Nous avons utilise le logiciel iTrameur pour effectuer des analyses textométriques, notamment trouver les réseaux de coocurrents autour de nos mots étudiés.
Les résultats sont présentés ci dessous pour chaque langue :
Français
Coocurents :
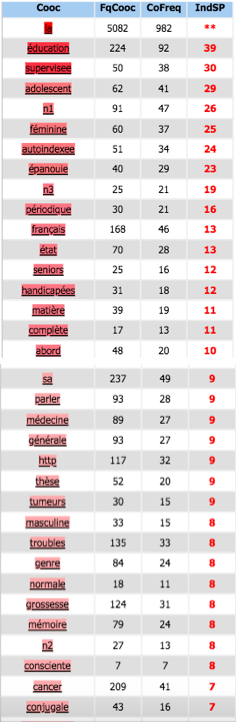
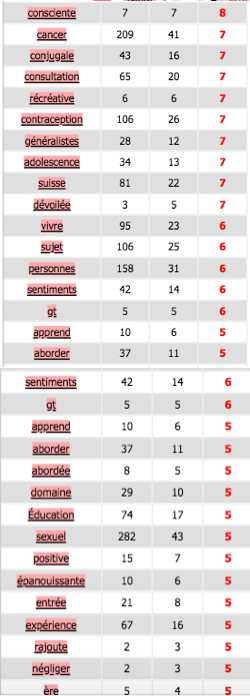
Réseau coocurents :

Anglais
Coocurents :
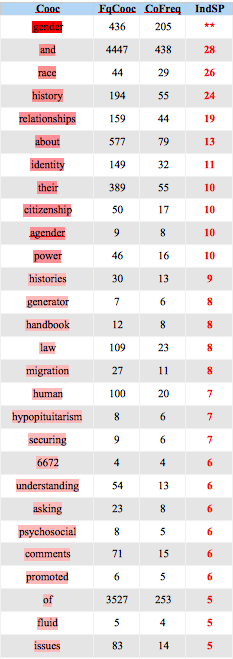
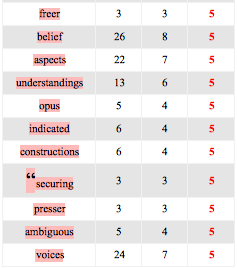
Réseau coocurents :

Arabe
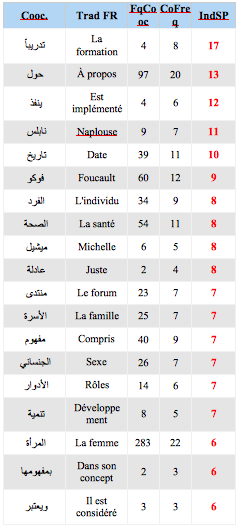
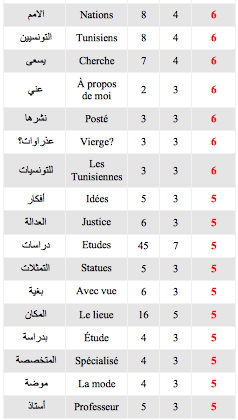
Coocurents :
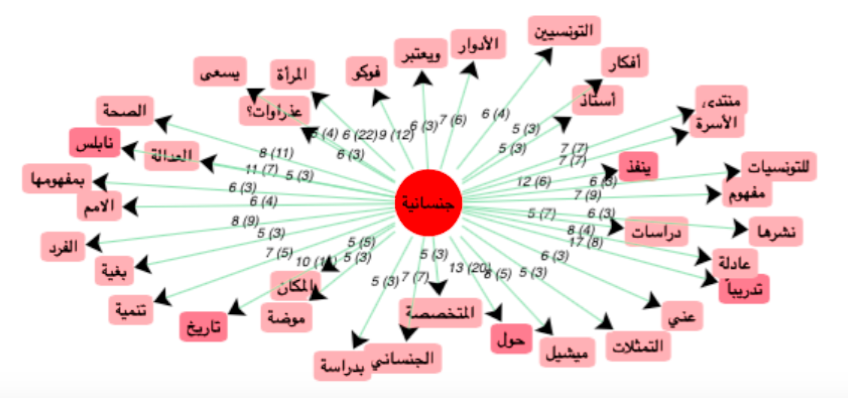
Réseau coocurents :
Russe
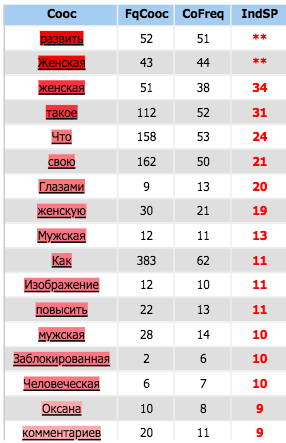
Coocurents :
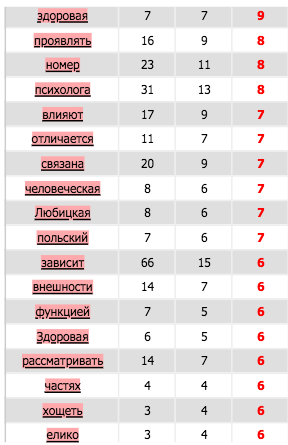
Réseau coocurents :
Japonais
Etude 1 - MOT D'EMPRUNT セクシュアリティー/セクシャリティ -
orthographe 1
Coocurents :
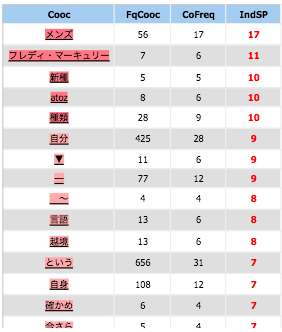
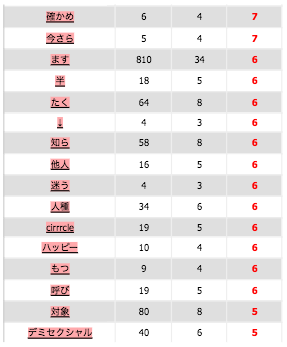
Réseau coocurents :
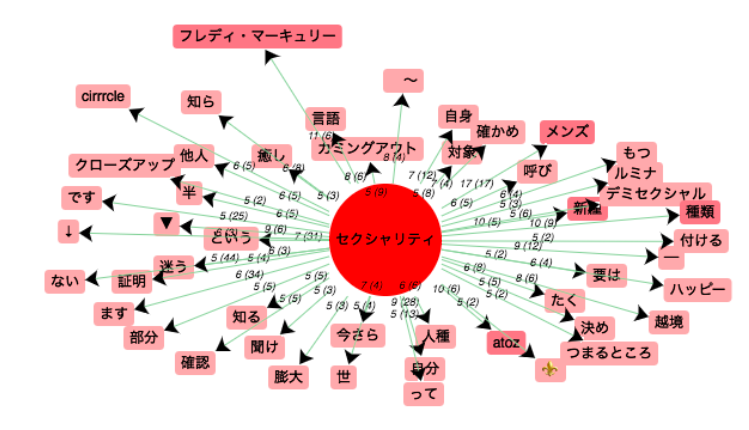
orthographe 2
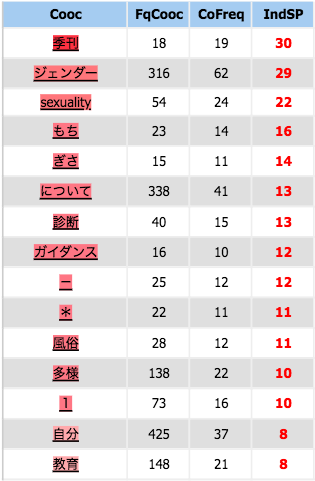
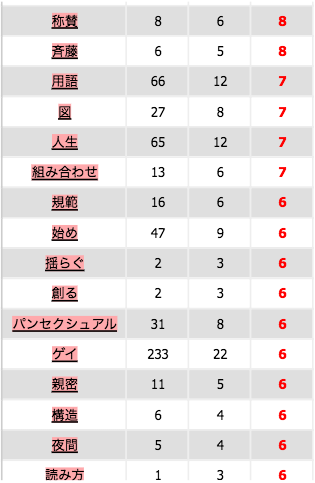
Coocurents :
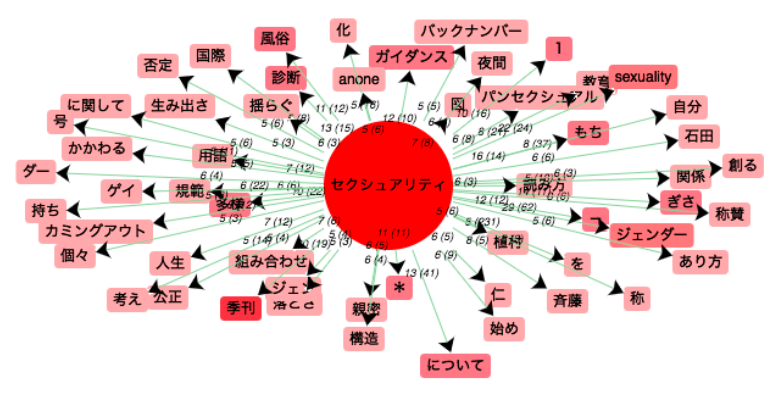
Réseau coocurents :
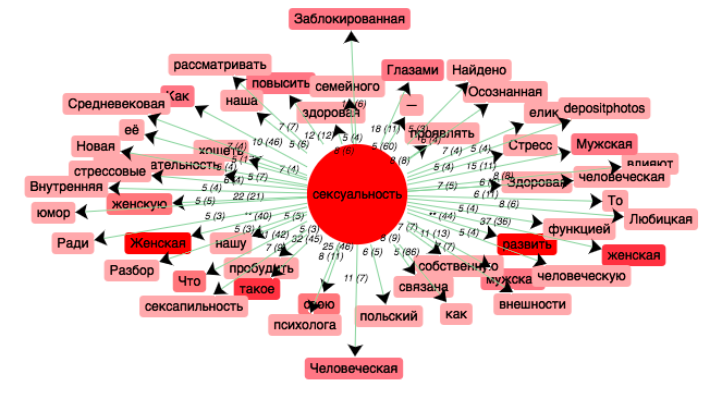
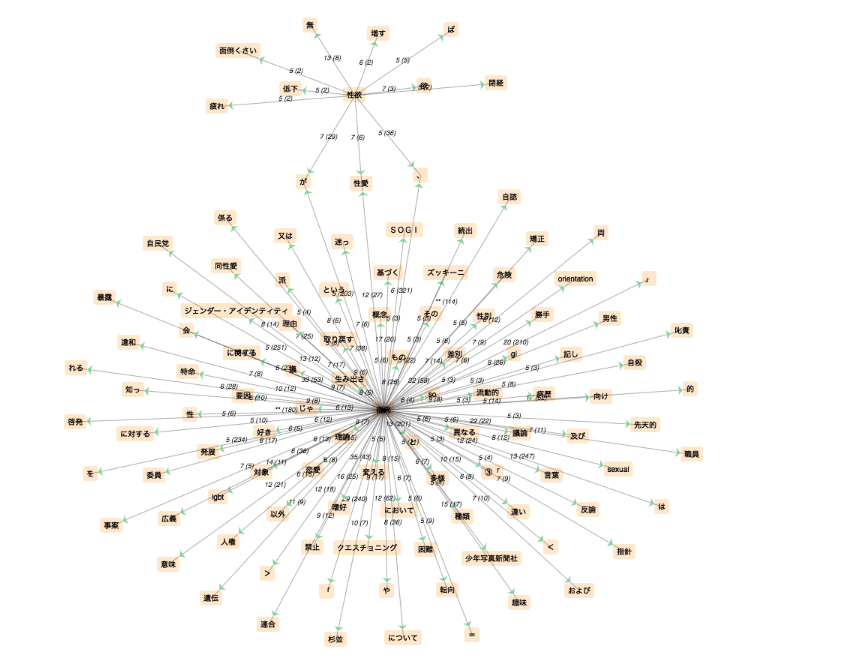
Etude 2 - GROUPE DE MOTS plus "japonais" regroupant ensemble le concept de "sexualité" (vie sexuelle, désir sexuel, orientation sexuel etc)-
Puisqu'il faut analyser un groupe de mots, et pas juste un mot du dictionnaire, à la place des coocurents autour d'un pôle du dictionnaire donné, on analyse ici la fréquence de tous les tokens confondus dans le corpus. On peut voir ça comme des coocurences à l'échelle du texte entier... Par contre pour créer le graphe du réseau de coocurence, la solution a été d'utiliser le lien mis en lignes sur la page du cours qui permet de générer un graphe de coocurences à partir d'une expression régulière.
Coocurents :

Réseau coocurents :
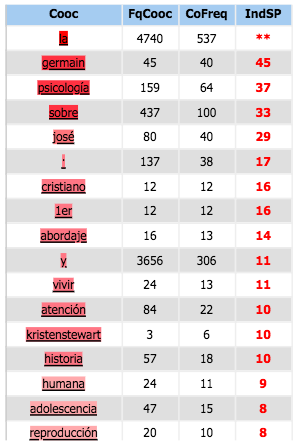
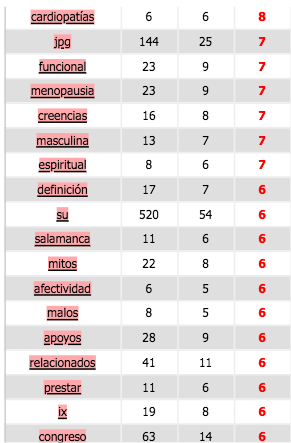
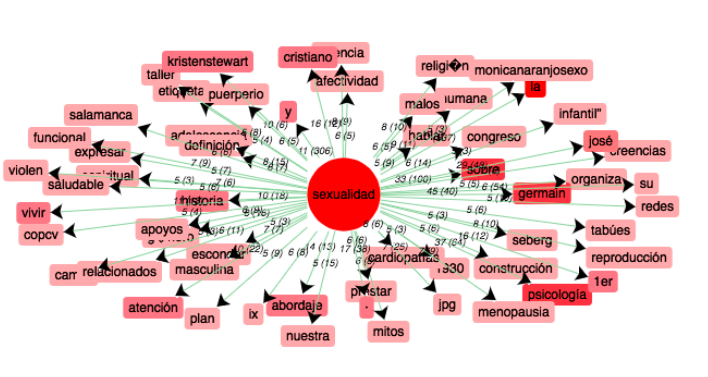
Espagnol
Coocurents :
Réseau coocurents :
Thème remanié par YUDENKOVA Kristina, STRICKLAND Emmett et REY Camille © 2019
A partir de OS Templates