Étiquetage morpho-syntaxique
1. Objectif
Après avoir extrait les contenus textuels du flux RSS du journal Le Monde, nous allons ensuite les tokeniser et tagger. Nous nous servons de deux outils d'étiquetage : Tree Tagger et UD pipe. Les fichiers de sortie seront avec extension .txt et .xml.
2. Étiquetage morpho-syntaxique
L'étiquetage morpho-syntaxique (POS tagging, part-of-speech tagging en anglais) consiste à attribuer aux mots d'un texte
les informations grammaticales correspondantes à travers l'utilisation d'un outil informatique.
Les informations grammaticales concernent la partie du discours, le genre, le nombre, etc.
Chaque étiquteur a une convention d'étiquetage différente de celles des autres. Pour la langue française,
nous avons les étiqueteurs prêts à l'emploi comme TreeTagger, UD Pide, etc. Voici un exemple dans nos résultats :
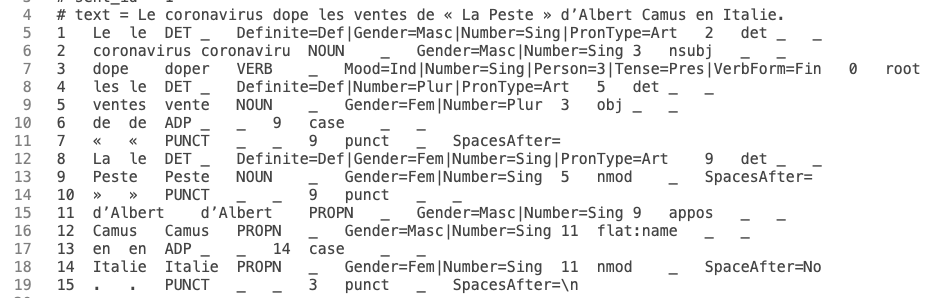
3. Script
Nous utilisons la langue Perl pour le traitement. Notre BàO2 se compose par trois parties : la première partie consiste d'abord à extraire le contenu textuel (un fichier brut du filtrage et un fichier structuré au format xml seront produits). Puisque les résultats sont pareils que ceux de BAO1, nous n'allons pas exposer ci-dessous les résultats de la première partie. La deuxième partie consiste quant à elle à étiqueter les fichiers de sortie avec TreeTagger et UD Pipe (deux fichiers étiquetés avec extension .txt seront produits). Enfin, la troisième partie a pour but de structurer les deux fichiers étiquetés au formal textuel et deux fichiers avec extension .xml seront produits.
Données d'entrée : tous les fichiers du fil RSS de journal "Le Monde" de l'année 2020.
Commande d'exécution: on se situe dans le répertoire correspondant à "BAO2", puis on tape « perl bao2.pl 2020 3208 » (deux paramètres : le nom du répertoire contenant les fichiers à traiteret le nom de la rubrique à traiter parmi ces fichiers).
Télécharger le script de BAO24. Résultats
Nous traitons d'abord toutes les rubriques de nos données RSS. Après avoir obtenu les résultats de chaque rubrique, nous écrivons un petit script python pour fusionner la sortie des résultats en fonction du format de sortie. Peandant l'exécution du script, afin d'envoyer le contenu dans un fichier total, on modifie le nom de rubrique dans le "nom_fic".
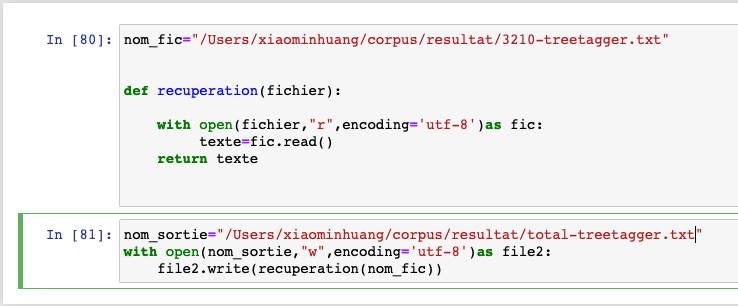
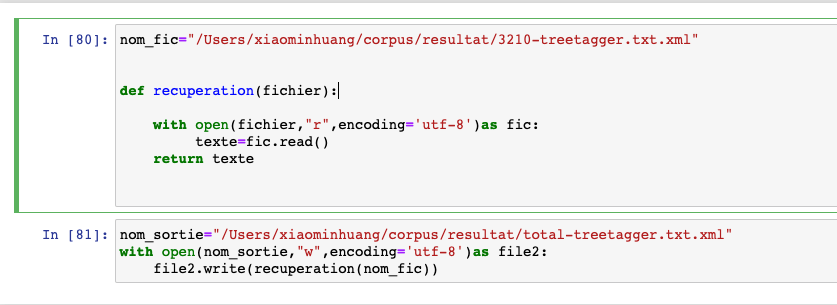
4.1. Résultats totaux
TOUS LES FICHIERS RSS DE L'ARBORESCENCE 2020
4.2. Résultats par rubrique
Pour la rubrique A LA UNE (N. 3208):