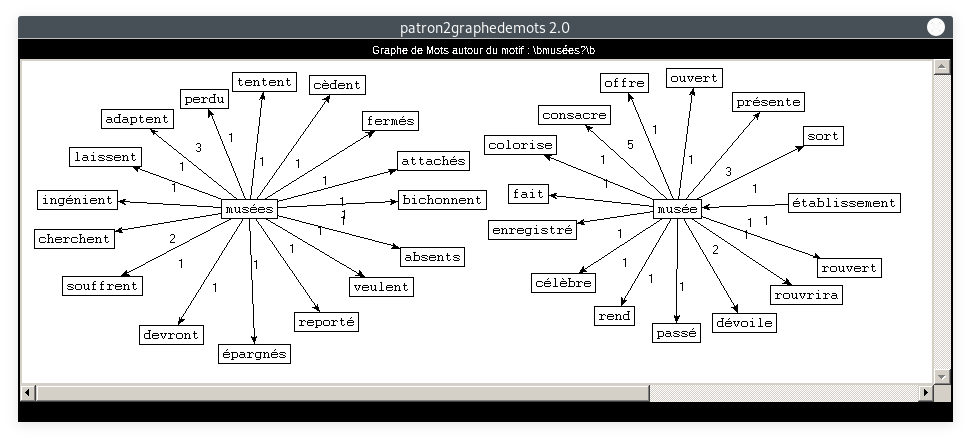
- Motif : musée, Relation : SUJET :
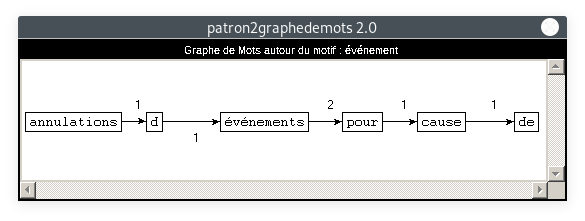
- Motif : événement, Patron : NOM PREPOSITION NOM PREPOSITION :
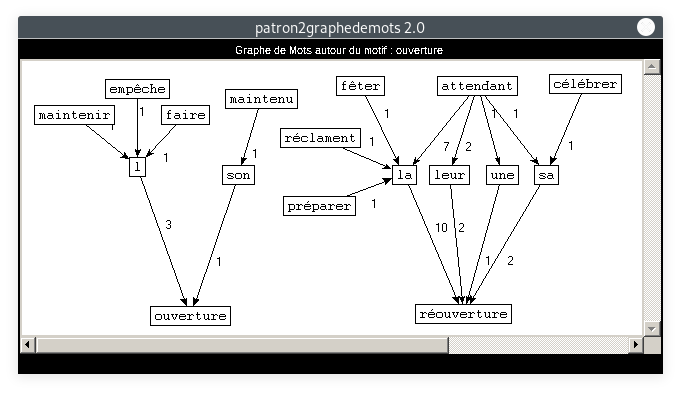
- Motif : ouverture, Patron : VERBE DETERMINANT NOM :
- Motif : actuel, Patron : NOM ADJECTIF :
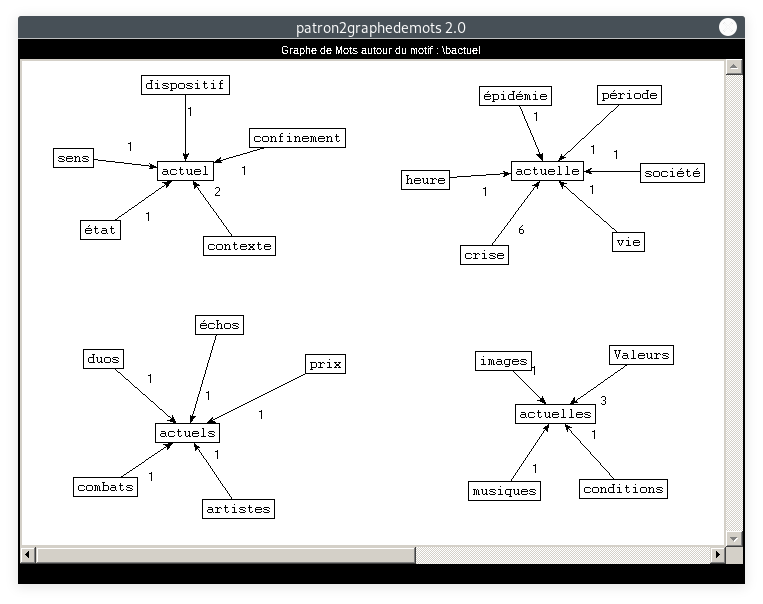
Là encore, les cooccurrents de nos motifs sont clairement liés à la situation sanitaire exceptionnelle de l'année 2020. Ce thème, pourtant non directement lié à la rubrique Culture, est bel et bien présent. Ceci est la preuve que le COVID-19 est le thème dominant de l'année 2020, et a un impact sur tous les domaines. A partir de 4 motifs parmi tant d'autres, nous avons ici particulièrement mis en lumière son impact sur la culture.
Rubrique Cinéma (3476)
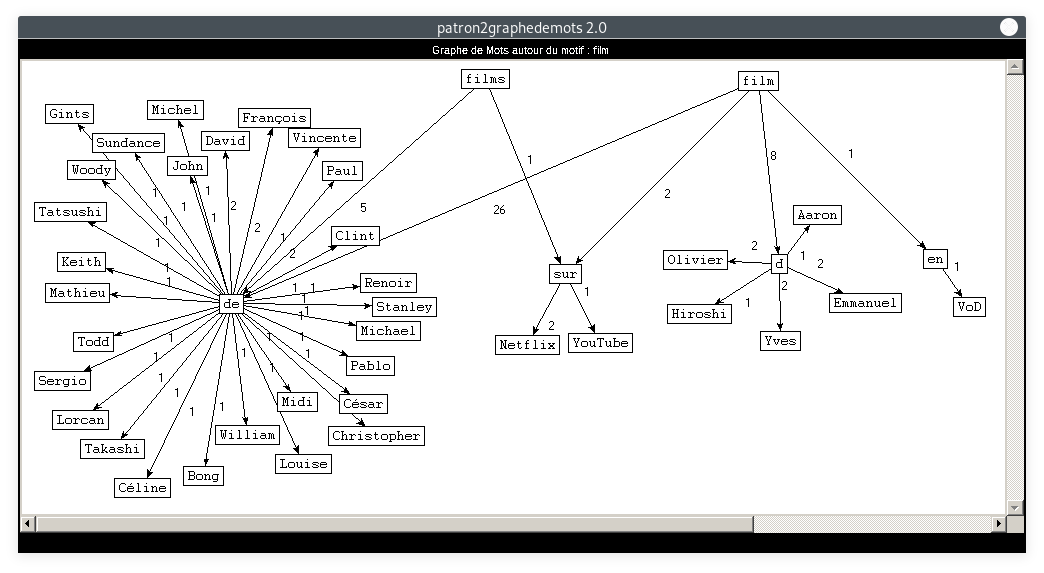
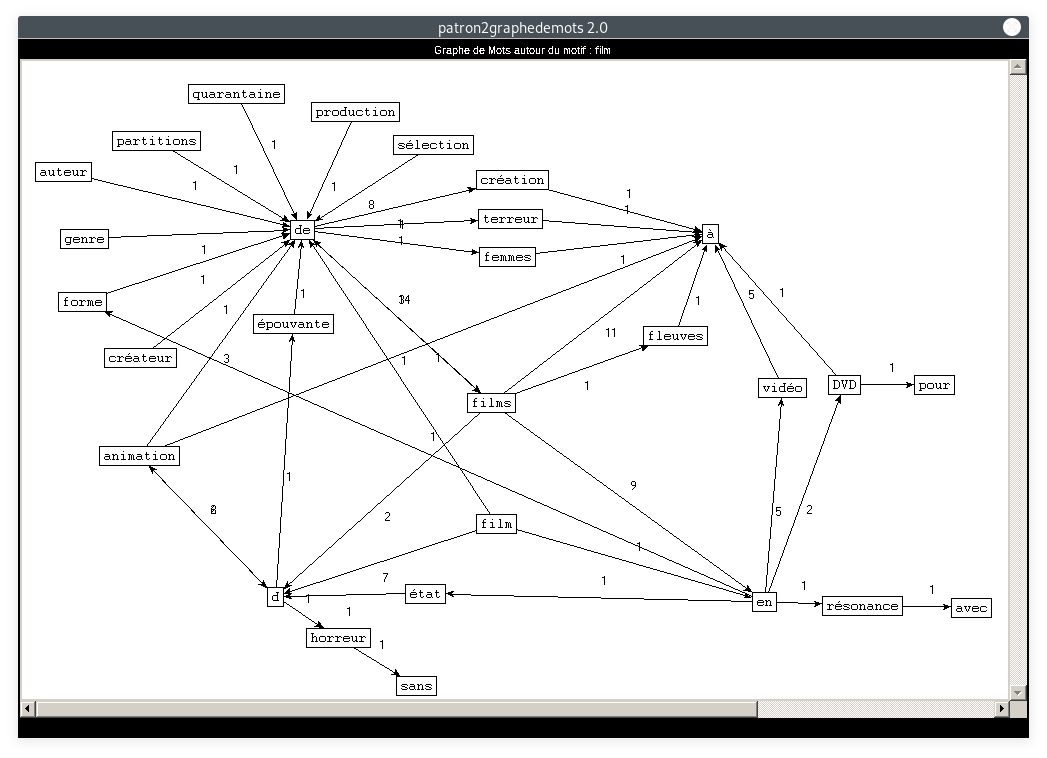
Nous allons ici nous concentrer sur le thème principal de la rubrique Cinéma : les films. Il s'agit de visualiser les cooccurrents du motif "film" dans tous les patrons :
- Motif : film, Patron : ADJECTIF NOM :
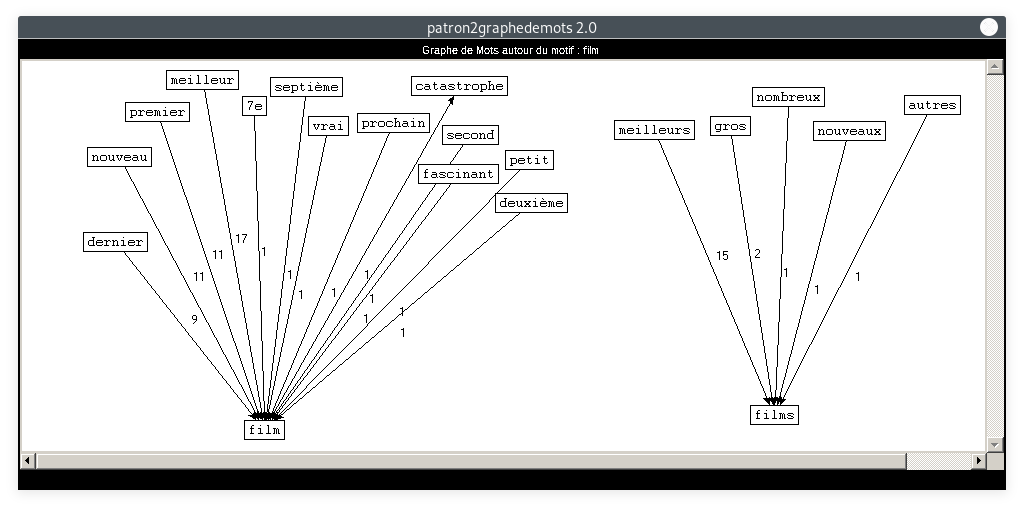
- Motif : film, Patron : NOM ADJECTIF :
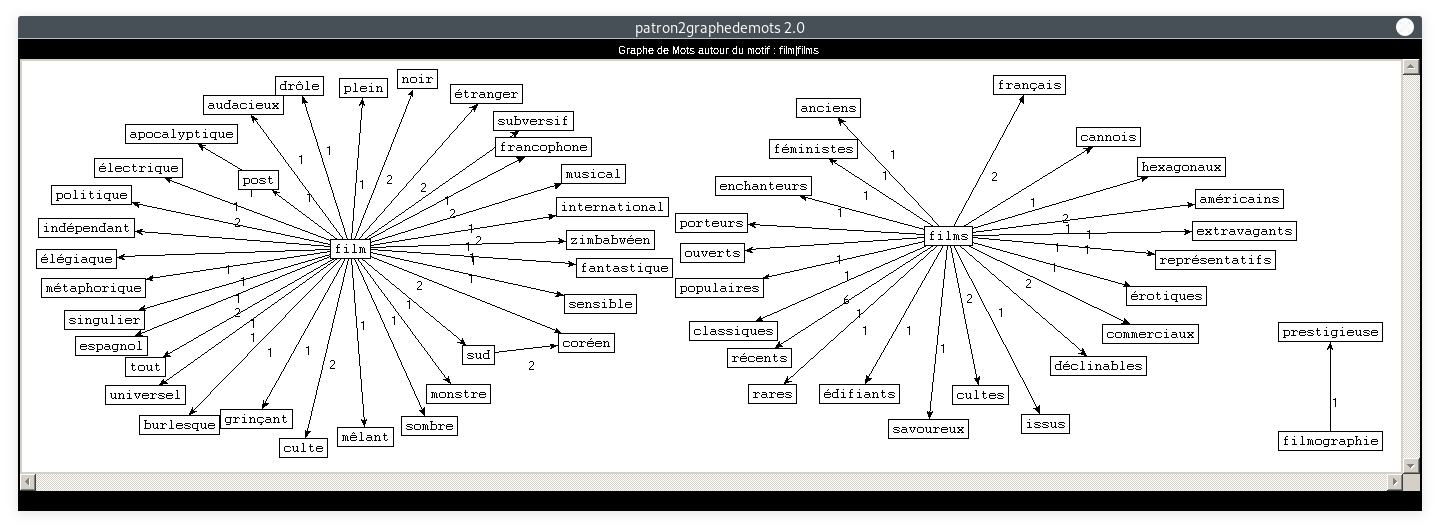
- Motif : film, Patron : NOM ADJECTIF ADJECTIF :
- Motif : film, Patron : NOM PREPOSITION NOMPROPRE :
- Motif : film, Patron : NOM PREPOSITION NOM PREPOSITION :
- Motif : film, Patron : NOM PREPOSITION DETERMINANT NOM :
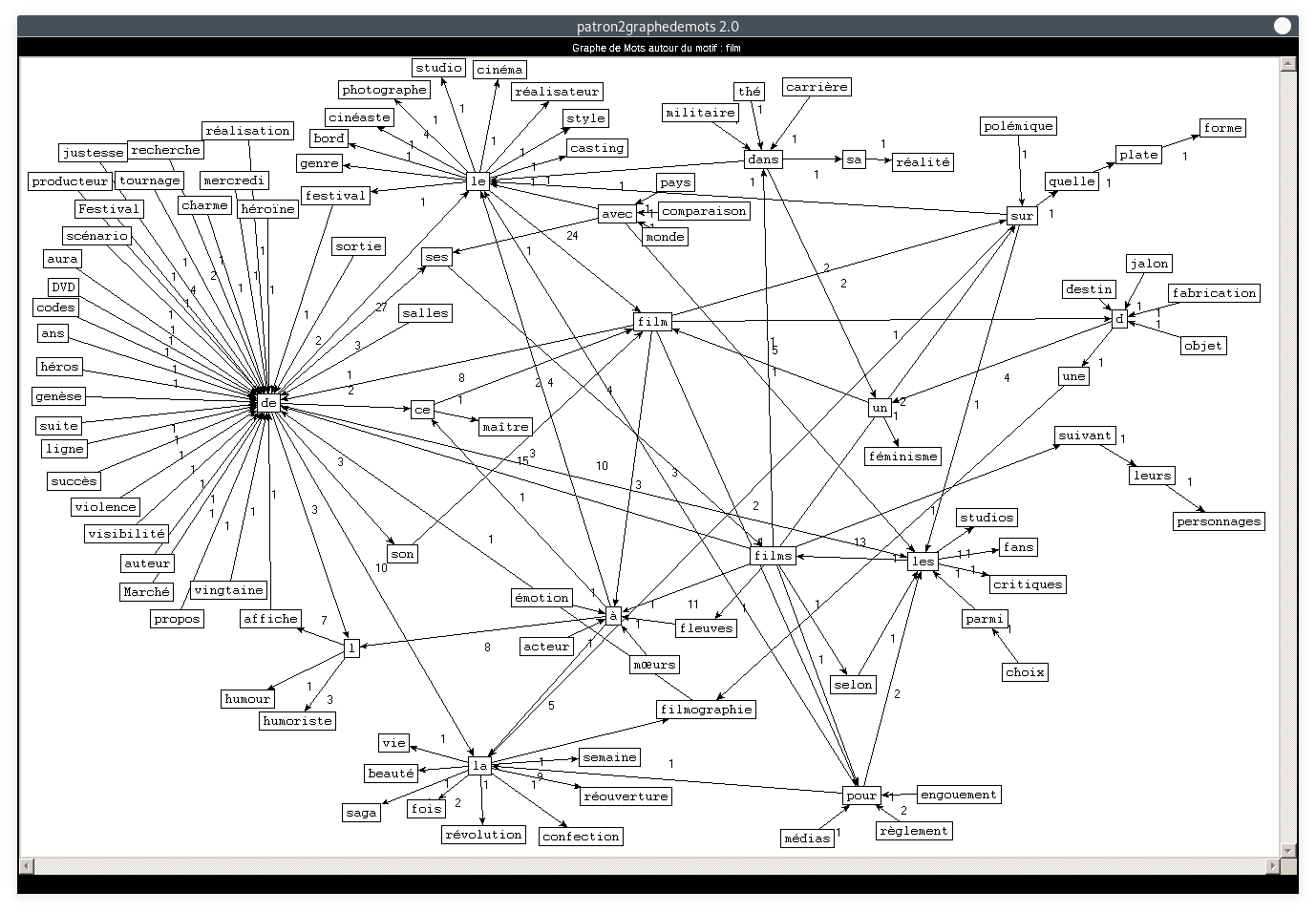
De même que pour la rubrique Planète, nous constatons que les deux derniers graphes sont plus difficiles à lire. Ceci est dû au fait que la catégorie "NOM" apparaît deux fois dans le patron. Notre motif peut se situer à des positions différentes, ce qui crée plus de liens qui se croisent entre les mots. En ce qui concerne le contenu des noeuds : les résultats correspondent tout à fait à ce à quoi nous nous attendions. A priori, on ne relève aucune trace de COVID-19, outre peut-être les mots "réouverture" ou "réglement", mais il faudrait retrouver un contexte plus large pour le confirmer. Les cooccurrents de "film" dans tous les patrons sont cohérents par rapport au thème de la rubrique.
Rubrique Europe (3214)
Nous nous intéressons aux apparitions de notre pays dans cette rubrique du journal : voici ci-dessous les contextes d'apparition du mot France.
- Motif : France, Patron : NOM PREPOSITION NOMPROPRE :
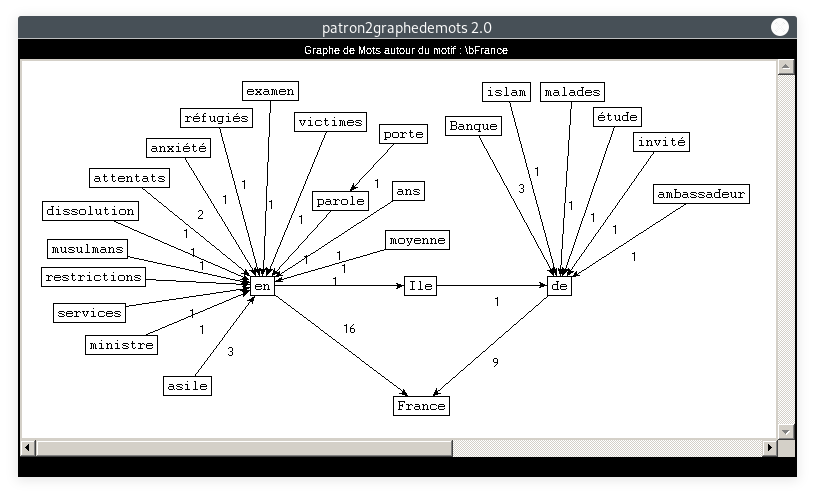
- Motif : France, Relation : SUJET-OBJET :
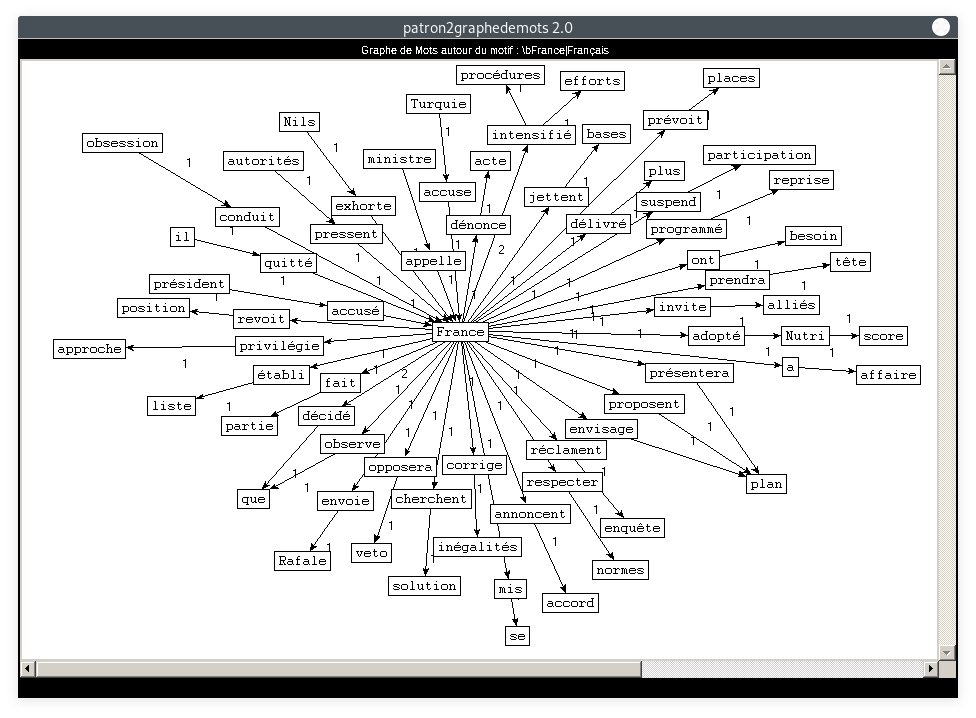
Outre la Turquie, aucun autre pays n'est directement lié à "France" dans ces séquences. On retrouve essentiellement des termes socio-politiques. En ce qui concerne le premier graphe, on relève encore quelques tokens liés aux attentats, aux migrants, ou encore à l'Islam. Le deuxième graphe est plus fourni : entre autres, il montre que la France (en tant que "le gouvernement français") prend des décisions et élabore des plans. Ceux-ci visent probablement à résoudre des situations économiques et socio-politiques, telles que celles illustrées par le premier graphe. On suppose enfin qu'une bonne partie des séquences SUJET-VERBE-OBJET concernent des décisions politiques liées à la situation sanitaire.
Conclusion
Les graphes nous ont permis de visualiser les résultats générés par nos boîtes à outils et de nous focaliser sur des motifs en particulier. L'outil patron2graphe fournit de très bons résultats, cependant il n'est pas très pratique du point de vue de son utilisation. En effet, il produit un graphe désordonné et tassé ; afin d'obtenir un résultat propre et lisible, les items doivent être réarrangés manuellement, ce qui nécessite un petit temps de travail supplémentaire. Il serait intéressant de développer davantage l'outil pour obtenir un affichage propre de manière automatique.
Sur ces graphes s'achève notre projet ! 🙂
... Rendez-vous l'année prochaine pour de nouveaux travaux.