Projet
Ce site présente les étapes d’un projet de programmation réalisé dans le cadre du Master 1 en Traitement Automatique des Langues des universités Paris III/Paris X/INALCO.
Objectif
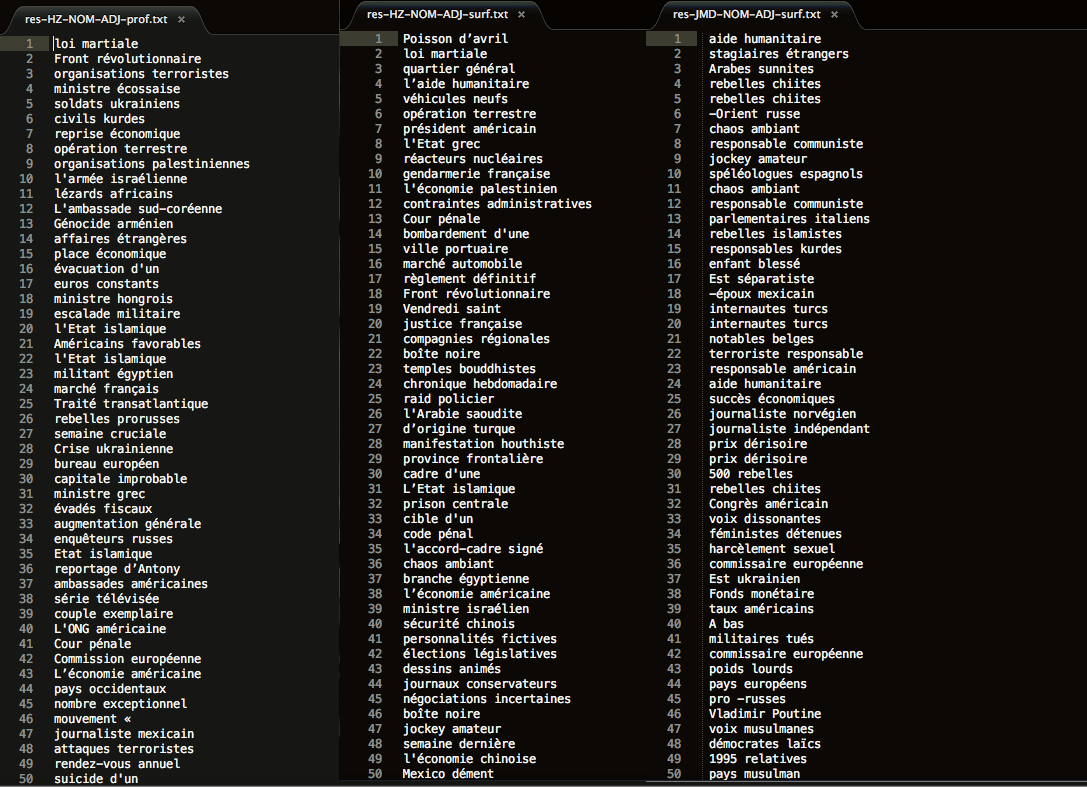
Analyser des patrons syntaxiques d'un corpus d'articles journalistiques, plus spécifiquement, de tous les articles de 2015 de la rubrique "International" du journal Le Monde.
Données de départ
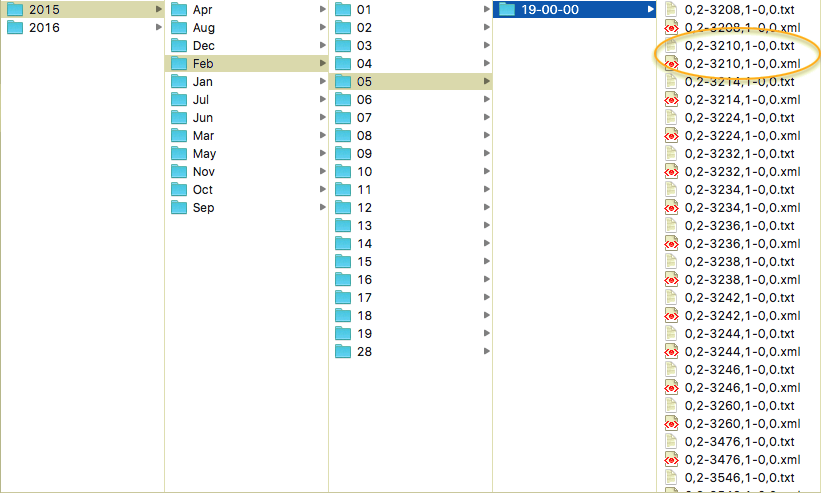
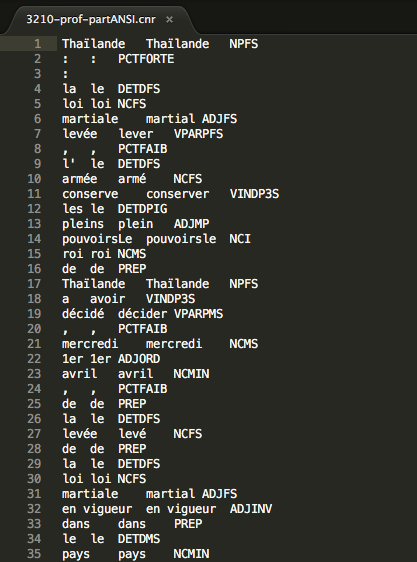
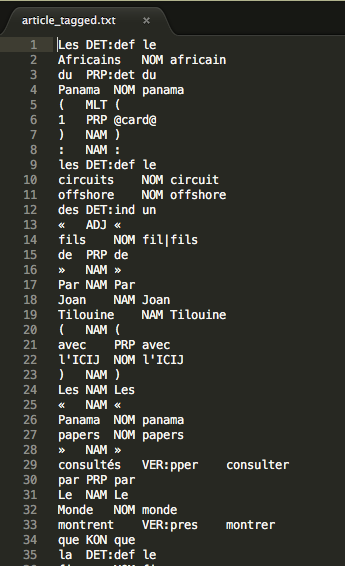
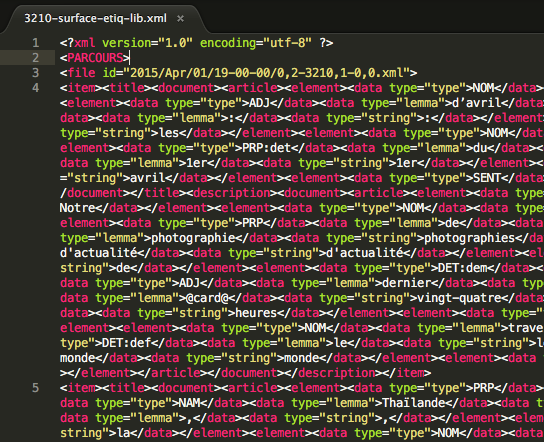
Les articles sont obtenus grâce à un fil RSS et sont présents en deux versions : une version résumée en format xml (la surface) et une version complète en format txt (la profondeur). Ces fichiers sont rangés dans une arborescence organisée par date.

Le Monde en Surface
Fil RSS
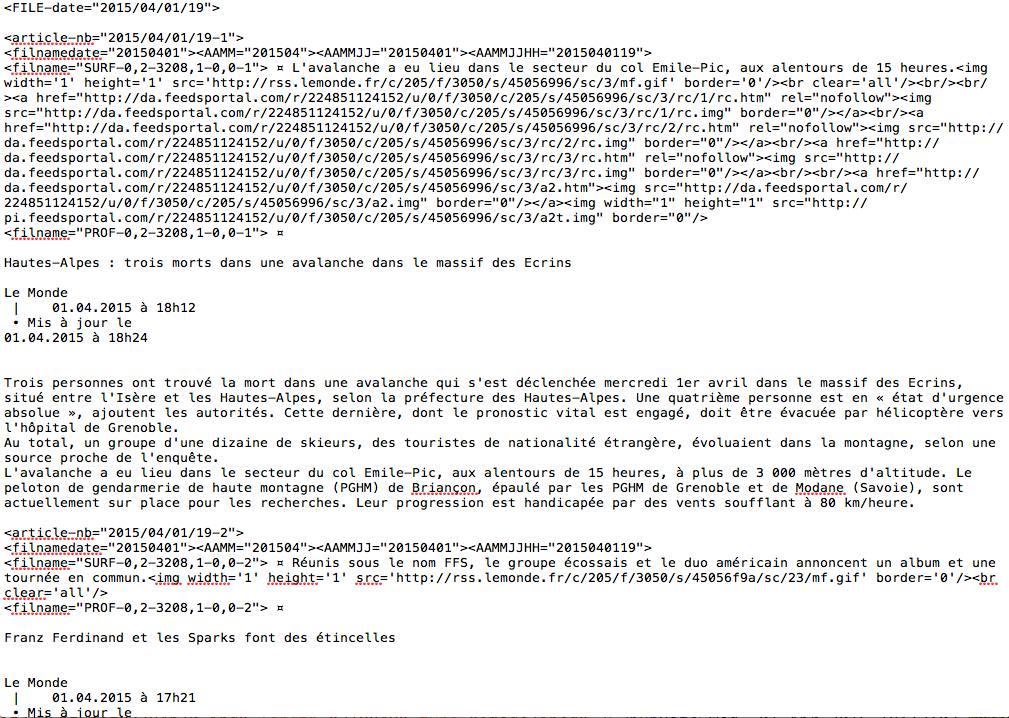
Le Monde en Profondeur
Article associé