Extraction de la surface et la profondeur des fils RSS sur le corpus 2015
Nous sommes ici à la première étape de notre projet qui consiste à écrire 2 scripts : 1 en Purperl et l'autre en utilisant la bilbliothèque XML::RSS. Ces deux scripts devront dans un premier temps parcourir l'aborescence de fils rss 2015 pour ressortir la surface (titre et description); Et dans un deuxième temps la profondeur qui est le contenu. Le principe de la procédure de parcours est que étant donné des fichiers rangés dans plusieurs dossiers classés par mois si le programme tombe sur un répertoire il continue le parcours de l'arborescence si c'est un fichier il le traite et tout ça de manière récursive jusqu'à ce qu'il est parcouru toute l'arborescence.
1- PURPERL
Dans un premier temps, nous allons écrire un script qui parcours notre aborescence 2015 pour nous donner la surface. Après nous le modifierons pour ressortir la profondeur.Voici notre script commenté.
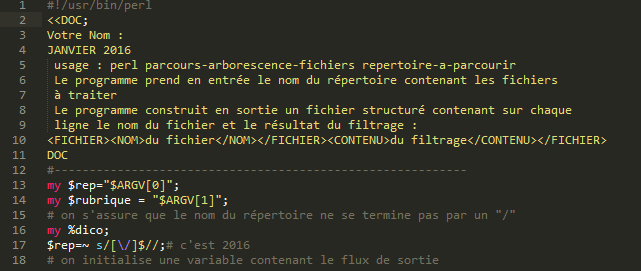
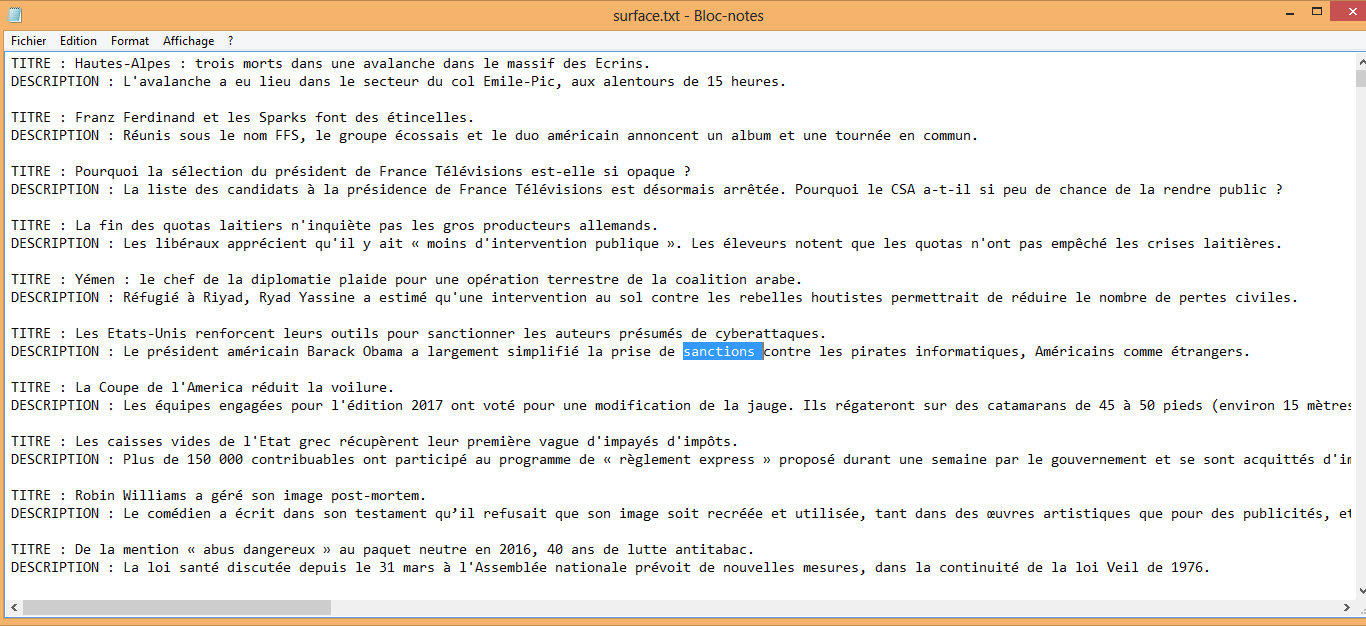
En sortie , nous obtenons deux fichiers : un au format.txt et l'autre au format.xml
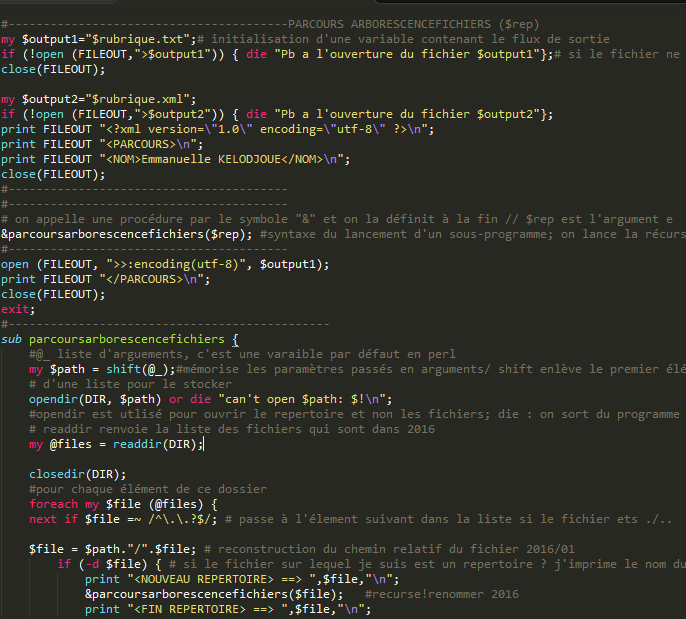
Nous allons donc modifié le SCRIPT 1 pour extraire la profondeur. Nous rajoutons donc ce petit bout ce code dans notre script principal.
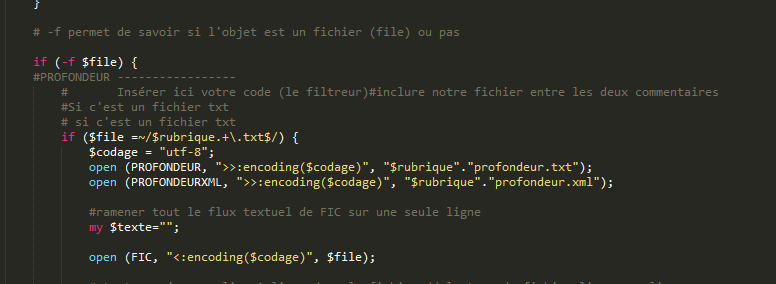
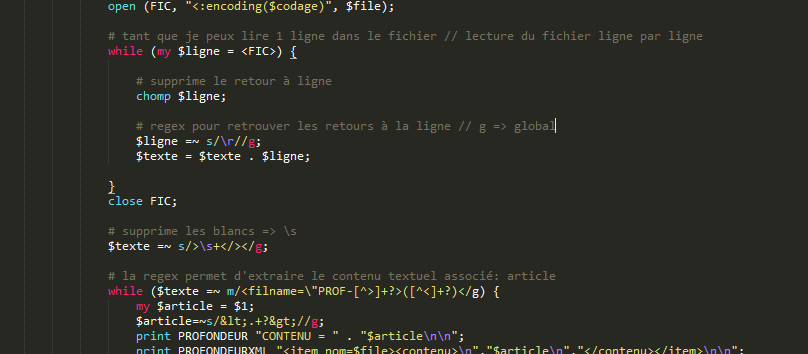
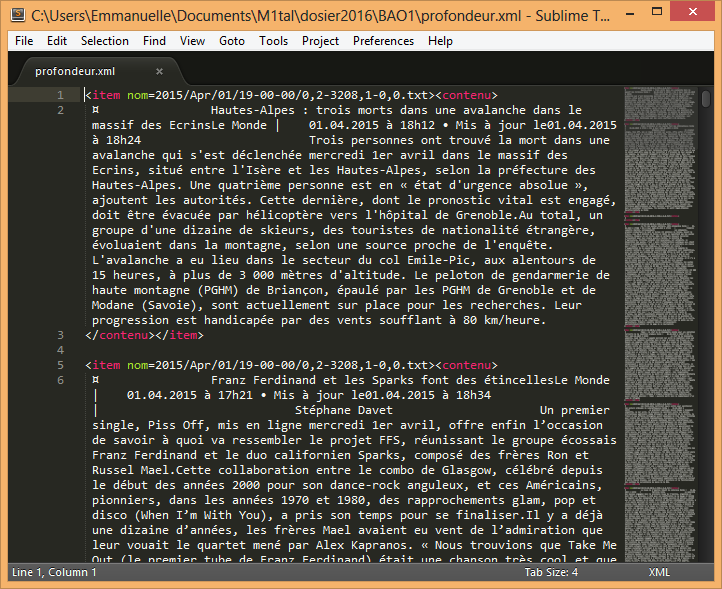
résultat obtenu
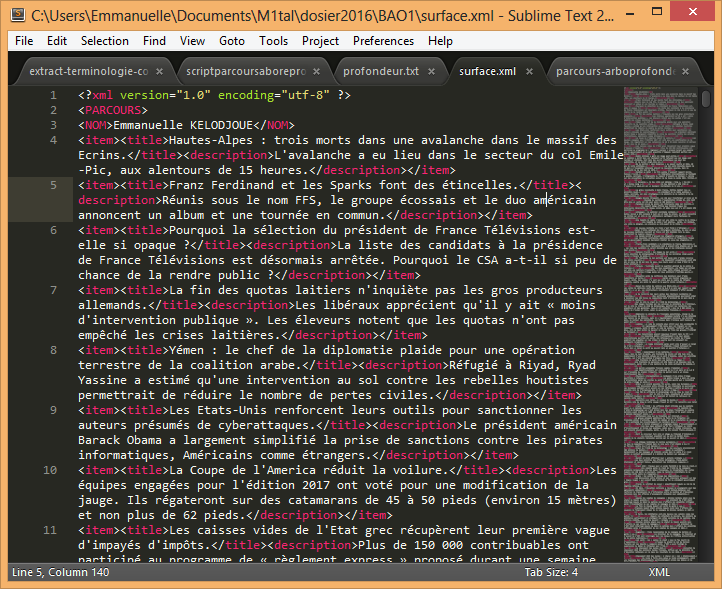
Voici le script en entier en Purpel
| SCRIPT |
2- XML::RSS
Maintenant nous allons écrire la même méthode sauf que nous allons utilisé une bibliothèque de perl : XML::RSS
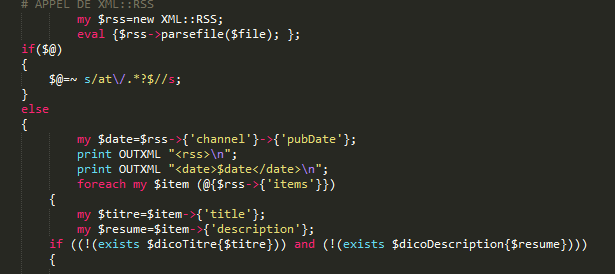
L'extraction avec la bibliothèque XML::RSS des informations prend en compte qu'il s'agit de fichiers XML et par conséquent leur structuration. On créé un tableau associatif qui contient des références vers d'autres références. Une boucle foreach va chercher tous les nœuds sous la balise "items" et pour chaque "item" on va extraire le contenu "title" et "description".
Nous allons donc reprendre notre script et le modifier une nouvelle fois pour ressortir la profondeur et la surface mais via XML::RSS.Nous testerons sur la rubrique 3208.
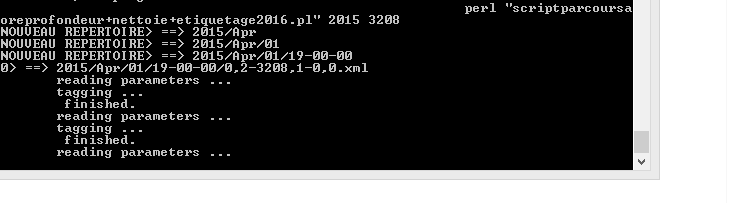
La méthode est presque similaire à celle avec les expressions régulières dans la mesure où il s'agit de parcourir l'arborescence et d'en extraire les titres, les descriptions et les dates. Au lieu d'extraire les contenus à partir d'expressions régulières, on fait des fichiers des objets XML::RSS pour exploiter directement leur structure arborescente.
Une boucle cherche tous les noeuds fils "titre" et "description" des noeuds parents "item" pour les extraire et les stocker dans des variables :
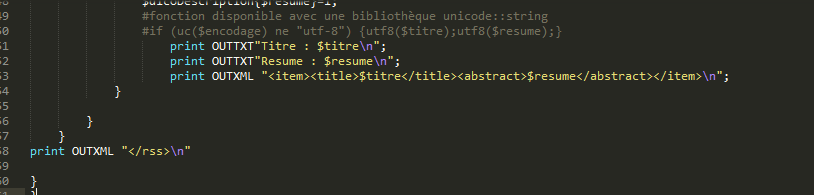
Bien sûr, quel que soit la méthode d'extraction choisie, il y a un résultat TXT et un résultat XML pour tout le corpus et un résultat TXT et un résultat XML pour chaque rubrique.