
Scripts
Nous avons au total 4 scripts, un script essentiel pour les textes en chinois, un autre destiné aux autres langues(français, anglais et allemand), un de Python pour lancer le Pkuseg qui sert à segmenter les textes en chinois, et le dernier pour la constitution d’un gros fichier des contextes de chaque langue.
Schéma des scripts principaux pour formuler les tableaux
Répertoire de travail
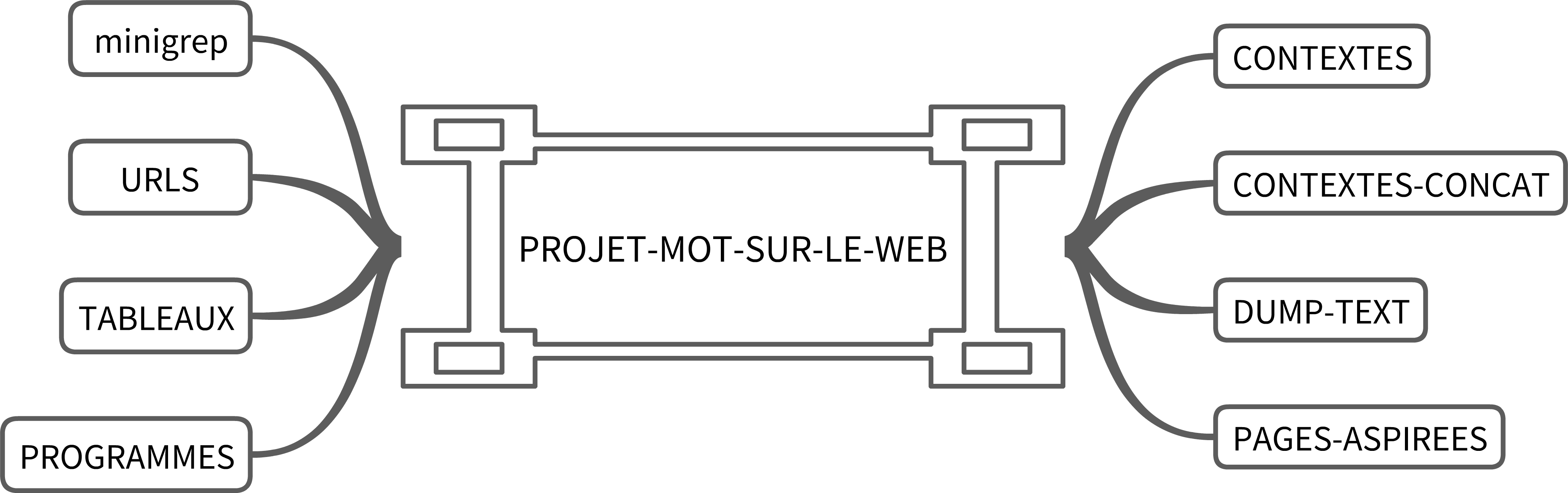
Les scripts sont dans le dossier PROGRAMMES ;
L’outil minigrep est dans le dossier minigrep ;
Les fichiers URLs des quatre langues sont dans le dossier URLS ;
Le tableau final est dans le dossier TABLEAUX ;
Les pages aspirées sont dans le dossier PAGES-ASPIREES ;
Les textes obtenus par curl, les fichiers convertis au UTF-8 s’il faut, les fichiers de bigrammes et d’index sont dans le dossier DUMP-TEXT ;
Les contextes du motif sont dans le dossier CONTEXTES ;
Les script :
- Les scripts essentiels (bash shell)
- Python
- Gros fichier (bash shell)
Argument 1 : le fichier d'URLs concerné
Argument 2 : chemin vers le dossier devant contenir le fichier HTML final
Argument 3 : la langue concerné (FR/CH/EN/DE)
Argument 4 : le motif
./minigrep/parametre-motif_chinois/autres : MOTIF= le mot qui nous intéresse
Pour lancer, exemple :
bash ./PROGRAMMES/autres.sh ./URLS/URLs_FR.txt "FR" "TGV"
Traitement des URLs en chinois
Traitement des URLs en d’autres langues
Segmentation du chinois, qui s’emploie avec le script chinois.sh