ETAPE 1
L'étape 1 consiste à établir un corpus d'URLs dans lequel apparaît les différents sens du mot « bouton» dans des contextes linguistiques différents.- Nous avons regroupé les URLS en fonction du sens du mot « bouton »: botanique, couture, médical et électrique/technologique.
Tout en diversifiant les moteurs de recherche à savoir 2lingual, Linguee.fr et Google.
ETAPE 2
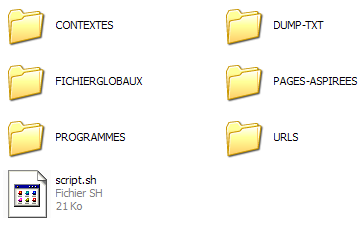
L'étape 2 consiste à créer l'arborescence du dossier du projet encadréLe dossier CONTEXTES regroupe les fichiers issus de l'extraction contextuelle par la commande egrep des mots traités dans les fichiers du dossier DUMP-TEXT.
Le dossier DUMP-TEXT regroupe les fichiers issus du traitement par la commande lynx sur les pages aspirées du dossier PAGES-ASPIREES.
Le dossier PAGES-ASPIREES regroupe les fichiers issus de l'aspiration par la commande curl des URLs contenues dans les fichiers situés dans le dossier URLs.
Le dossier PROGRAMMES regroupe l'ensemble des scripts du projet.
Le dossier FICHIERSGLOBAUX regroupe l'ensemble des résultats obtenus par l'extraction des fichiers contextes.
ETAPE 3
Désormais, il s'agit de construire progressivement la chaîne de traitement automatique des urls.
En premier lieu, il nous a fallu créer un tableau de liens qui puisse lire chaque fichier contenant des urls. La première colonne indique le numéro de l'url lue, puis la seconde colonne précise les noms des fichiers et enfin la troisième colonne affiche le nom des urls.
Il a fallu ensuite rajouter une colonne PAGES ASPIREES, grâce à la commande curl, puis deux colonnes contenant les DUMPS initiaux et les DUMPS utf-8 des pages aspirées obtenus gâce à la commande lynx. Le fichier dump devra être converti en UTF-8 si nécessaire.
Si le résultat n'est pas en UTF-8, il faudra utiliser la commande iconv ou le programme perl. De plus, afin de détecter l'encodage de la page, on peut soit utiliser la commande file ou bien rechercher le charset de la page HTML.
ETAPE 4
Afin de terminer le tableau, il nous a fallu rajouter deux dernières colonnes grâce à la commande egrep: une commande unix permettant le filtrage de lignes dans un fichier contenant un motif donné.
ETAPE 5
La dernière étape du projet, la plus agréable à élaborer, a été la construction des nuages de mots à partir des contextes receuillis.PROBLEMES RENCONTRES
Les problèmes rencontrés concernent tout d'abord la difficulté de rechercher les contextes des motifs russe et arabe pour tous les sens, dans l'execution du programme Perl.Afin de tenter de remédier à cette situation, notre professeur, monsieur S. Fleury, a proposé la mise en oeuvre d'un second script perl. Le motif doit être directement écrit dans le script et pour lancer ce programme dans la console de cygwin, il faut taper la syntaxe ci-dessous:
perl minigrep "UTF-8" FICHIER_EN_UTF8.txt
Ce programme fonctionne pour le russe, mais pose toujours problème pour l'arabe à propos du sens botanique.
En outre, le programme indique pour une url donnée, les informations relatives aux pages aspirés, dumpages et contextes, mais peut aussi connaître des soucis d'exécution et ne pas fournir les informations recherchées. Ces inconvénients sont peut être liés à la configuration de l'outil cygwin.
Les tableaux ci-dessous vous indiquent les URLs qui posent problème.
Botanique :
| Urls | Langue | Encodage |
|---|---|---|
| http://cloverleafherbs.blogspot.com/search?q=bud | anglais | (UTF-8) |
| http://es.wikipedia.org/wiki/Yema | espagnol | (UTF-8) |
| http://www.hiperbotanica.net/tema1/1-3yemas.htm | espagnol | (us-ascii) |
| http://enciclopedia.us.es/index.php/Yema | espagnol | (utf-8) |
Couture :
| Urls | Langue | Encodage |
|---|---|---|
| http://ar.wikipedia.org/wiki/%D8%B2%D8%B1 | arabe | (UTF-8) |
| http://www.jeansbutton.ae/ | arabe | (us-ascii) |
| http://www.pugoviza.ru/files/other_cut1.shtml?simpl_butt.htm | russe | Encodage non détecté |
| http://ru.wikipedia.org/wiki/%D0%9F%D1%83%D0%B3%D0%BE%D0%B2%D0%B8%D1%86%D0%B0 | russe | (UTF-8) |
Electrique :
| Urls | Langue | Encodage |
|---|---|---|
| http://www.twitterbuttons.org/ | anglais | Encodage non détecté |
| http://kuwait10.net/2010/08/20/power_button/ | arabe | Encodage non détecté |
| http://blogohelp.blogspot.com/2009/08/navbar-blogspot.html | russe | (UTF-8) |
| http://www.google.com/support/toolbar/bin/answer.py?answer=31241&hl=ru | russe | (UTF-8) |
Médical :
| Urls | Langue | Encodage |
|---|---|---|
| http://www.acnecaretips.com/ / | anglais | (iso-8859-1) |
| http://www.woman.ru/kids/teens/article/40847/ | russe | Encodage non détecté |
| http://www.google.com/support/toolbar/bin/answer.py?answer=31241&hl=ru | russe | (UTF-8) |
D'où la mise en oeuvre d'un second script pour le traitement de l'arabe et du russe.
Par ailleurs, si vous souhaitez connaître le détail de notre parcours, nous vous conseillons de lire
notre blog: Cliquez-ici