Méthodes : Comment allons-nous procéder ?
Dans un premier temps, nous avons donc pensé à ajouter un sous-programme permettant de rassembler ces deux parties de la même entité, plutôt que de modifier le programme de tokénisation “tokenise-utf8.pl” en lui-même. Mais l’étiqueteur de TreeTagger ne sachant pas prendre en compte les entité XML, il annotait “&” comme un nom.
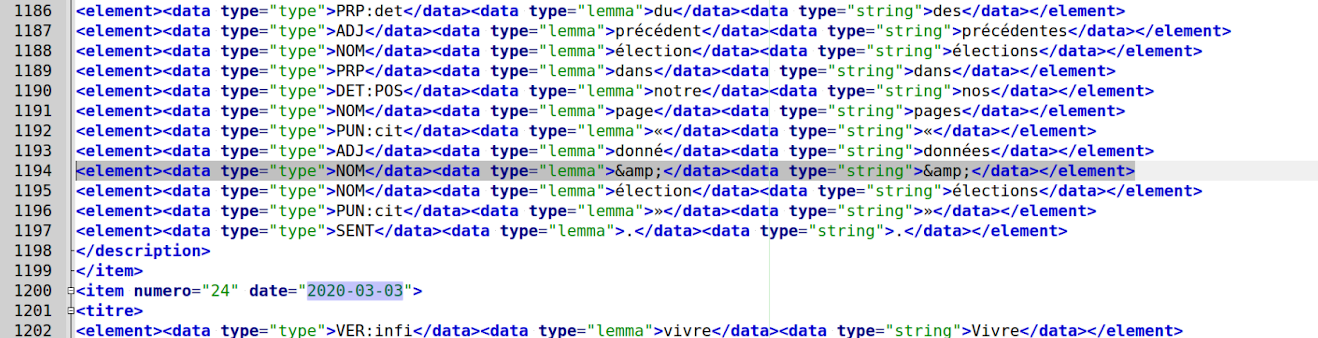
Suite à cela, nous avons donc fait le choix de tout simplement remplacer l’entité XML dans le sous-programme de nettoyage déjà existant. Nous avons hésité entre remplacer “&” par rien ou par “et”. Par souci de cohérence sémantique, nous avons décidé de les remplacer par la conjonction de coordination “et” en toutes lettres.
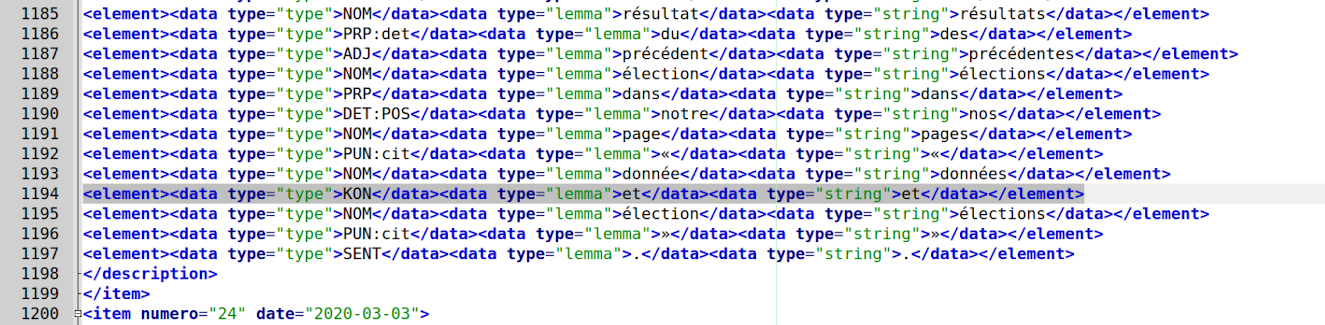
Et plus généralement, les esperluettes étant tokenisé par TreeTagger, nous avons décidé de les remplacer par “et“ lorsqu’ils sont notés comme dans les mots “B&B Hotels”. Dans cet exemple, “B&B Hotels” a donc été remplacé par “BetB Hotels”. Nous avions pensé à les remplacer par “and” pour garder une certaine homogénéité sémantique et lexicale : les marques comme celles-ci sont plus souvent prononcées avec la conjonction de coordination anglaise “and”. Néanmoins, vu que nous utilisons le modèle de langue français de TreeTagger, le “and” n’aurait pas été reconnu ni correctement annoté (lors d’un essai, il avait été annoté comme “VERB”).
Nous avons également modifié le programme “treetagger2xml.pl” pour qu’il nous garde la bonne écriture des attributs ajoutés dans les balises 〈item〉.
Cette BAO existe elle aussi sous deux versions : avec les expressions régulières et avec XML::RSS.
Toujours positionné dans le répertoire ProjetEncadre, nous exécutons les programmes avec les commandes suivantes :
perl ./BAO2/BAO2_ParcoursArborescence_RegExp_Global.pl 2020 n°_rubrique
ou bien
perl ./BAO2/BAO2_ParcoursArborescence_XMLRSS_Global.pl 2020 n°_rubrique
Nous avons fait le choix de produire l’extraction des données textuelles et leur étiquetage sur toutes les rubriques des fils RSS donnés pour l’année 2020. Cela nous permettra de sélectionner les rubriques souhaitées (de préférence, des rubriques qui nous donnent d’assez bons résultats) pour ensuite procéder à l'extraction de patrons syntaxiques et à l’extraction de relations de dépendance.
Résultats : Qu'est ce qu'on a obtenu ?
Le tableau ci-dessous résume les différentes rubriques, le nombre d’items traités et les informations sur les résultats produits.
| Rubrique |
Code associé |
Nombre d'items distincts traités |
Temps de traitement (Perl + RegExp) |
Poids des fichiers texte brut |
Poids des fichiers XML (TreeTagger) |
Poids des fichiers UDPipe |
| une |
02-3208,1-0,0 |
6566 |
316 sec |
1,8 Mo |
35,2 Mo |
20,2 Mo |
| international |
0,2-3210,1-0,0 |
6684 |
334 sec |
1,8 Mo |
35,0 Mo |
20,3 Mo |
| europe |
0,2-3214,1-0,0 |
3533 |
170 sec |
996,2 ko |
18,8 Mo |
10,9 Mo |
| societe |
0,2-3224,1-0,0 |
5778 |
320 sec |
1,7 Mo |
33,1 Mo |
19,1 Mo |
| idees |
0,2-3232,1-0,0 |
4177 |
284 sec |
1,4 Mo |
27,0 Mo |
15,5 Mo |
| economie |
0,2-3234,1-0,0 |
5763 |
303 sec |
1,7 Mo |
31,4 Mo |
18,1 Mo |
| actualite-medias |
0,2-3236,1-0,0 |
607 |
37 sec |
170,0 ko |
3,3 Mo |
1,9 Mo |
| sport |
0,2-3242,1-0,0 |
2024 |
75 sec |
556,6 ko |
11,1 Mo |
6,3 Mo |
| planete |
0,2-3244,1-0,0 |
6018 |
230 sec |
1,7 Mo |
32,8 Mo |
18,9 Mo |
| culture |
0,2-3246,1-0,0 |
4813 |
175 sec |
1,2 Mo |
24,5 Mo |
13,8 Mo |
| livres |
0,2-3260,1-0,0 |
1284 |
48 sec |
331,5 ko |
6,7 Mo |
3,7 Mo |
| cinema |
0,2-3476,1-0,0 |
972 |
48 sec |
250,2 ko |
5,0 Mo |
2,8 Mo |
| voyage |
0,2-3546,1-0,0 |
22 |
2 sec |
5,0 ko |
97,6 ko |
57,3 ko |
| technologies |
0,2-651865,1-0,0 |
125 |
8 sec |
35,6 ko |
676,7 ko |
388,7 ko |
| politique |
0,57-0,64-823353,0 |
3962 |
203 sec |
1,1 Mo |
21,9 Mo |
12,7 Mo |
| sciences |
env_sciences |
1136 |
50 sec |
328,1 ko |
6,1 Mo |
3,5 Mo |
Trois types de fichiers résultent de cette boîte à outil :
- “sortie-slurp_rubrique.txt” : un fichier qui contient le texte brut des titres et descriptions.
- “sortieudpipe-slurp_rubrique.txt” : un fichier au format CONLL qui contient le résultat de l’étiquetage par UDPipe.
- “sortiexmlTT-slurp_rubrique.xml” : un fichier au format XML qui contient le résultat de l’étiquetage par TreeTagger.
Un quatrième type de fichier résulte de ce programme (“sortiexml-intermediaire-slurp_rubrique.xml”), mais comme indiqué dans le nom du fichier, celui-ci est intermédiaire et ne sert que de base afin de produire le fichier XML depuis TreeTagger.
Lien vers le script BAO2 RegExp.
Lien vers le script BAO2 XML::RSS.
Résultats obtenus avec la BAO2.
