BàO 1
Extraction de contenus textuels des fils RSS
OBJECTIF
L’objectif de cette boîte à outils 1 est d’extraire des contenus textuels des fils RSS de l'arborescence, plus précisément les contenus des balises title et description.
FIL RSS ?
RSS signifie Really Simple Syndication , qui veut dire Syndication très simple, ou plus littéralement Flux de dépêches en français. Un flux RSS permet donc de diffuser du contenu comportant diverses données : un titre, un contenu, une date, un auteur, une image…
Un fil RSS est un fichier XML qui répond à quelques règles simples de structure qui sont définies par le langage RSS. Tous les fichiers RSS contiennent cette schématisation.
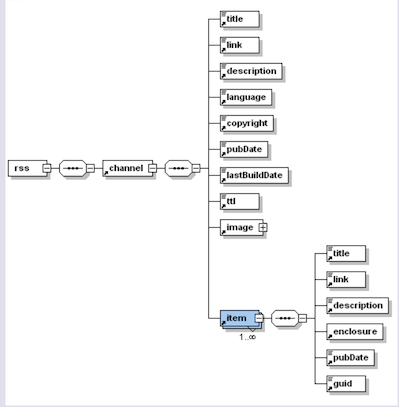
CORPUS
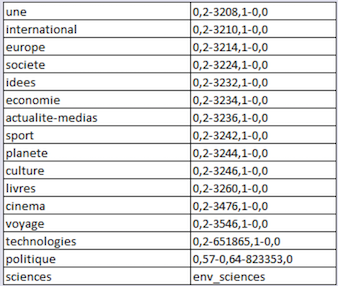
Notre corpus comprend l’ensemble des fils RSS du journal Le Monde recueillis tous les jours de l’année 2020 à 19h. Dans le répertoire de chaque jour nous trouverons donc un fichier TXT et un XML pour chacune des 16 rubriques. Les répertoires sont organisés de la façon suivante : année/mois/jour/heure/fils RSS. Dans l’image ci-dessous, par exemple, vous voyez les fichiers des 16 rubriques correspondant au 1 février 2020.
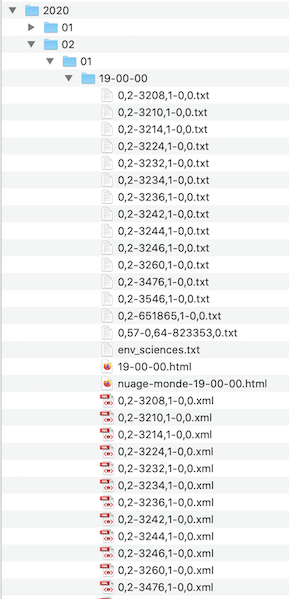
Chaque rubrique comporte un identifiant numérique.
EXTRACTION
Comparé aux fils des années précédentes, le fil RSS 2020 est plutôt bien structuré et ne comporte pas beaucoup de bruit dans les balises title et description ce qui nous a facilité la tâche d’extraction.
L’extraction s’est faite à partir des fichiers XML à l’aide de différentes méthodes que nous détaillerons plus bas, nous parcourons l’arborescence des fils RSS pour en extraire le contenu textuel des balises title et description de chaque fichier jour. Nous aurons comme sortie un fichier par rubrique comportant tous les titres et descriptions de l’année en version TXT et XML.
SCRIPTS
Trois méthodes ont été développées.
- La première considère le texte comme un "sac de caractères" dans lequel on va essayer de repérer certaines régularités via les expressions régulières via le langage PERL .
- La deuxième prend en considération la structuration logique du texte (sous la forme d'un arbre de "la famille RSS " ) et sa modélisation dans un programme pour au final n'avoir qu'à "cueillir" les feuilles textuelles visées.
- Une troisième méthode sera proposée en Python utilisant la bibliothèque ElementTree . Ce dernier est un module pour analyser et créer des données XML.
Methode 1 : Script PERL - REGEX
Methode 2 : XML-RSS
Methode 3 : Python - ET
RÉSULTATS
Les résultats obtenus avec les trois fichiers sont similaires, en effet le contenu textuel des balises étant presque ou pas pollué par des éléments CDATA ou d'autres, le rendu est assez homogène en utilisant n'importe quel script
Exemple sortie format TXT
Exemple sortie format XML
- © Yagmur Ozturk & Oscar Moreno Escobar. All rights reserved
- Design: HTML5 UP