
Extraction (filtrage, nettoyage) de fils RSS grâce à un script Perl.
Objectif et déroulement :
Après avoir reçu en argument un dossier, le script va procéder comme suit :
- Parcours de l'arborescence du dossier entré en argument à la recherche de fichiers xml contenant l'indice fourni par la rubrique choisie.
- Pour chaque fichier, en extraire les items (qui correspondent aux articles).
- Pour chaque item :
- nettoyer le titre et la description,
- vérifier qu'on ne l'a pas déjà noté. Si oui, passer.
- si non:
- enrichir les informations (index, date...).
- l'écrire dans nos fichiers (txt et xml).
À la fin, nous aurons donc un fichier txt contenant les titres et descriptions, et un fichier XML avec ces articles, mais aussi légérement enrichi.
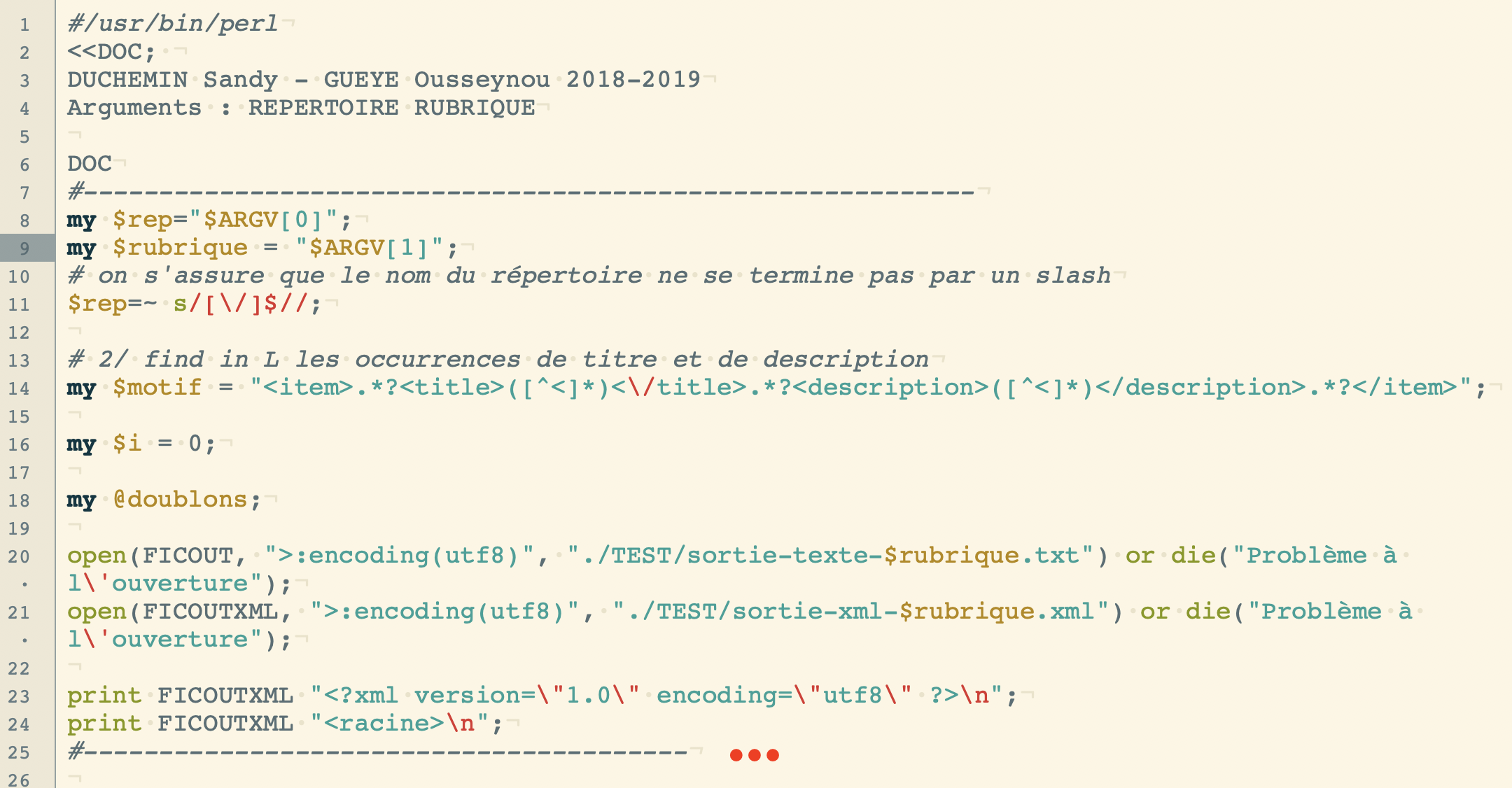
Code :
Résultats :
Les résultats de cette BaO seront directement utilisés dans la BaO2. Il n'y a donc pas utilité de les afficher ici.