Présentation
Tout
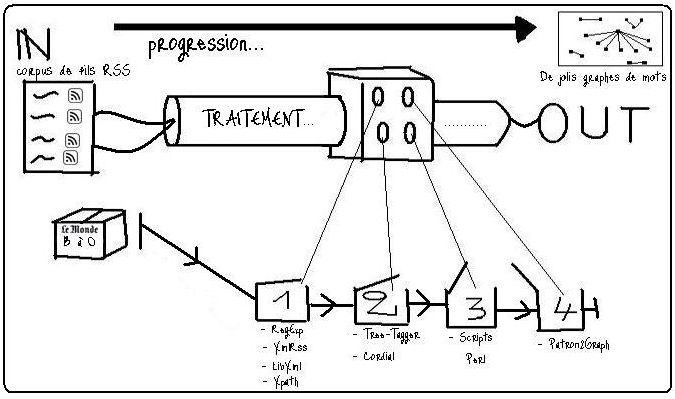
comme pour le projet du premier semestre, ce projet a pour objectif de
réaliser une chaîne de traitement textuel semi-automatique, allant de
la récupération des données à leur présentation en utilisant des
scripts Perl, différents outils d'étiquetage et un programme de
visualisation graphique.
Les données à traiter sont les fils RSS du site "
lemonde.fr" de l'année 2010.
Ces fils ont été récupérés tous les jours à 19H et chaque fil correspond à une rubrique de l'actualité (ex: "Sports", "A
la Une"...).
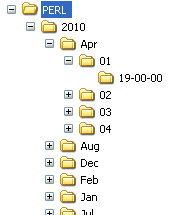
L'arborescence de travail
L'archive regroupant ces fils nous a été fournie sous la forme d'une
arborescence
de sommet "année", de fils "mois", de petits fils "jours" et d'arrière
petit fils "heure". Les noeuds "heure" contiennent donc l'ensemble des
fils de la journée, ces fils étant au format XML.
Une histoire de fils (RSS)
Un flux RSS permet à un utilisateur abonné, de recevoir les mises à jour d'un site en temps réel.
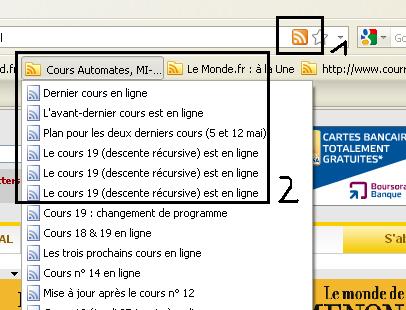
1 - L'icone pour s'abonner au fil RSS du site
2 - Des fils RSS
Concrètement ,un fil RSS (
Really Simple Syndication) est un fichier XML avec des petites particularités :
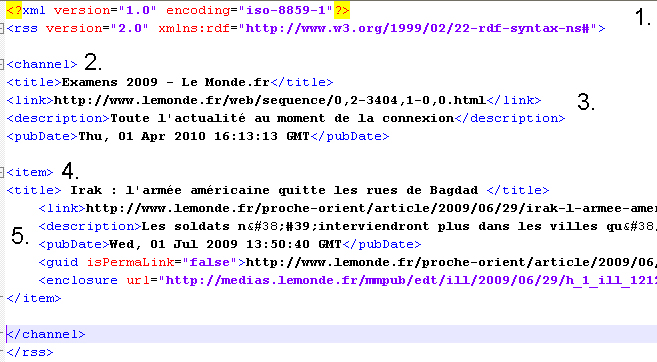 1. Déclaration du fichier XML, en dessous du fichier RSS et de sa version.
1. Déclaration du fichier XML, en dessous du fichier RSS et de sa version.
2
. Déclaration de la balise channel (du canal d'information) qui permet
de décrire le fil d'information de façon générale et permanente.
3.
La balise title contient le titre du fil, la balise link le lien du fil
sur le site du monde, la balise description un descriptif du fil et la
balise pubDate la date du fil.
4.
Les "item" sont les éléments documentaires essentiels qui vont composer
le fil et qui sont le support des informations qui circuleront sur le
fil. En général, il y a une dizaine d'items.
5.
La balise title contient le titre de l'item, la balise link un lien
vers l'article sur le site du monde, le descriptif est contenu dans la
balise description, la balise pubDate contient la date de l'article.
Le but du projet est de récuperer le titre et le descriptif de chaque fil RSS.
Le texte traité est donc celui contenu dans les balises "title" et "description" de chaque "item".
L'ensemble du projet est réalisé à partir de scripts écrits en
PERL.
Perl est un langage objet apparu en 1987.
Son
typage faible (voir inexistant) et son intuitivité en font un
langage puissant et simple à utiliser, particulièrement adapté au
traitement de données textuelles.
De plus, Perl est un langage
extrêmement bien documenté voiçi une modeste liste de sites qui ont été
particulièrement utile pour la confection de nos scripts :
-
Le site de Sylvain Lhuillier-
Le site de cours de Jean François Perrot -
L'excellente documention en anglais PerlDocToutes les "images" du site ont été réalisées avec ce bon vieux
Paint (et ça se voit !).
La structure du site est largement inspirée de la css disponible sur le site "
thenoodleincident".
Les polices suivantes ont été empruntées sur le site "
dafont" : "
Just Me Again Down Here" et "
Cube".
Pour colorer les scripts, nous avons utilisé le site "
Quick Highlighter" ainsi que "
ToHTML".