Corpus Multilingue
Le Tuning en quatre langues

Voici les liens vers nos corpus :
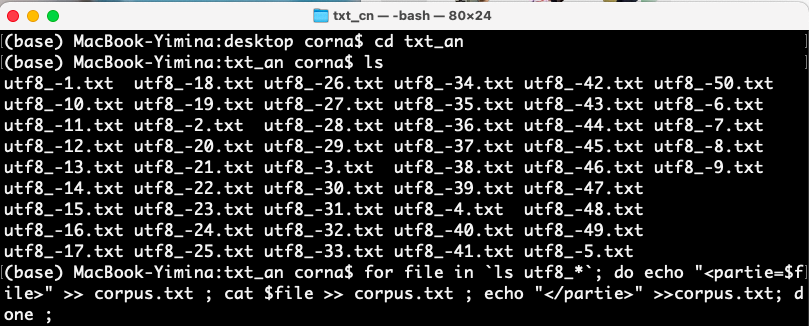
Et voici les liens vers les contextes concaténés :Pour pouvoir réaliser l'analyse des corpus, il a fallu concaténer les fichiers extraits grâce au programme. Nous avons donc concaténé les textes dans la console Unix en utilisant les commandes suivantes : 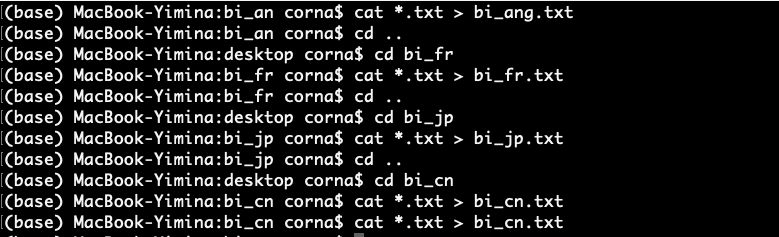
Nous avons ensuite ajouté des balises à notre corpus pour pouvoir l'utiliser sur iTrameur. En effet, les corpus sont très longs, donc il vaut mieux ajouter des balises entre chaque article et les dissocier en partie. Pour ce faire, nous avons utilisé une boucle for pour traiter chaque texte du répertoire. Pour séparer les parties nous avons utilisé la commande "do echo "<partie=$file>" >> corpus.txt", en n'oubliant pas la balise fermante, puis nous avons crée de nouveaux corpus, cette fois balisés.