Boîte à Outils 2
Enrichissement des données par étiquetage automatique
| Objectif : les contenus textuels extraits doivent être étiquetés automatiquement (TreeTagger et UDPipe) : annotation en morpho-syntaxe et en dépendances. |
Pour procéder à une analyse morpho-syntaxique des contenus des fils RSS du Monde de l’année 2020, il faut d’abord les enrichir par annotation. Cette année, l’étiquetage automatique est réalisé avec TreeTagger et UDPipe.
On remarquera au cours de ce travail des différences de choix de découpage et d'annotation entre les deux outils comparés, la première étant évidemment au niveau du tagset, distribué comme suit:
TreeTagger:
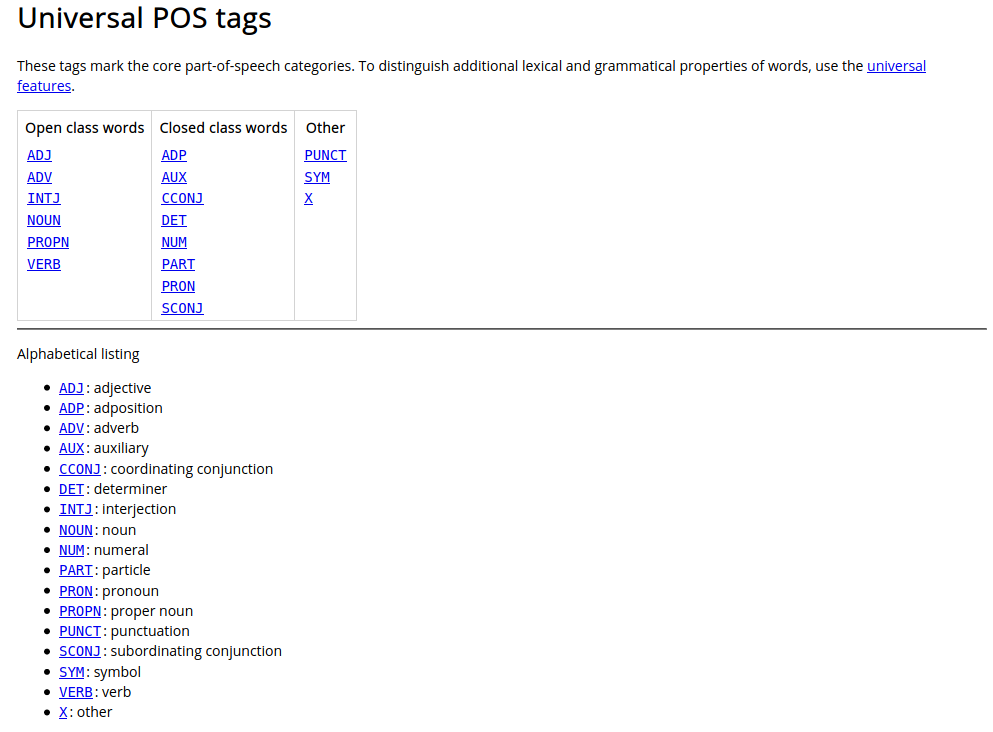
UDPipe, format U-ConLL (pour le POS qui nous intéresse, Universal POStags):
Toutes les tâches sont effectuées par le script perl BAO2_etiquetage_regexp.pl, suite du script perl BAO1_extraction_regexp.pl :
| Remarque : pour préparer le travail d’analyse morpho-syntaxique, nous convertissons ensuite à leur tour les fichiers annotés avec UDPipe du format txt vers le format xml grâce au script perl fourni udpipe2xml.pl. |
Comme pour la BAO 1, une autre méthode a été implémentée pour illustrer l’utilisation de la bibliothèque XML::RSS dans le script perl BAO2_etiquetage_rss.pl.
On note que le travail d’étiquetage est plus rapide pour les rubriques comme "cinéma" ou "sport", sûrement parce que les actualités dans ces domaines sont redondantes, on les retrouve d’un jour sur l’autre (et ici on procède à l’élimination des doublons). La normalisation des apostrophes est primordiale pour l’utilisation de l’outil UDPipe (dans le sous-programme de nettoyage : $description=~s/’/'/g; et $titre=~s/’/'/g;), sinon il est incapable de les reconnaître correctement. En effet, il sépare bien les ensembles contenant une apostrophe en deux tokens quand c’est nécessaire “d’”+“où”, “l’”+“épidémie”, “d’”+“origine” ou “n’”+“ont” mais sait aussi reconnaître des mots comme “aujourd’hui” en un seul token. A l’inverse, TreeTagger considère comme un seul token les ensembles contenant une apostrophe tels que “l’armement”, “n’existe” ou encore “d’intéressement”. Sur ce point, on peut donc considérer que UDPipe est plus en accord avec nos choix linguistiques, et propose un étiquetage plus conforme à nos attentes.
Exemples d’étiquetages attendus (illustrant la question de l’apostrophe évoquée ci-dessus):
Étiquetage TreeTagger au format xml:
Étiquetage UDPipe au format txt - ConLL:

Étiquetage UDPipe au format xml:

Voici un schéma résumant ce qu'on trouve en sortie de la BàO 2:

Et ci-dessous, les résultats, sous forme de zip à télécharger à chaque fois car les fichiers une fois annotés sont très lourds en données:
BàO 2 avec les expressions régulières:
Cliquez sur l'icône pour afficher le script perl.
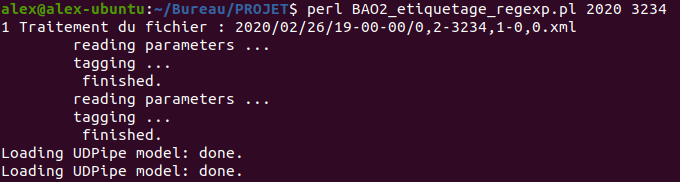
Lancement de la BAO 2 regexp sur la rubrique "économie" via le terminal:
BàO 2 avec les fils RSS:
Cliquez sur l'icône pour afficher le script perl.
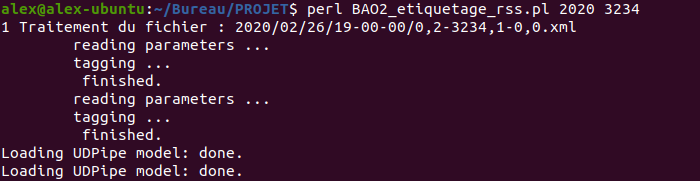
Lancement de la BAO 2 rss sur la rubrique "économie" via le terminal:
| Rubrique | Sortie TreeTagger | Sortie Udpipe (txt) | Sortie Udpipe (xml) |
|---|---|---|---|
| Sport | Cliquez ici pour voir la sortie avec TreeTagger (xml) | Cliquez ici pour voir la sortie avec UDPipe (txt) | Cliquez ici pour voir la sortie avec UDPipe (xml) |
| Cinéma | Cliquez ici pour voir la sortie avec TreeTagger (xml) | Cliquez ici pour voir la sortie avec UDPipe (txt) | Cliquez ici pour voir la sortie avec UDPipe (xml) |
Le plus important à cette étape est d’obtenir en sortie des données bien structurées pour pouvoir ensuite leur appliquer les requêtes d’extraction morpho-syntaxiques et en dépendances. En ouverture, on pourrait essayer encore d’autres outils d’étiquetage automatique pour comparer leur efficacité et trouver celui qui se rapproche le plus de nos propres choix.