CONCATENATION DES DUMPS ALLEMAND ET ANGLAIS
Concernant l’allemand et l'anglais, nous avons tenté de concaténer via le script final en rajoutant ces lignes dans le script final :

Cependant, cela a créé des erreurs.
Donc, nous avons fait au plus simple : à partir de la ligne de commande ubuntu, nous avons utilisé cette commande

La commande a correctement cancaténé les dumps. Idem pour les contextes.
La partie suivante fut le véritable obstacle : obtenir les résultats d'analyse à partir du trameur.
Rappels sur le trameur
I-trameur est un outil d'analyses textométriques. Ces analyses se générées à partir d'un corpus partitionné en amont. Le trameur permet aussi de créer des annotations sur des unités de texte. Une version à télécharger pour l'environnement Windows existe. Les principes sont les mêmes.
Le i-trameur en ligne
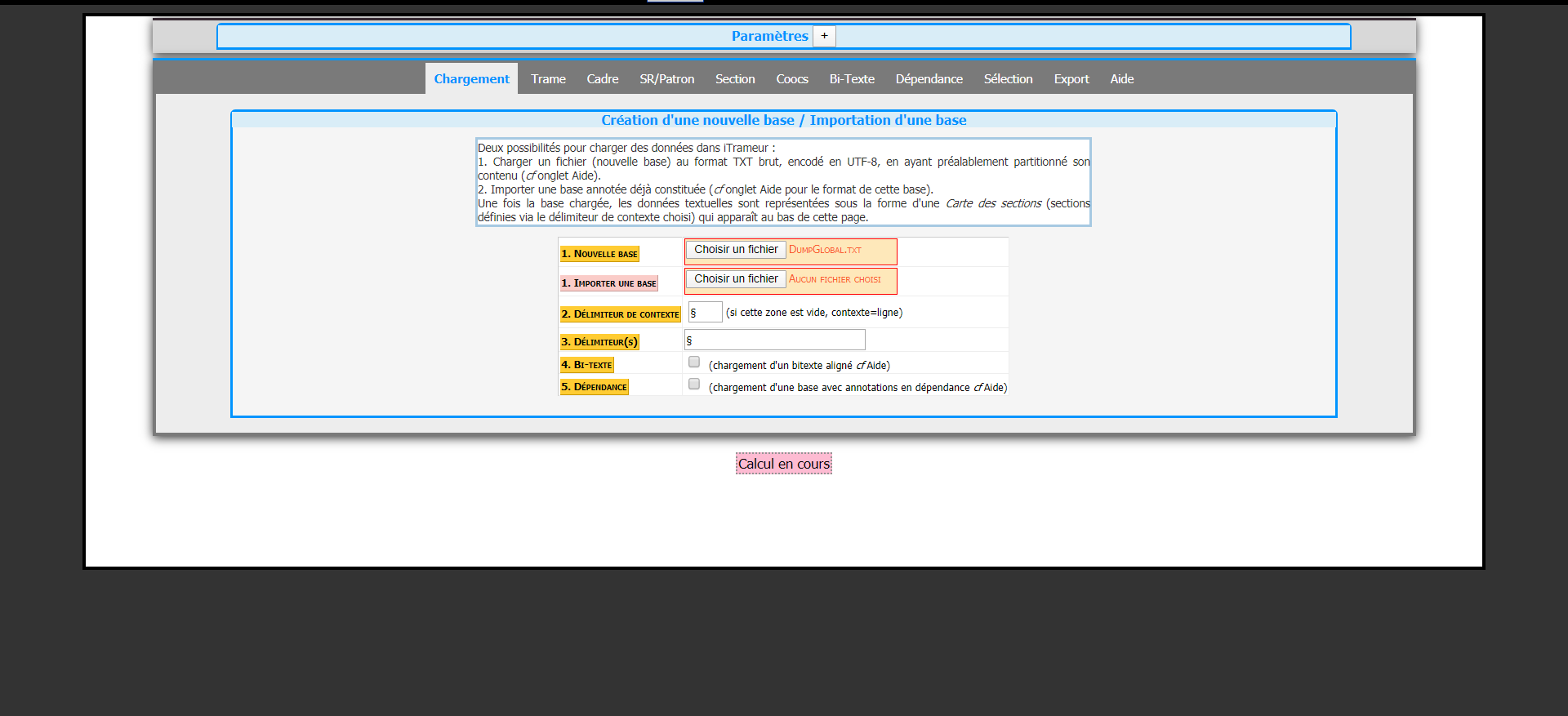
Analyse des corpus
On commence par charger le corpus qui doit être au préalable en texte brut, encodé en Utf-8 et partionné avant d'être importé dans l'outil. Le trameur effectue ensuite la segmentation.
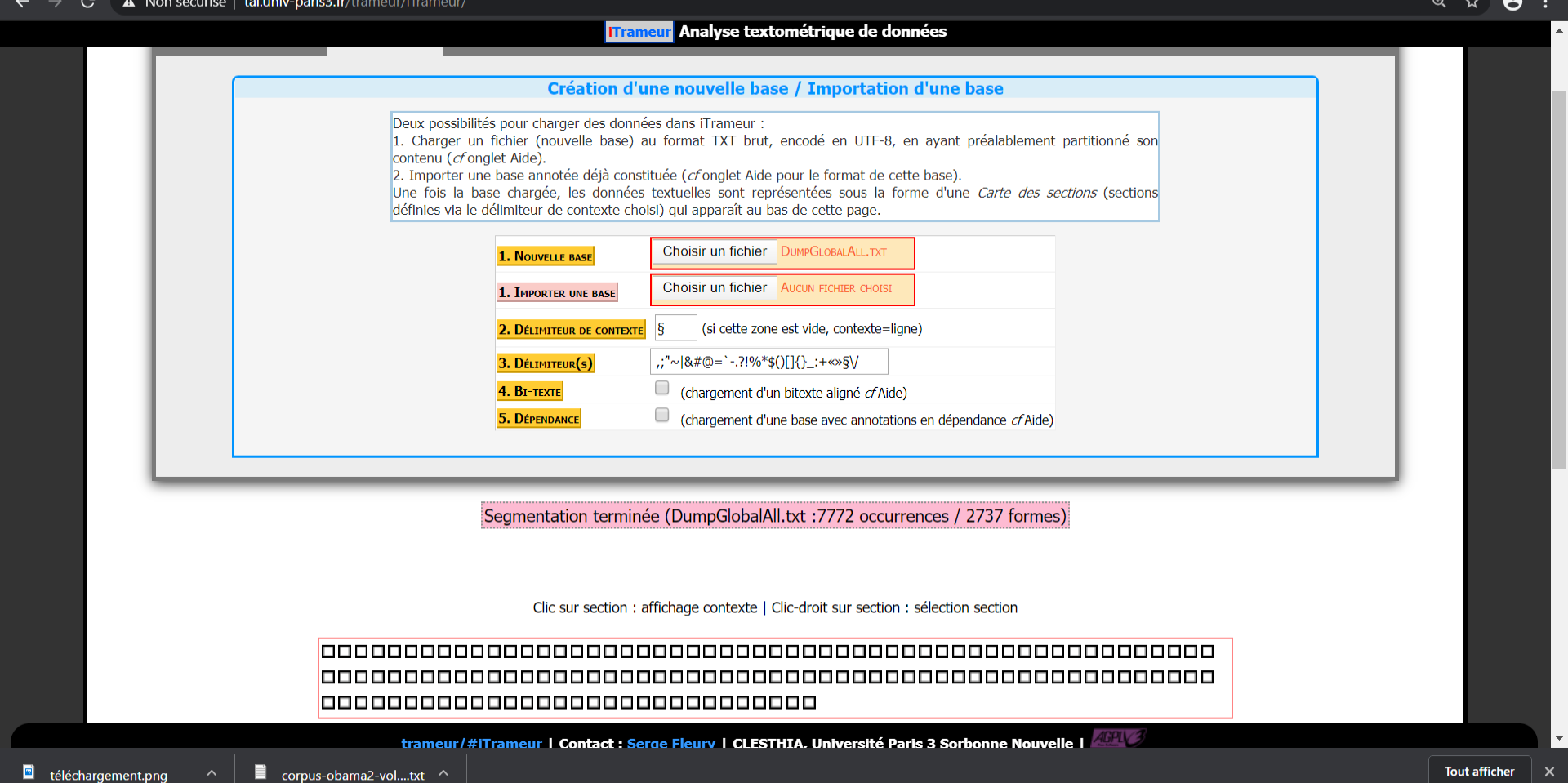
La carte des sections est générée et identifiée par cette de petits carrés. Les carrés rouges correspondent à l'endroit où apparaît l'item choisi, en l'occurence "identität" pour l'allemand.

La carte des sections pour l'anglais :
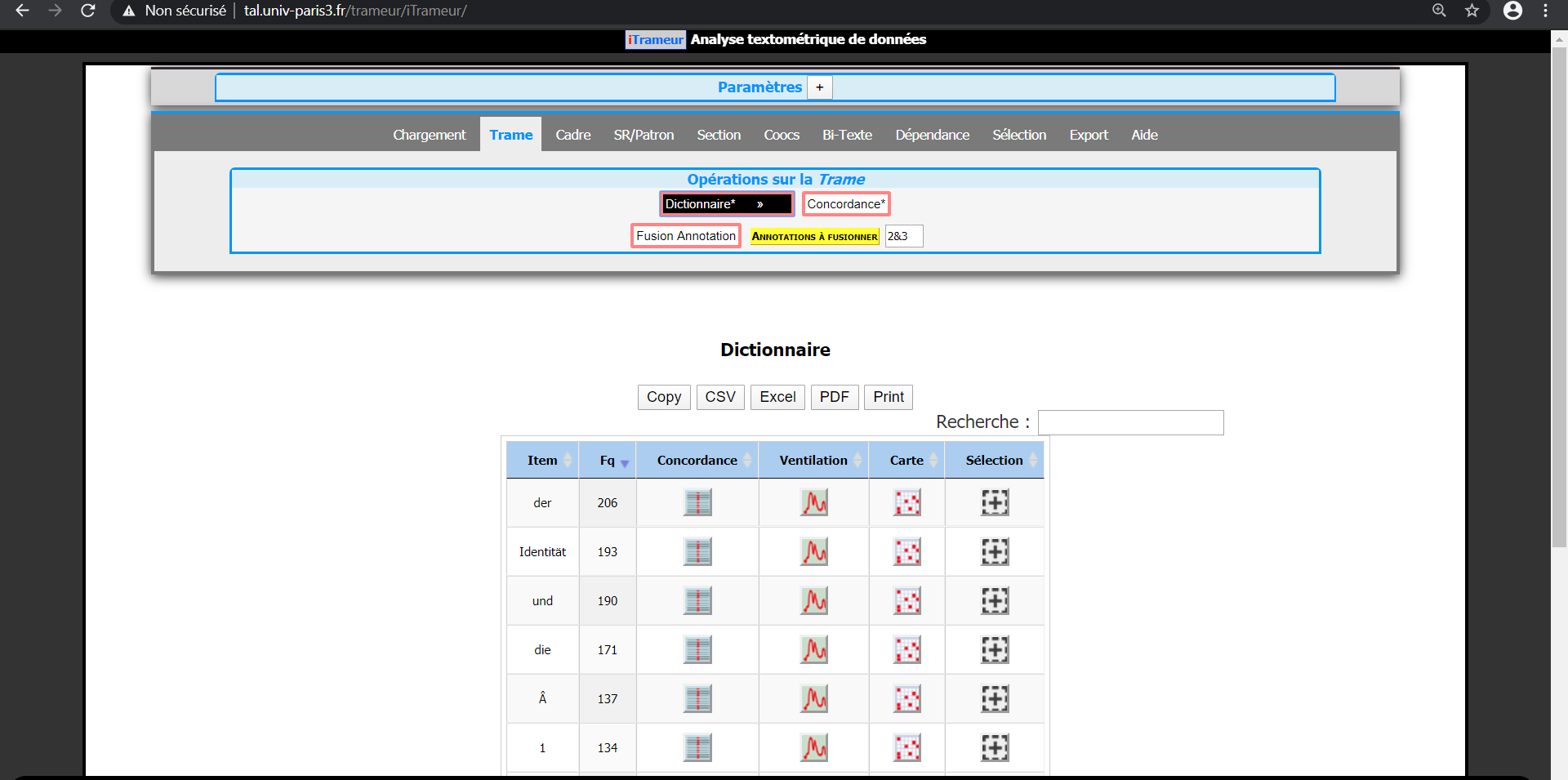
En cliquant sur l'onglet "trame", nous pouvons faire le choix de visualisation d'apparition de l'item choisi : concordance, ventilation ou carte des sections comme ci-dessus.
Le problème qui nous a empêché la première fois d'analyser les corpus, fut leur poid généré par l'aspiration multiple des urls, ce qui a donné lieu a beaucoup de doublons, voire de triplons. Il a donc fallu nettoyer manuellement les dumps et les contextes afin de donner au trameur des fichiers qu'il puisse supporter.
Avant le nettoyage :
Un éternel "calcul en cours" s'affichait sans grand espoir de voir au moins la carte des sections.
Maintenant les résultats sont plus faciles à être généré !
Nous trouvons 7772 occurrences / 2737 formes pour l'allemand et 1975 occurrences / 797 formes pour l'anglais.
Le réseau cooccurrents pour l'allemand et l'anglais :
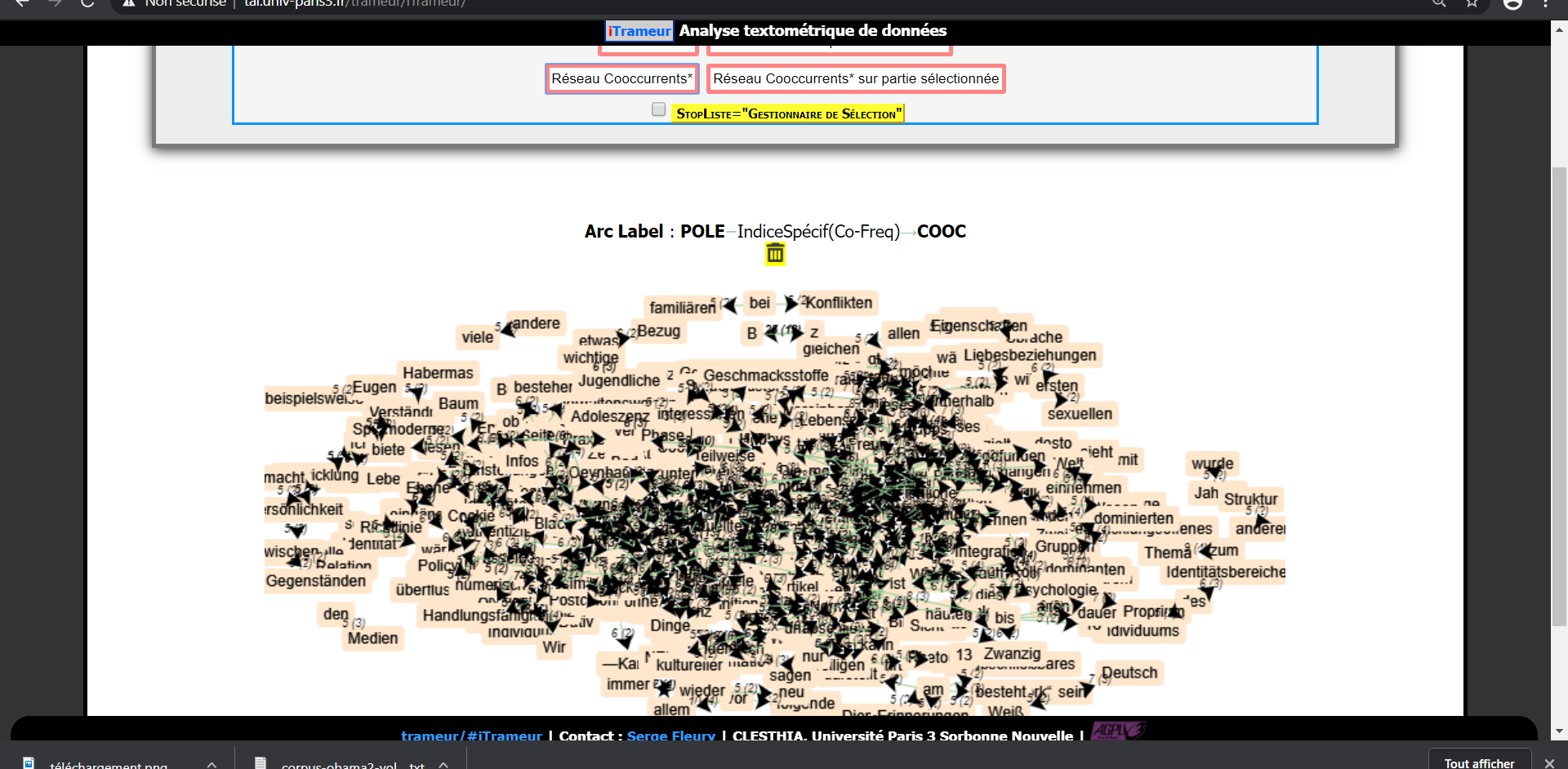
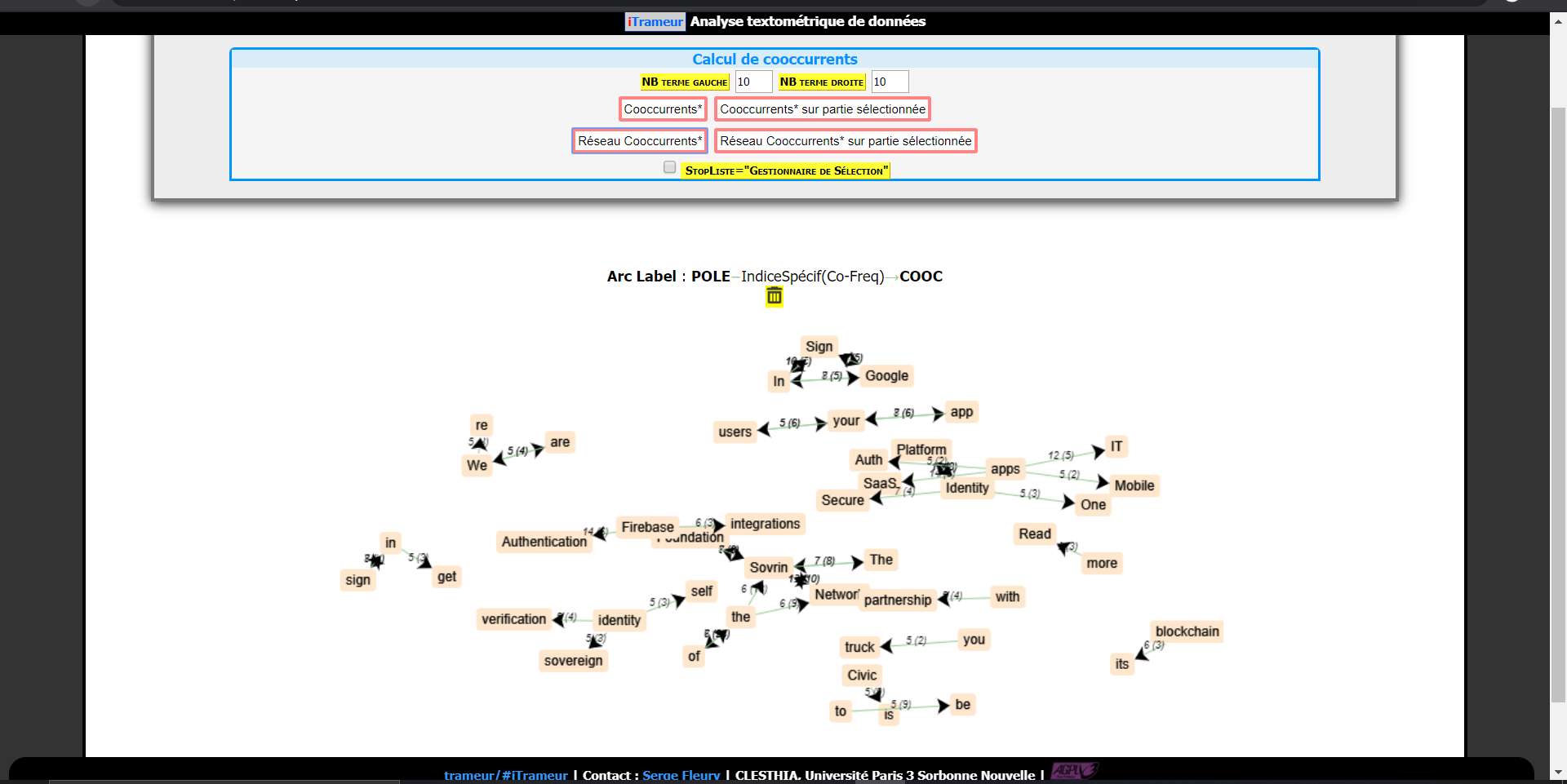
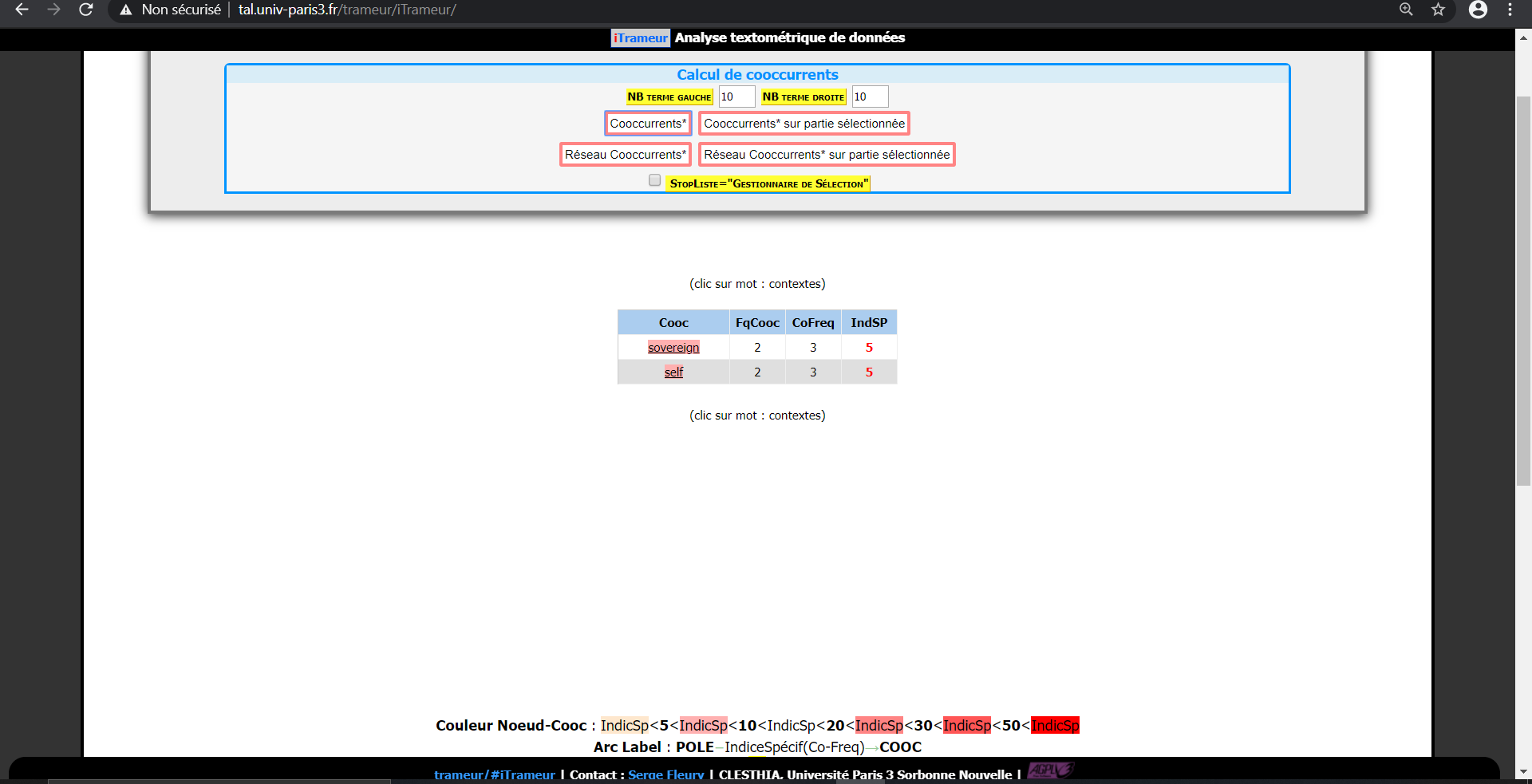
Les cooccurrents particuliers



La ventilation
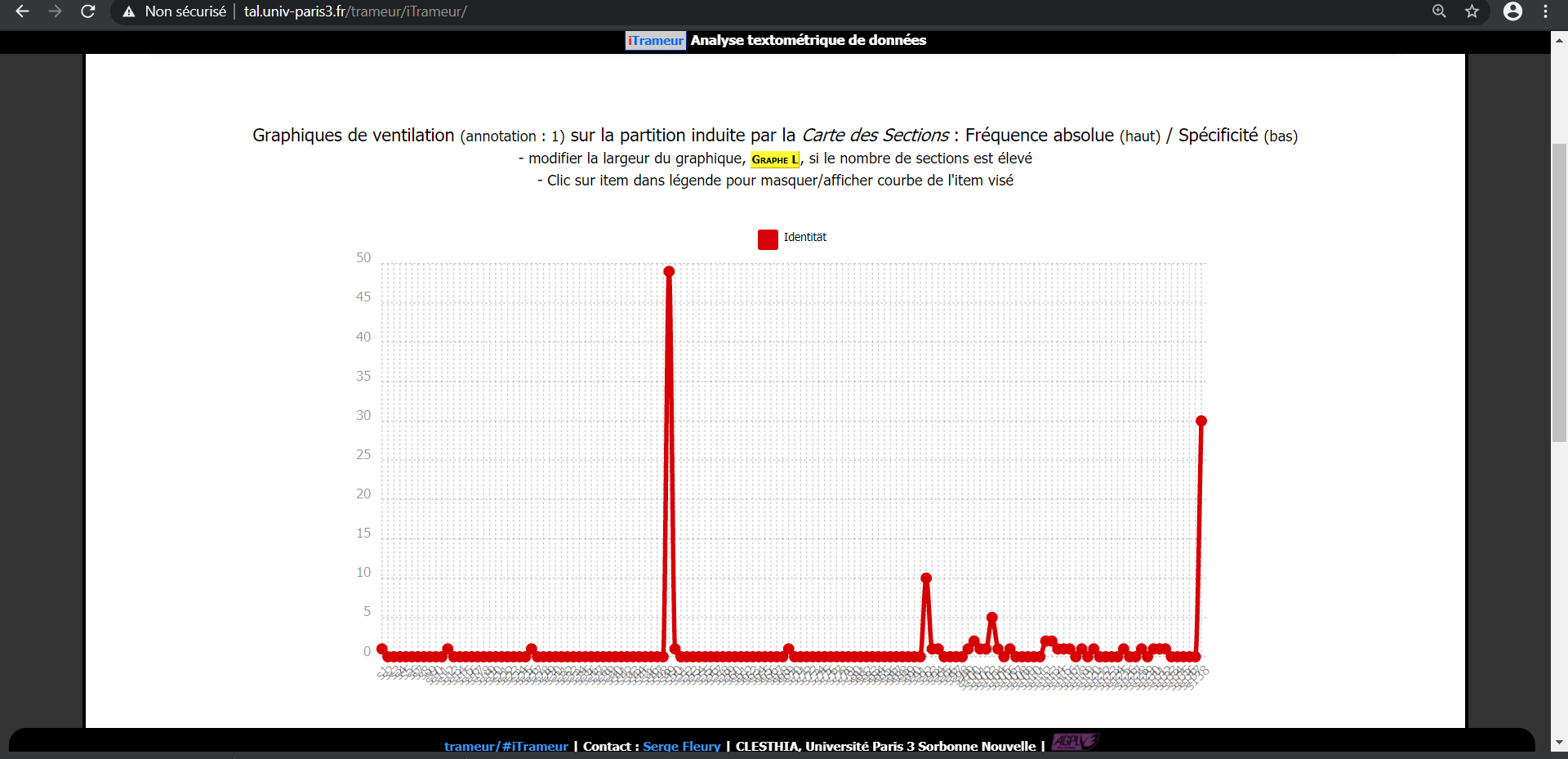
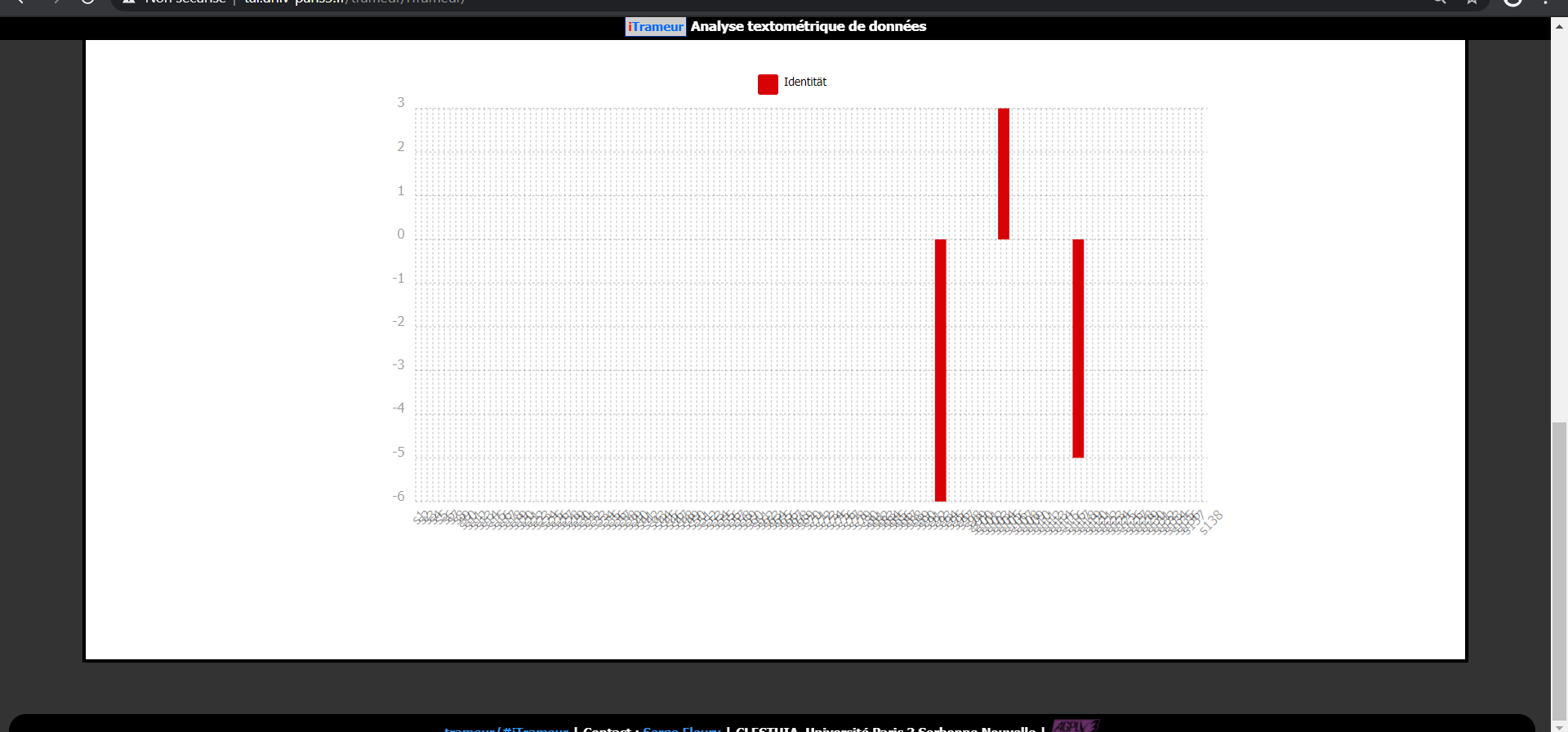
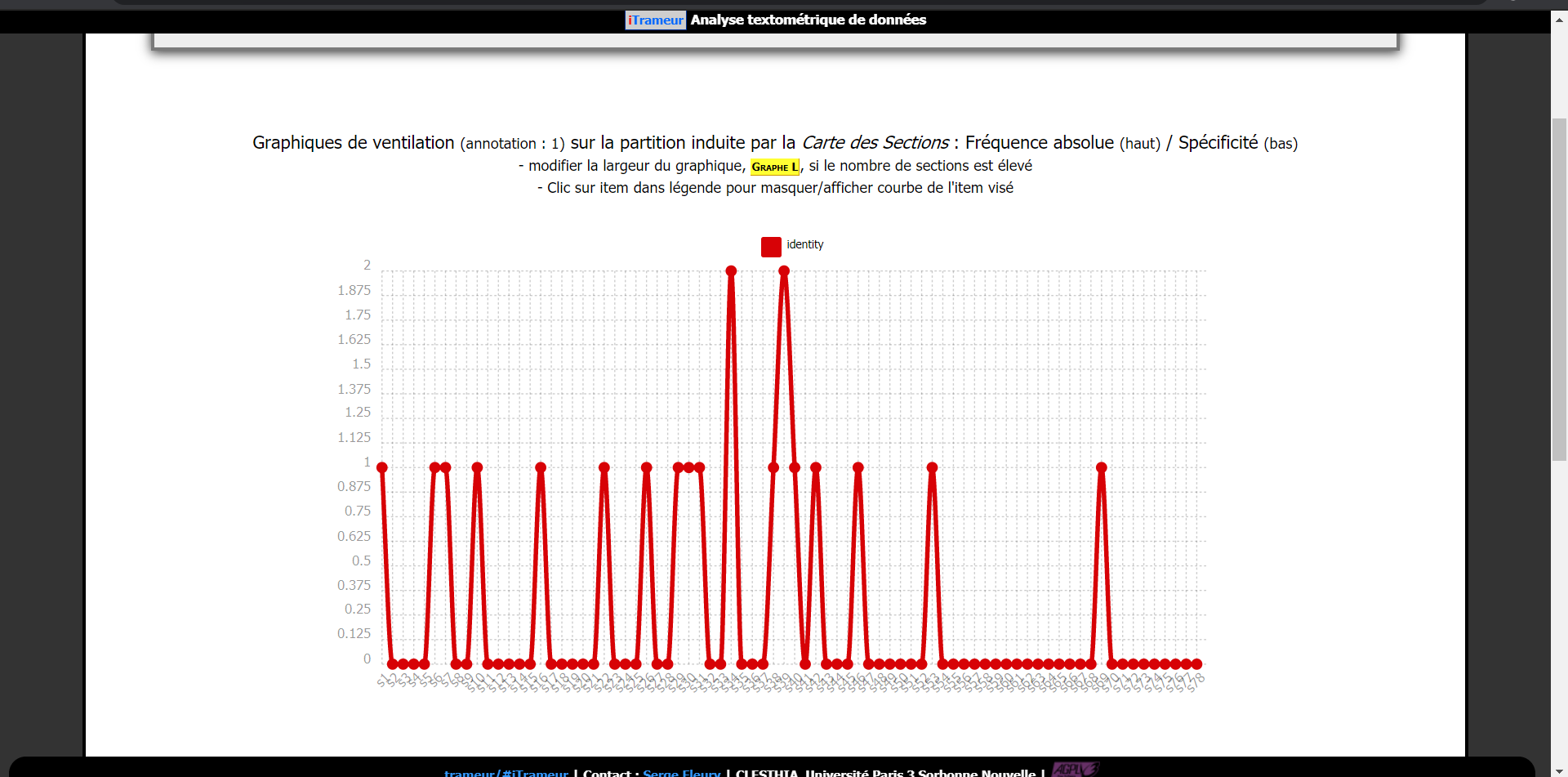
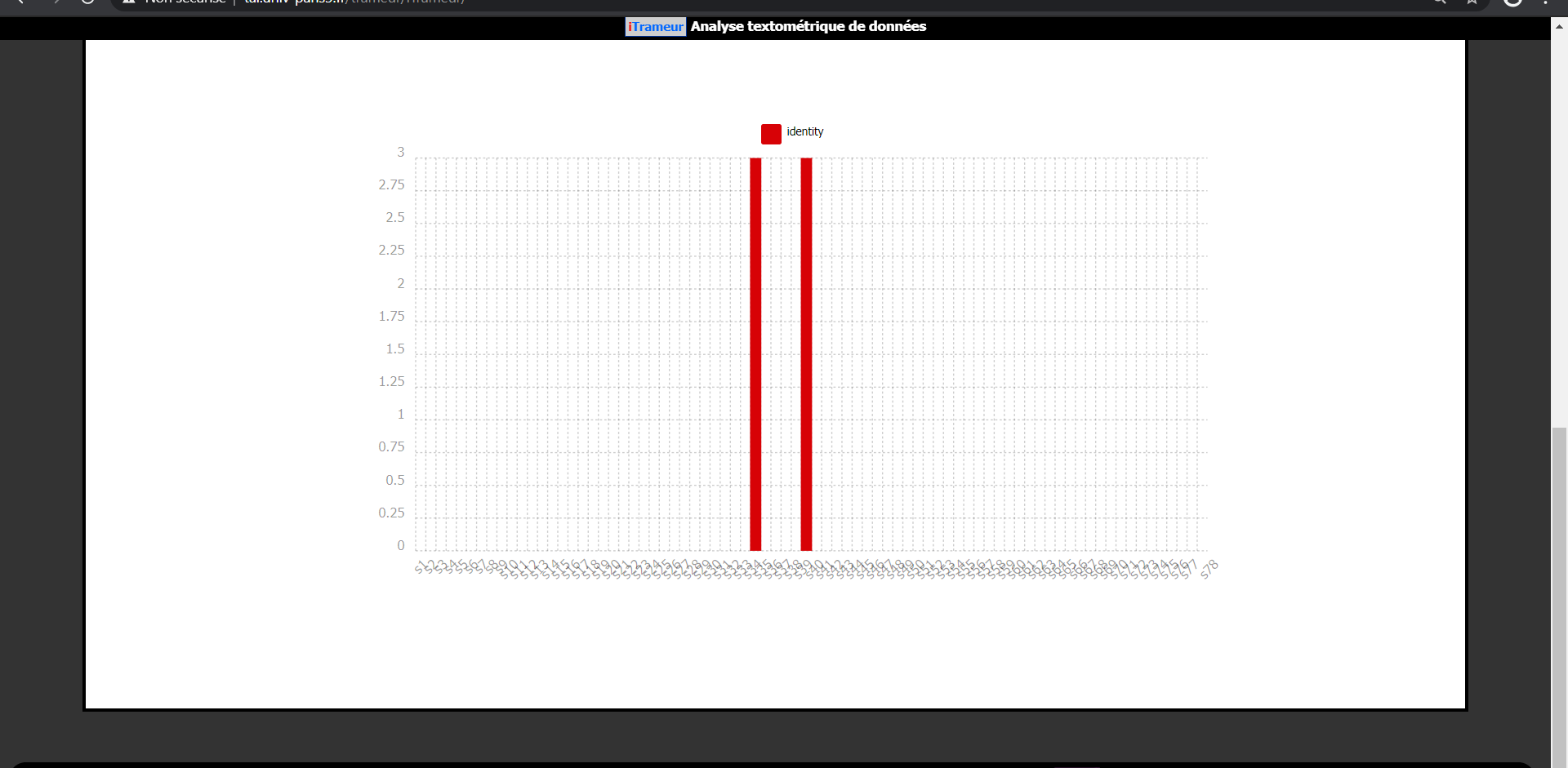
Le bruit fortement répandu au sein des corpus et l'absence d'un affinement de ces derniers qui aurait été nécessaire, empêchent d'apporter une analyse réellement pertinente du fait des doublons et triplons retrouvés au sein des urls aspirées.
Certes, on observe une fréquence plus importante sur le terme allemand mais cela ne traduit rien de vraiment pertinent. Alors, est-ce le fait d'avoir pour l'allemand,utilisé des meta-moteurs spécifiques au lieu d'un seul moteur de recherche classique de type bing ? Cela reste incertain.
Néanmoins, on peut percevoir que le terme identité en allemand revient souvent associé à l'identité culturelle, politique, tout ce que tourne autour de la "cité" au sens grecque, tandis que la version anglaise est plus associée à l'identité numérique, aux nouvelles technologie etc..
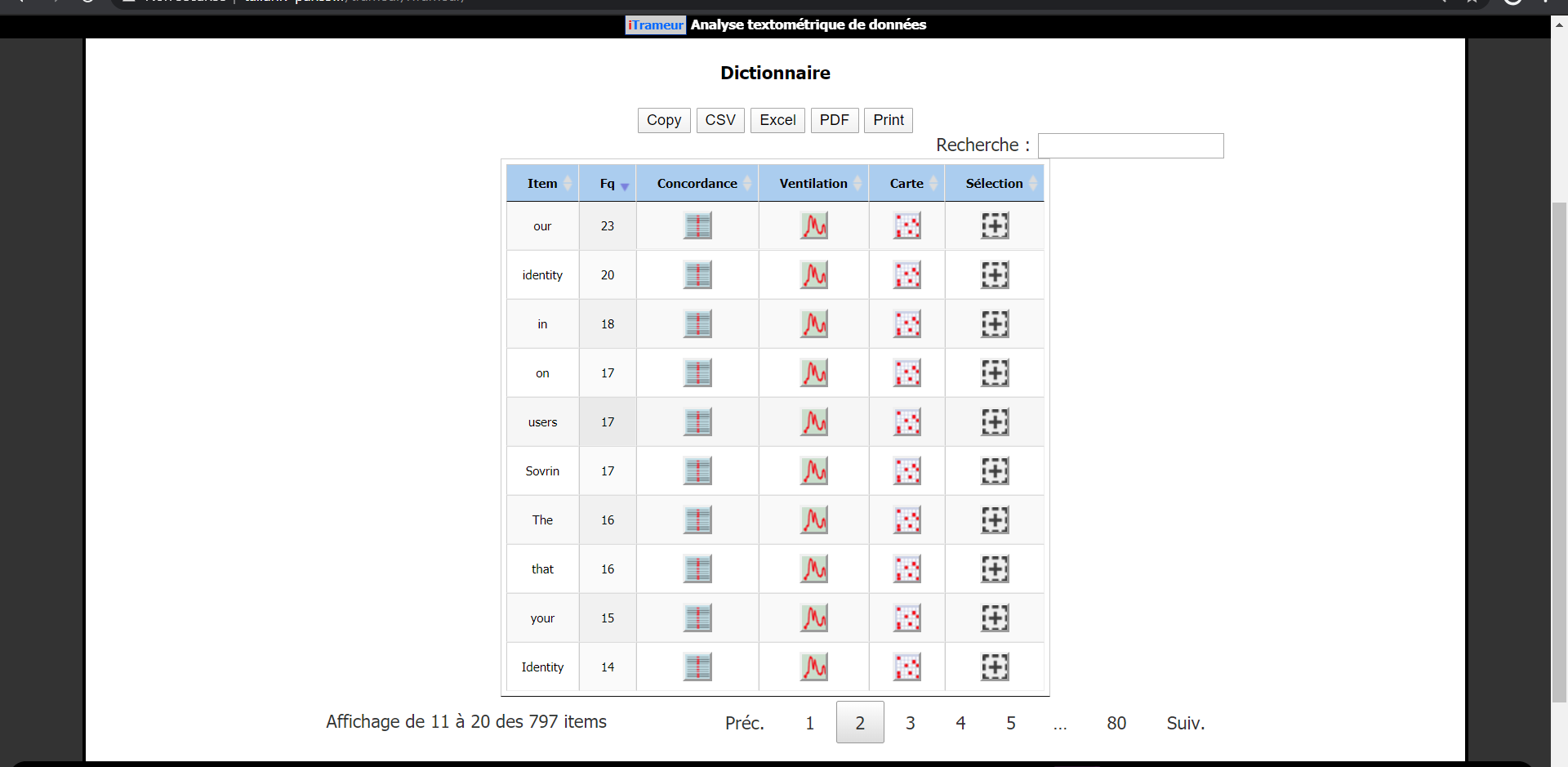
Pour l'allemand, voir plus au-dessus.
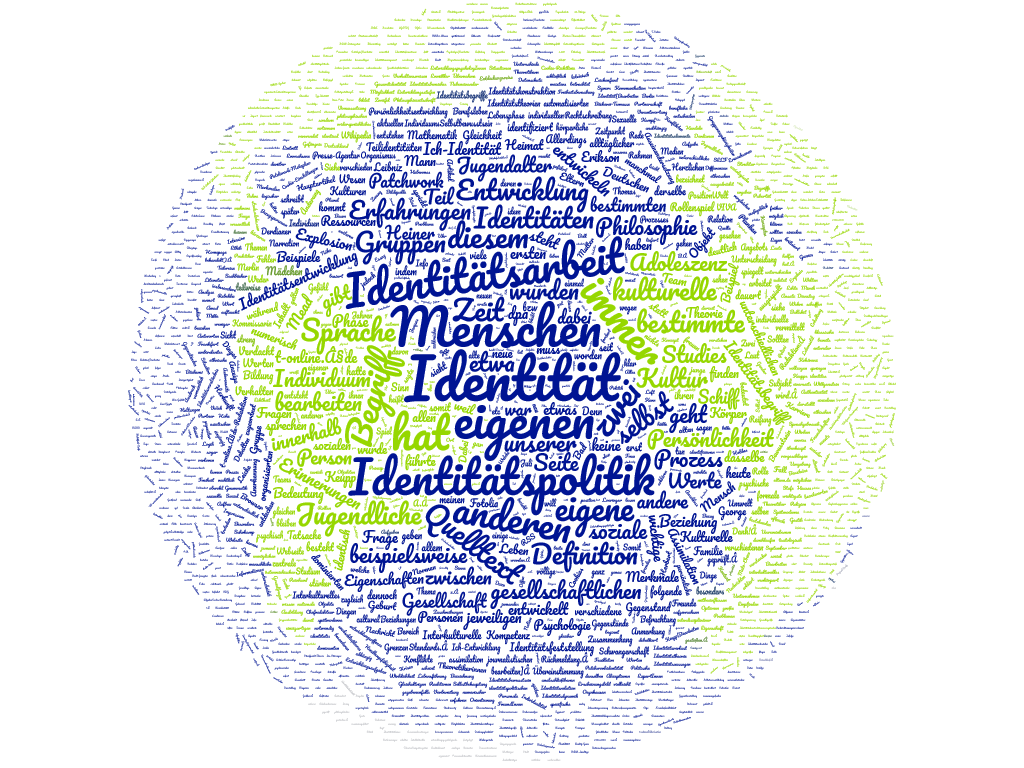
Les nuages de mots
Les nuages de mots sont des structures à la fois textuelles et iconographiques permettant d'afficher la fréquence des termes existant au sein des fichiers dump concaténés.
Ce qui était évoqué plus haut concernant la nature du champ lexical pour le terme identité en allemand et en anglais, est particulièrement bien mis en valeur par les nuages.



Ainsi s'achève ce premier projet encadré !