

Boîte à outils 2
Etiquetage morphologie-syntaxique
TreeTagger :
Nous passons à la deuxième étape de la chaîne de traitement. Nous avons enrichi notre dernier script perl utilisé dans BaO1 avec un fonction étiquetage par TreeTagger.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 | #/usr/bin/perl use utf8; use HTML::Entities; <<DOC; Votre Nom : ALKHADHAR Noor et HERNANDEZ Madeleine JANVIER 2017 usage : perl parcours-arborescence-fichiers repertoire-a-parcourir Le programme prend en entrée le nom du répertoire contenant les fichiers à traiter Le programme construit en sortie un fichier structuré contenant sur chaque ligne le nom du fichier et le résultat du filtrage : <FICHIER><NOM>du fichier</NOM></FICHIER><CONTENU>du filtrage</CONTENU></FICHIER> DOC #----------------------------------------------------------- my $rep="$ARGV[0]"; my $rubrique = "$ARGV[1]"; my %dico; # on s'assure que le nom du répertoire ne se termine pas par un "/" $rep=~ s/[\/]$//; # on initialise une variable contenant le flux de sortie #---------------------------------------- my $output0="$rubrique.txt"; if (!open (FILEOUT,">$output0")) { die "Pb a l'ouverture du fichier $output0"}; close(FILEOUT); my $output1="$rubrique.xml"; if (!open (FILEOUT,">$output1")) { die "Pb a l'ouverture du fichier $output1"}; print FILEOUT "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n"; print FILEOUT "<PARCOURS>\n"; print FILEOUT "<NOM>ALKHADHAR - HERNANDEZ</NOM>\n"; print FILEOUT "<FILTRAGE>\n"; close (FILEOUT); #---------------------------------------- &parcoursarborescencefichiers($rep); # on lance la récursion #---------------------------------------- open (FILEOUT,">>:encoding(utf-8)", $output1); print FILEOUT "</FILTRAGE>\n"; print FILEOUT "</PARCOURS>\n"; close(FILEOUT); exit; #---------------------------------------------- sub parcoursarborescencefichiers { my $path = shift(@_); opendir(DIR, $path) or die "can't open $path: $!\n"; my @files = readdir(DIR); closedir(DIR); foreach my $file (@files) { next if $file =~ /^\.\.?$/; next if $file =~ /^\._/; next if $file =~ /^fil/; $file = $path."/".$file; if (-d $file) { print "<NOUVEAU REPERTOIRE> ==> ",$file,"\n"; &parcoursarborescencefichiers($file); # recursion print "<FIN REPERTOIRE> ==> ",$file,"\n"; } if (-f $file) { if ($file =~ /$rubrique.+\.xml$/) { print "<",$i++,"> ==> ",$file,"\n"; $codage = "utf-8"; open (FIC, "<:encoding($codage)", $file); open (OUT0, ">>:encoding($codage)", "$rubrique.txt"); open (OUT1, ">>:encoding($codage)", "$rubrique.xml"); #ramener tout le flux textuel de FIC sur une seule ligne my $texte=""; while (my $ligne = <FIC>) { chomp $ligne; $ligne =~ s/\r//g; $texte = $texte . $ligne; } close FIC; $texte =~ s/>\s+</></g; $texte = decode_entities($texte); while ($texte =~ /<item>.*?<title>(.+?)<\/title>.*?<description>(.+?)<\/description>/g) { my $titre = $1; my $description = $2; # $titre.="."; # $titre=~s/<.+?>//g; # $titre=~s/\?\.$/\?/; # $description=~s/<.+?>//g; if (!(exists $dico{$titre})) { $dico{$titre} = 1; my ($titretag,$descriptiontag) = &etiquetage($titre,$description); print OUT0 "$titre\n"; print OUT0 "$description\n\n"; print OUT1 "<item>\n<title>$titretag</title>\n<description>$descriptiontag</description>\n</item>\n\n"; } } close OUT0; close OUT1; # fin de traitement du fichier } } } } sub etiquetage { my ($t,$d)= @_; open(TMP0,">>:encoding(utf8)","titre.txt"); print TMP0 "$t.\n"; close TMP0; system("perl tokenise-utf8.pl titre.txt | tree-tagger.exe -token -lemma -no-unknown french-utf8.par > titre_tag.txt"); system("perl treetagger2xml-utf8.pl titre_tag.txt utf8"); #résultat est contenu dans titre_tag.txt.xml open(TMP1, "<:encoding(utf8)","titre_tag.txt.xml"); my $t_tag=""; my $ligne = <TMP1>; while (my $ligne = <TMP1>) { #chomp $ligne; $t_tag = $t_tag . $ligne; } close TMP1; open(TMP0,">>:encoding(utf8)","description.txt"); print TMP0 "$d\n"; close TMP0; system("perl tokenise-utf8.pl description.txt | tree-tagger.exe -token -lemma -no-unknown french-utf8.par > description_tag.txt"); system("perl treetagger2xml-utf8.pl description_tag.txt utf8"); #résultat est contenu dans description_tag.txt.xml open(TMP1, "<:encoding(utf8)","description_tag.txt.xml"); my $d_tag=""; my $ligne = <TMP1>; while (my $ligne = <TMP1>) { #chomp $ligne; $d_tag = $d_tag . $ligne; } close TMP1; return($t_tag,$d_tag); } #---------------------------------------------- |
un fichier XML contenant les titres et descriptions de la rubrique passée en argument, étiquetés par TreeTagger
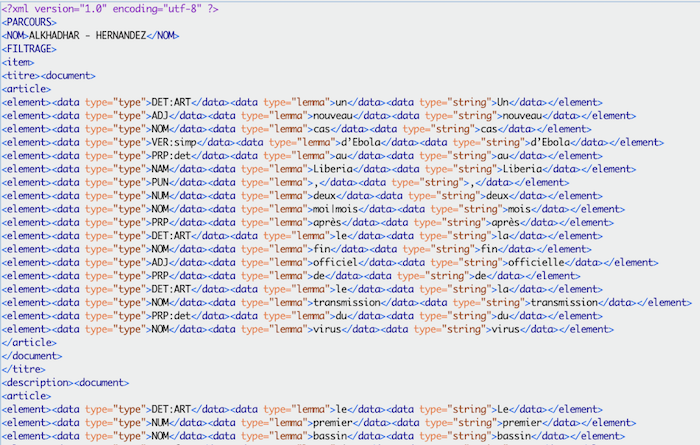
un fichier TXT contenant les titres et descriptions —> ce fichier sera utilisé pour l’étiquetage avec le logiciel Cordial

un fichier XML contenant seulement les titres étiquetés par TreeTagger
son fichier TXT correspondant
un fichier XML contenant seulement les descriptions étiquetées par TreeTagger
son fichier TXT correspondant
un fichier TXT ccontenant seulement les titres
un fichier TXT contenant seulement les descriptions
Selon nos objectifs de travail, nous n’aurons pas forcément l’utilité de tous ces fichiers. Il suffirait de modifier légèrement le script dans le corps de la fonction étiquetage pour modifier les fichiers produits.
En ce qui concerne ce projet, nous allons nous servir des deux premiers : le fichier XML avec les titres et descriptions étiquetées par TreeTagger, ainsi que le fichier TXT avec les titres et descriptions qui sera, par la suite, le fichier d’entrée du logiciel Cordial pour l’étiquetage.
L’étiquetage par TreeTagger se présente de cette manière pour chaque token : <element><data type="type">DET:ART</data><data type="lemma">le</data><data type="string">la</data></element>
D’abord la catégorie morpho-syntaxique, ensuite le lemme, et le token en troisième position.
Cordial :
