Graphes
Nous arrivons déjà à la quatrième et dernière boîte à outils de notre projet. Dans celle-ci nous réaliserons des graphes à partir des patrons que nous avons extraits dans la boîte à outils 3.
Pour cela nous utiliserons le programme patron2graphe.exe.
Nous allons le voir, les graphes issus des fichiers étiquetés par Tree-tagger et les fichiers étiquetés par Cordial ne sont pas totalement identiques. En effet, il existe des petites différences entre les deux étiqueteurs qui transparaissent dans les graphes ci-dessous.
Rubrique Cinéma (3476)
Nous avons choisi le motif "films?" pour cette catégorie.
NOM ADJECTIF
A partir des fichiers étiquetés par Cordial :
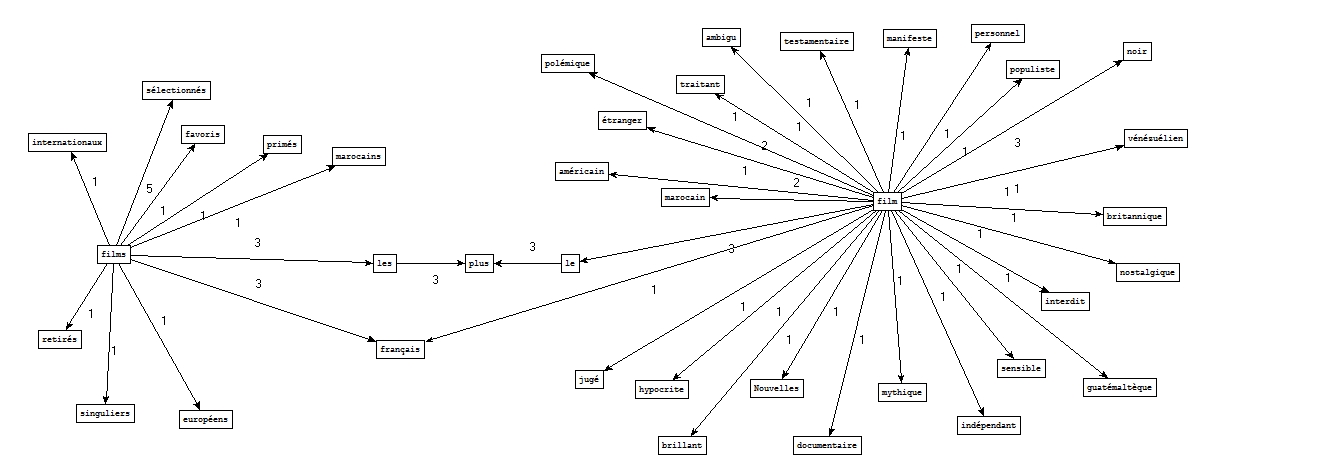
A partir des fichiers étiquetés par Tree-tagger :
NOM PREP DET NOM
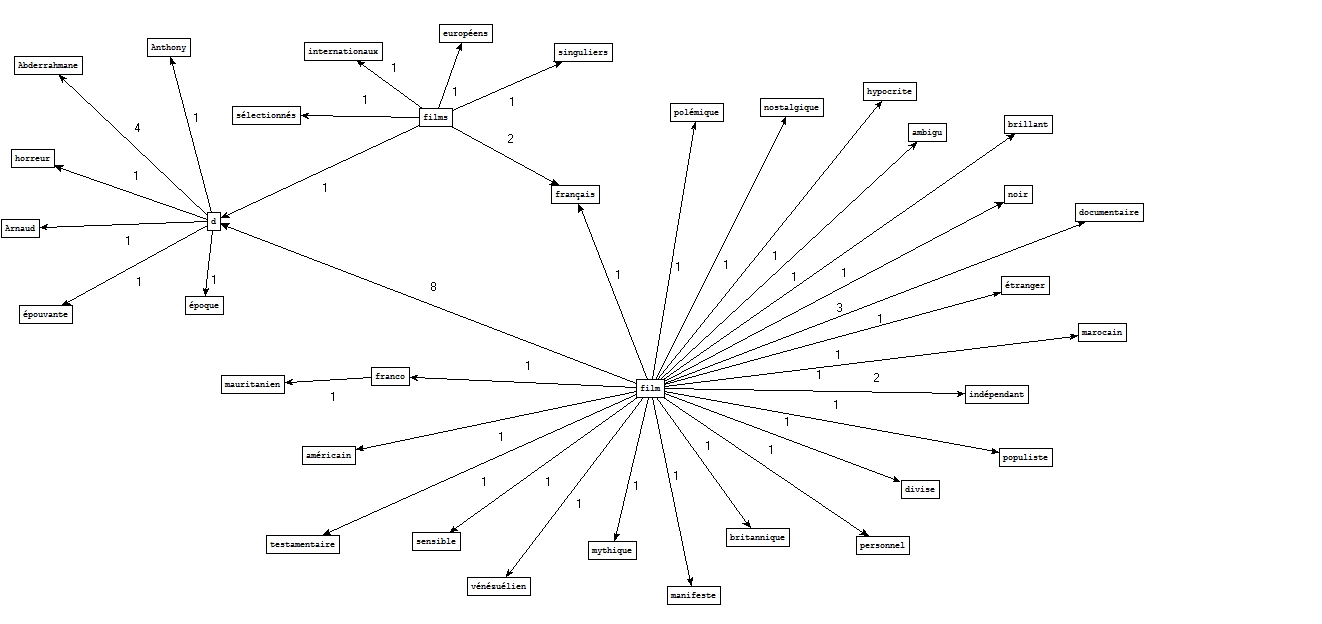
A partir des fichiers étiquetés par Cordial :
A partir des fichiers étiquetés par Tree-tagger :
VERBE PREP DET NOM
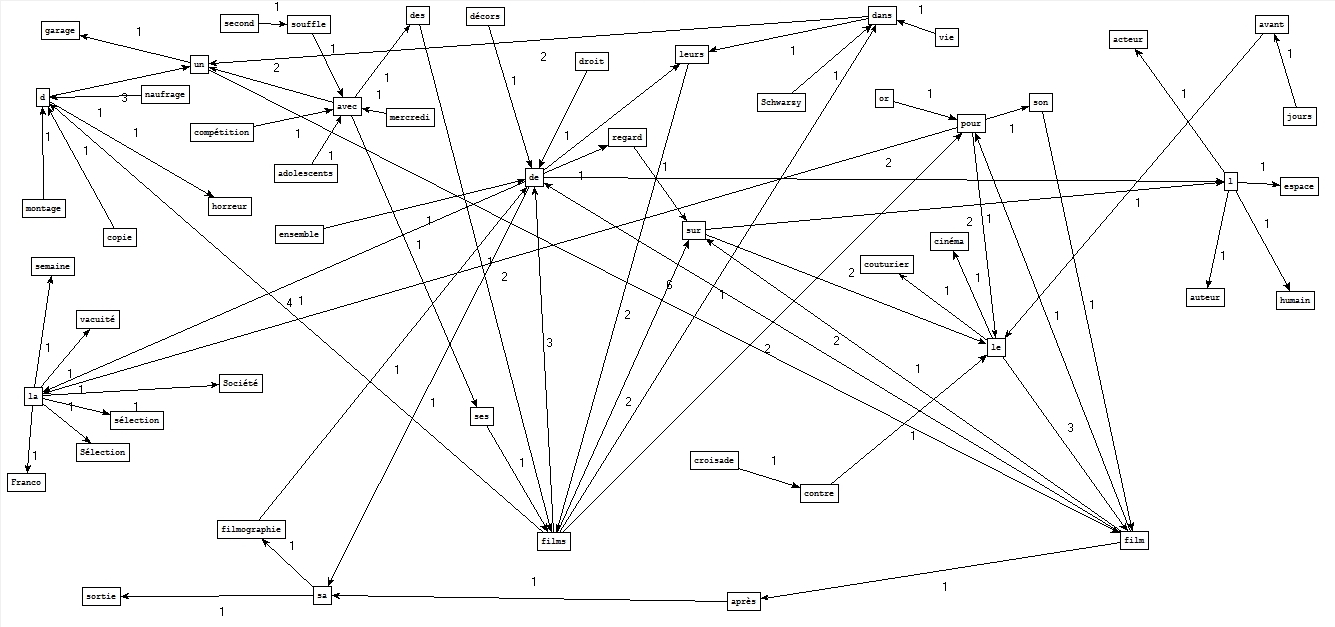
A partir des fichiers étiquetés par Cordial :
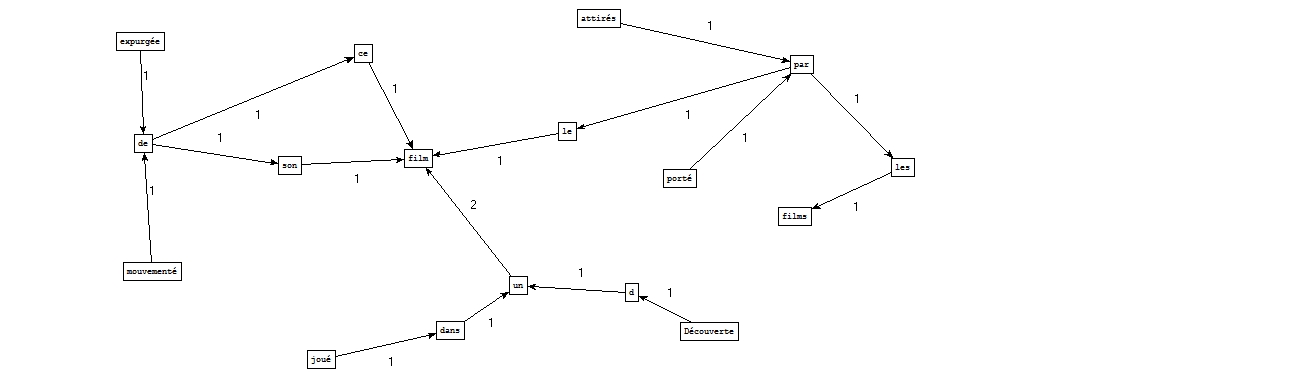
A partir des fichiers étiquetés par Tree-tagger :
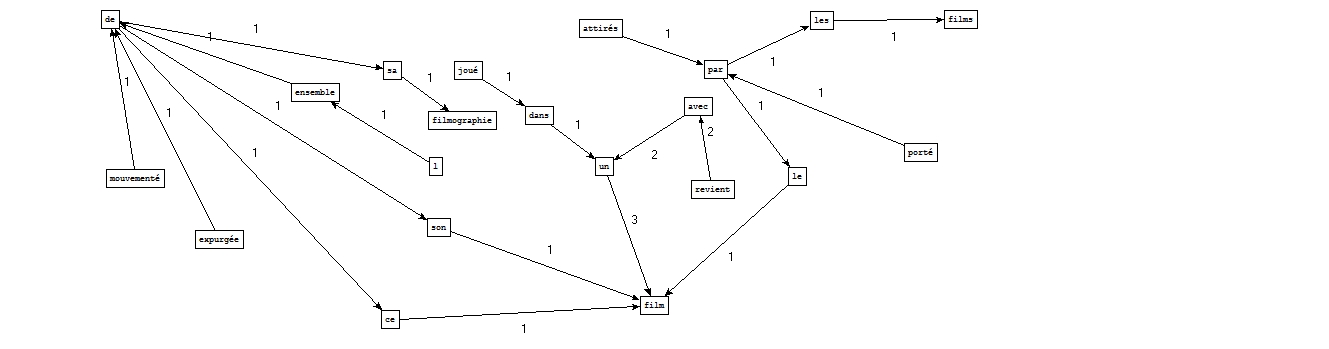
VERBE PREP NOM
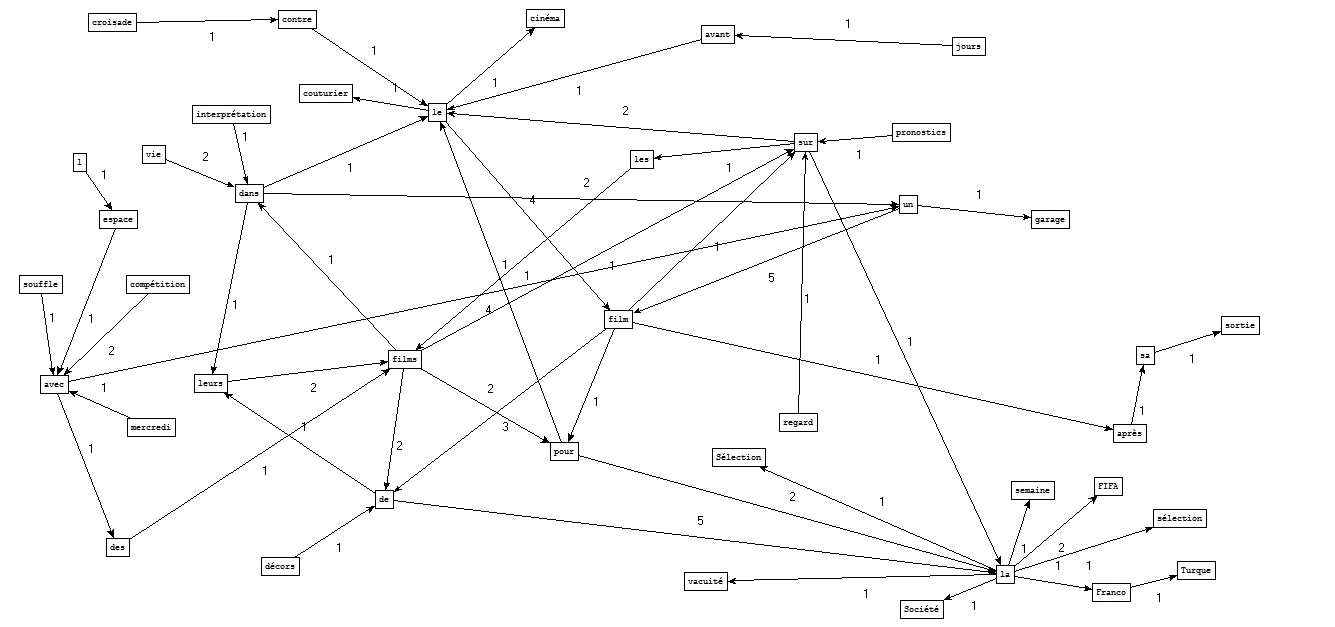
A partir des fichiers étiquetés par Cordial :
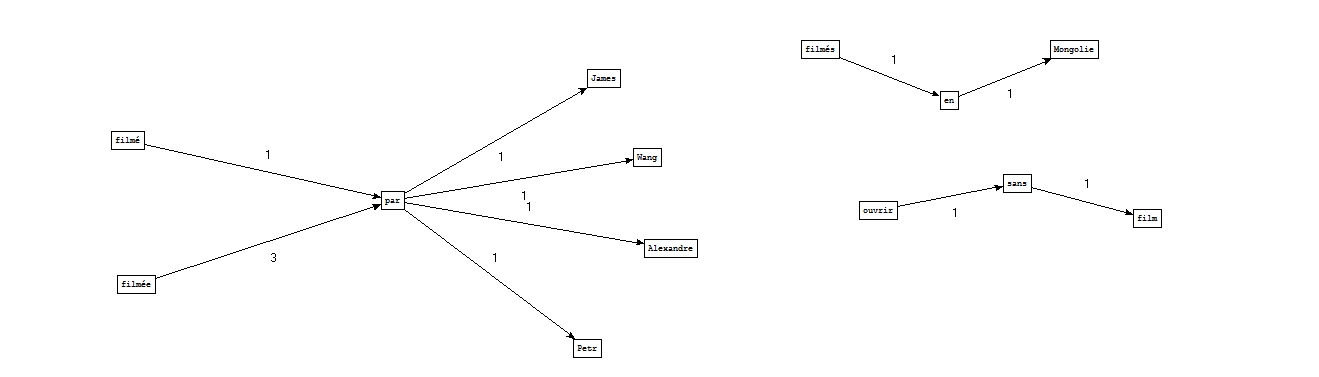
A partir des fichiers étiquetés par Tree-tagger :
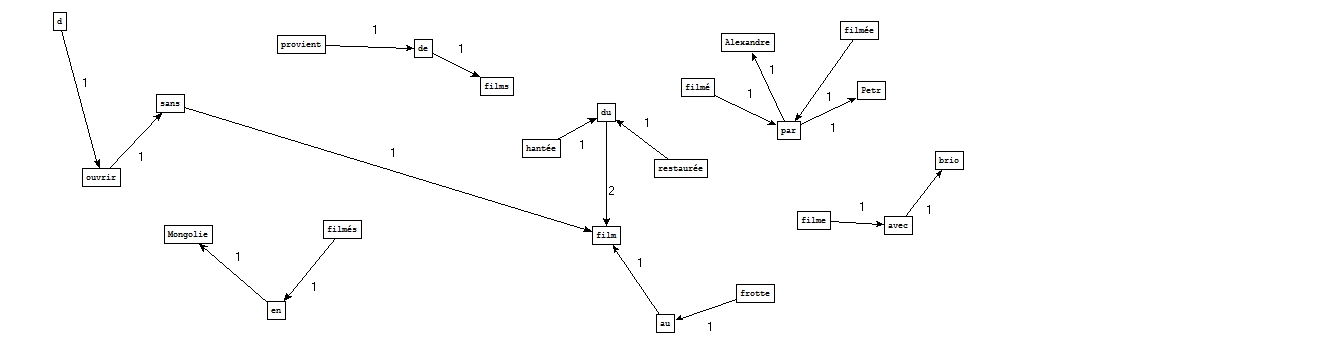
3208 : A la Une
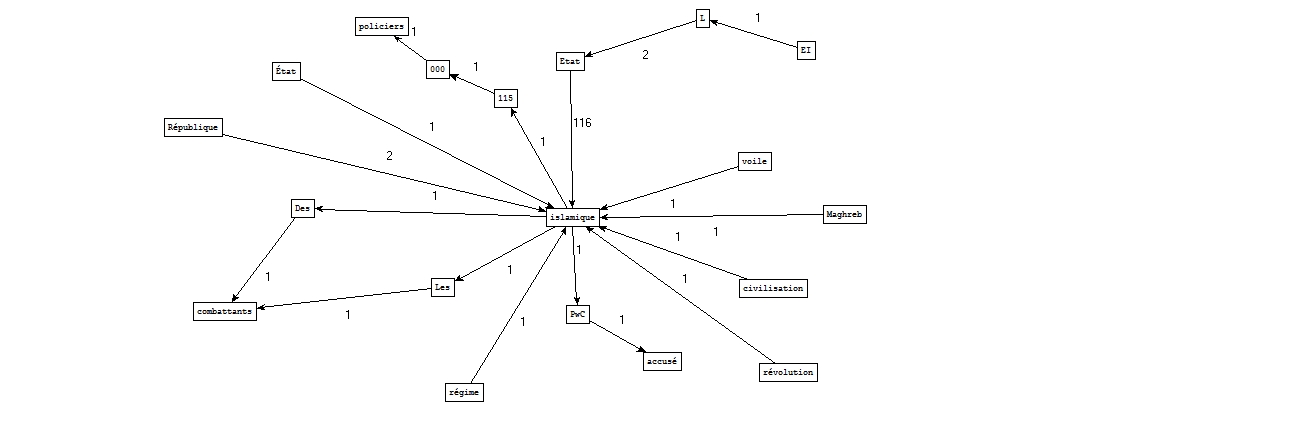
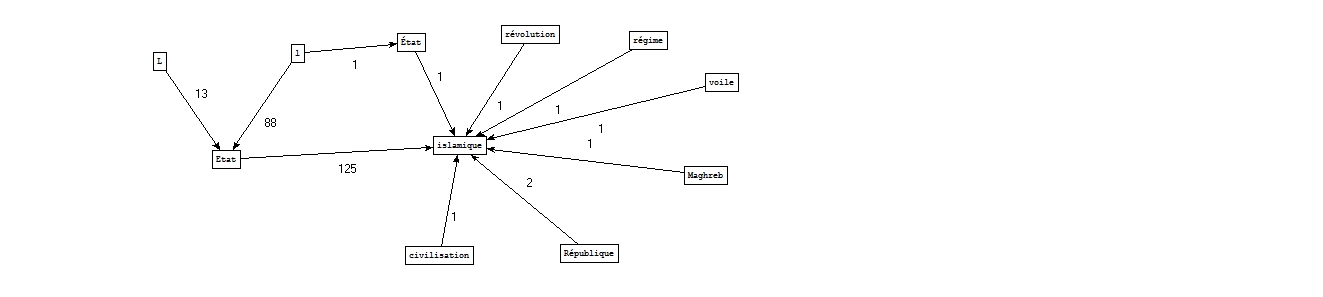
Nous avons choisi le motif "(i|I)slamiques?" pour cette catégorie.
NOM ADJECTIF
A partir des fichiers étiquetés par Cordial :
A partir des fichiers étiquetés par Tree-tagger :
Profondeur
Nous avons essayé de réalisé des graphes pour la profondeur sur la rubrique Cinéma, en choisisant le motif "films?", mais les résultats étaient illisibles :
Pour le patron NOM ADJ :

Pour le patron NOM PREP DET NOM :

Pour le patron VER PREP DET NOM :

Pour le patron VER PREP VER (qui est le seul lisible) :

Conclusions
La création de graphes permet la mise en avant de formes et d'expressions figées qui sont utilisés, voire parfois d'entité nommées.
Nous retrouvons par exemple noir comme cooccurrent le plus fréquent de film dans le cadre d'un schéma nom-adjectif, ce qui fait sens puisqu'il s'agit d'un genre à part entière.
Par ailleurs, dans la catégorie A la une, le patron ressortant le plus souvent avec notre mot-clé est Etat islamique.
Les résultats pour l'extraction en profondeur manquent malheureusement de lisibilité, car trop volumineux mais nous savons que s'ils sont aussi importants, c'est qu'ils donnent ces mêmes informations sur une plus grande échelle et gagneraient donc à être segmentés pour être visualisés plus facilement. Le contenu n'en est pas moins là et un travail de ce type pourrait constituer une intéressante base de données pour construire des probabilités et ainsi former des logiciels de rédaction automatique ou encore perfectionner les fonctions d'autocomplétion sur nos chers smartphones.