But: Ce projet a été réalisé dans le cadre du cours Programmation et projet encadré de M1 Traitement automatique des langues. Son objectif est d’étudier la vie multilingue d’un terme choisi dans plusieurs langues. Nous avons choisi de nous pencher sur la vie multilingue du terme « Peine de mort » dans les quatre langues française, anglaise, chinoise et arabe...
Etablie par un juge ou une juridiction conformément à la loi applicable, la peine de mort consiste à sanctionner toute personne ayant commis une faute grave en l’exécutant.
L’origine de la peine de mort remonte à l’époque de la Loi du Talion (« Œil pour œil, dent pour dent »), dont les premiers signes sont trouvés dans le Code d’Hammourabi au XVIIe siècle avant Jésus-Christ. De nombreuses personnalités ont soutenu ce type de peine au cours de l’histoire, comme Platon, Aristote, Saint Thomas d’Aquin, Jean-Jacques Rousseau, Immanuel Kant et Georg Wilhelm Friedrich Hegel.
Bien que de nos jours, la plupart des pays ont aboli la peine de mort, cette dernière fait encore couler beaucoup d’encre et divise les opinions entre ceux qui la considèrent comme une méthode barbare et qui porte atteinte à la dignité humaine et aux droits de l’homme et ceux qui tiennent compte des facteurs philosophiques ou religieux. Les méthodes employées pour appliquer la peine de mort ont évolué au fil du temps et différemment d’un Etat à l’autre. De nos jours on compte parmi elles l’exécution à coup de fusil ou de pistolet, la fourche, la décapitation, l’injection létale, la chaise électrique ou encore la lapidation. Abolition ou maintien de la peine de mort, telle est la question !!
1. Script Bash : Guide avancé d'écriture des scripts Bash
2. Wget : Manuel Wget
3. Lynx : Manuel Lynx
4. Egrep : Egrep et Regex
5. Langage HTML : Apprendre le HTML
6. Minigrep : Intro Minigrep
7. Trameur : Intro Trameur
8. Nuage : Créer le nuage
9. Css : CSS Tutorial
Ici quelques petits mots sur nos expériences individuelles lors de la recherche des URLs qui vont constituer notre corpus dans les quatre langues.
De nos jours, alors que certains y voient le seul et unique recours et que d’autres cherchent par tous les moyens à l’abolir, la peine de mort demeure dans le monde entier un sujet qui divise. Ainsi, on a essayé, lors de la sélection des URLs, de rester objectives et de refléter la réalité telle qu’elle est aujourd’hui, en choisissant des textes de presse ou autres qui renvoient à l’ensemble des opinions aussi différentes les unes que les autres sur la question, notamment celles des associations, des gouvernements, des organisations internationales et du grand public.
Nous aimerions remercier nos professeurs d'université pour les cours très enrichissants que nous avons suivi le long du semestre 1 : M. Fleury, M. Daube et M.Belmouhoub. Nous remercions également l'ensemble de nos camarades de cours de Paris 3, Paris 10 et de l'Inalco qui se sont montrés motivés et solidaires autour de ce projet. .
Tableau22/09/15-09/12/15
Étapes
Étape 1. Lecture du chemin des urls et du tableau à créer ( à partir d’un fichier input).
Étape 2. Création de l’en-tête de la page.
Étape 3. Initialisation d’un compteur de fichiers.
Étape 4. Pour chaque fichier du chemin ./URLS, créer de sous-répertoires pour chaque fichier d’urls traité.
Étape 5. Création des colonnes du tableau.
Étape 6. Pour chaque ligne des fichiers d’urls, compter les lignes et le fichier dump, et puis aspirer des liens d’urls par la commande wget.
Étape 7. Détection d’erreurs dans les pages aspirées. Si le wget marche bien, récupérer l’encodage de la page web dans le fichier aspiré avec la commande egrep et l’expression régulière. Sinon, on fait rien.
Étape 8. Si l’encodage est utf-8 :
Dumper des liens d’urls avec la commande lynx et placer le résultat dans un fichier TEXT-DUMP ;
Détecter les mots-clés avec la commande egrep dans les fichiers dump et placer le résultat dans un dossier CONTEXTES ;
Créer le dictionnaire pour chaque fichier dump utf-8 dans un nouveau dossier INDEX et le nettoyer avec la commande sed ;
Compter le nombre d’occurrences des motifs et extraire des contextes en html avec le programme minigrep ;
Insérer des lignes et des colonnes du tableau, concaténer tous les fichiers dump, contextes et index dans les fichiers globaux et inclure les balises pour visualiser les dump / contextes / index pour chaque fichier.
Étape 9. Sinon, c’est-à-dire l’encodage n’est pas en utf-8 :
Vérifier l’encodage avec la commande iconv -l :
Si l’iconv connaît l’encodage, utiliser la commande file pour trouver l’encodage :
Si l’encodage est en utf-8, refaire l’étape 8 ;
Sinon, on change l’encodage en utf-8 par la commande iconv et refaire l’étape 8.
Si l’iconv ne connaît pas l’encodage, on ne fait rien.
Voici notre tableau:
Pour télécharger le script : ici
PHASE II09/12/15-06/01/16
Des nuages et des arbres de mots
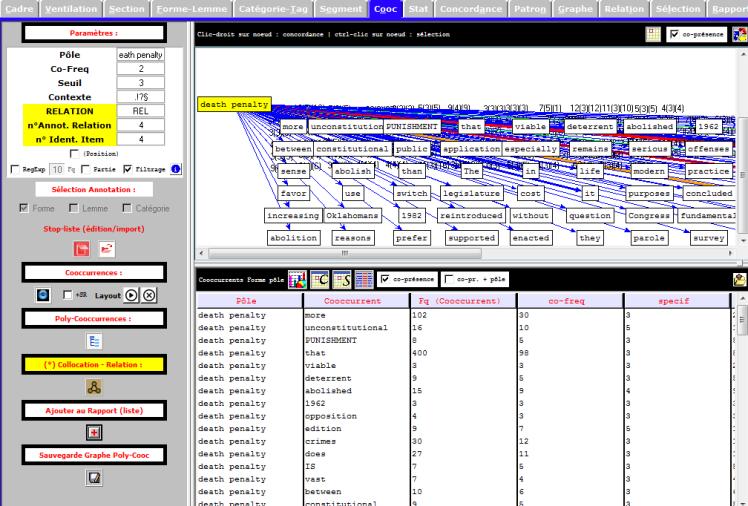
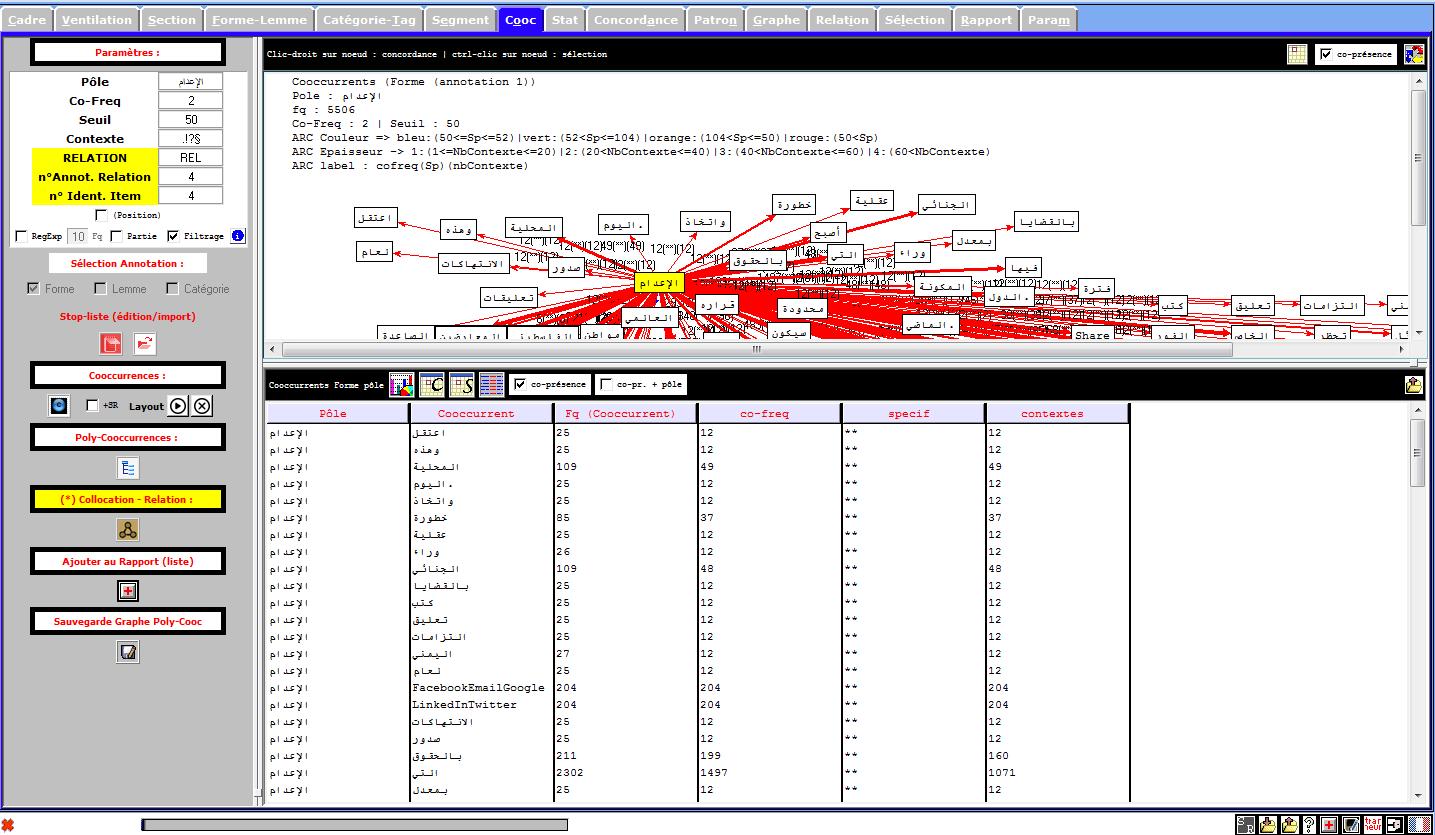
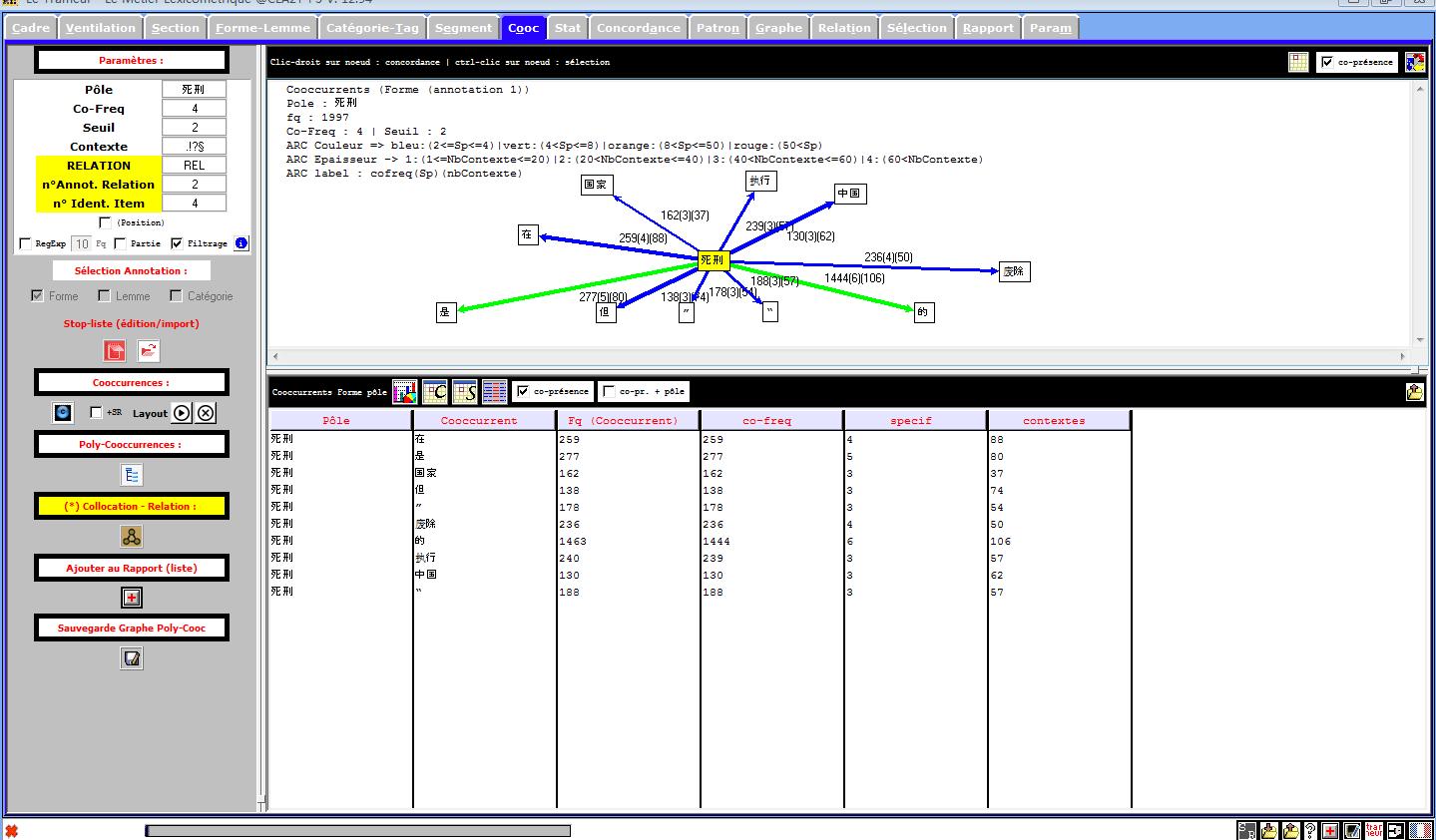
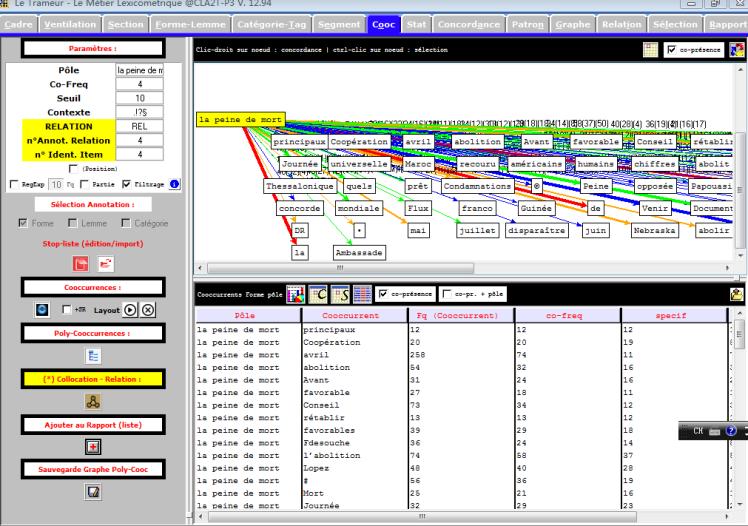
Le Trameur :
Programme de génération puis de gestion de la Trame et du Cadre d'un texte (le métier Textométrique) pour construire des opérations lexicométriques / textométriques. Le Trameur intègre le programme treetagger : système d'étiquetage automatique des catégories grammaticales des mots avec lemmatisation.
Avec le Trameur, on peut faire beaucoup de choses. Cela dit, la mission principale pour notre projet est de créer l'arbre des cooccurrences. Si cela vous intéresse, vous pouvez trouver le manuel dans le module "OUTILS UTILISÉS
La création des nuages
À présent, il y a pas mal de sites magiques visant à faire des jolis nuages, comme Wordle, tagCloud et ImageChef. Mais if faut faire attention car tous les sites ne traitent pas le chinois.
PROPBLÈMES RENCONTRÉS22/09/15-06/01/16
problèmes et solutions
1. Des lettres diacritées ne peuvent pas correctement être affichés.
Solution: C'est la différence entre l'encodage utilisé en écrivant le script et celui pour la lecture qui amène à cette situation. Donc, il faut changer la façon d'écrire pour s'adapter à la lecture. Par exemple N° est écrit comme "N&" plus "deg".
2. Si l'on change un fichier d'urls, on peut obtenir un tableau de plus.
Solution: C'est à cause d'un fichier caché. Si l'on change le fichier d'urls, le fichier origninel va sauvegarder automatiquement. Il faut utilisr la commande ls pour touver le fichier supplémntaire et le supprimer en utilisant la commande rm.
3. L'encodage ne peut pas être connu par l'iconv.
if faut chercher le charset dans les pages aspirées avec la commande egrep et les expressions régulières
4. La segmentation du chinois
C'est dommage que le Trameur ne traite pas le chinois. Mais heureusement, il y a beaucoup de segmenteurs sur Internet. Voici un site qui introduit les logiciels les plus dévelopés pour segmenter le chinois : oschina.net/projet/tag/264/segment
Bien sûr, dans le chemin de la réalisation du projet, on a rencontré d'autres problèmes mais assez faciles à réssoudre. Vous pouvez trouvez les détails dans notre blog dont l'adresse se trouve en bas de la page accueil.
Ania MALOUM
aniamaloum@gmail.com
Kira Carmignani
kiraavis@gmail.com
Yizhe WANG
wangyizhe0201@gmail.com
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}