Des fils vers les graphes
Objectif
Le but de ce programme perl est de rassembler toutes les manipulations précédemment étudiées, dans le but d'optimiser les étapes et de n'avoir à lancer qu'un seul script. Cela crée une chaîne de traitement permettant à l'utilisateur lambda ne connaissant pas la programmation de savoir rapidement ce qui se dit d'un sujet particulier dans un gros corpus. Ce script pourrait éventuellement nous permettre de créer un web service.
Le programme prend donc en entrée le nom du répertoire contenant les fichiers à traiter et construit en sortie les fichiers suivants:
- un fichier contenant le corpus extrait des fils RSS au format texte
- un fichier contenant le corpus extrait des fils RSS au format XML
- un fichier contenant une liste de patrons extraite du corpus (selon le fichier de patrons donné par l'utilisateur)
- un graphe obtenu à l'aide de patron2graph.exe
Au cours de l'exécution du programme, l'utilisateur est invité à donner le nom du fichier contenant les patrons à extraire et celui contenant le motif à représenter dans le graphe.
Afin de pouvoir traiter de gros corpus, ce script intègre une fonction de découpage permettant de découper le corpus s'il est trop volumineux et d'effectuer l'extraction de patrons sur des parties plus petites du corpus. Les patrons extraits dans ces petites parties sont centralisés dans un seul fichier res_extract.txt qui permet ensuite la construction du graphe.
Traitement
Dans notre cas, nous nous intéressions au contexte de la crise financière durant l'année 2009, dans la rubrique International du journal Le Monde. Il fallait donc extraire des motifs en relation avec ce contexte et pouvoir ensuite les représenter dans un graphe, afin de mieux analyser ses répercussions. C'est ce que nous avons fait en faisant l'extraction d'un graphe de mots autour du motif : \bcris. Vous pouvez voir ce motif dans le fichier motif.txt.
Grâce à ce motif, on extrait tous les patrons qui commencent par "cris", comme cela nous avons à la fois les singuliers et les pluriels.
Nous générons ainsi un beau graphe qui nous permet d'analyser notre thématique : la crise financière dans un contexte journalistique au cours de l'année 2009.
Résultat
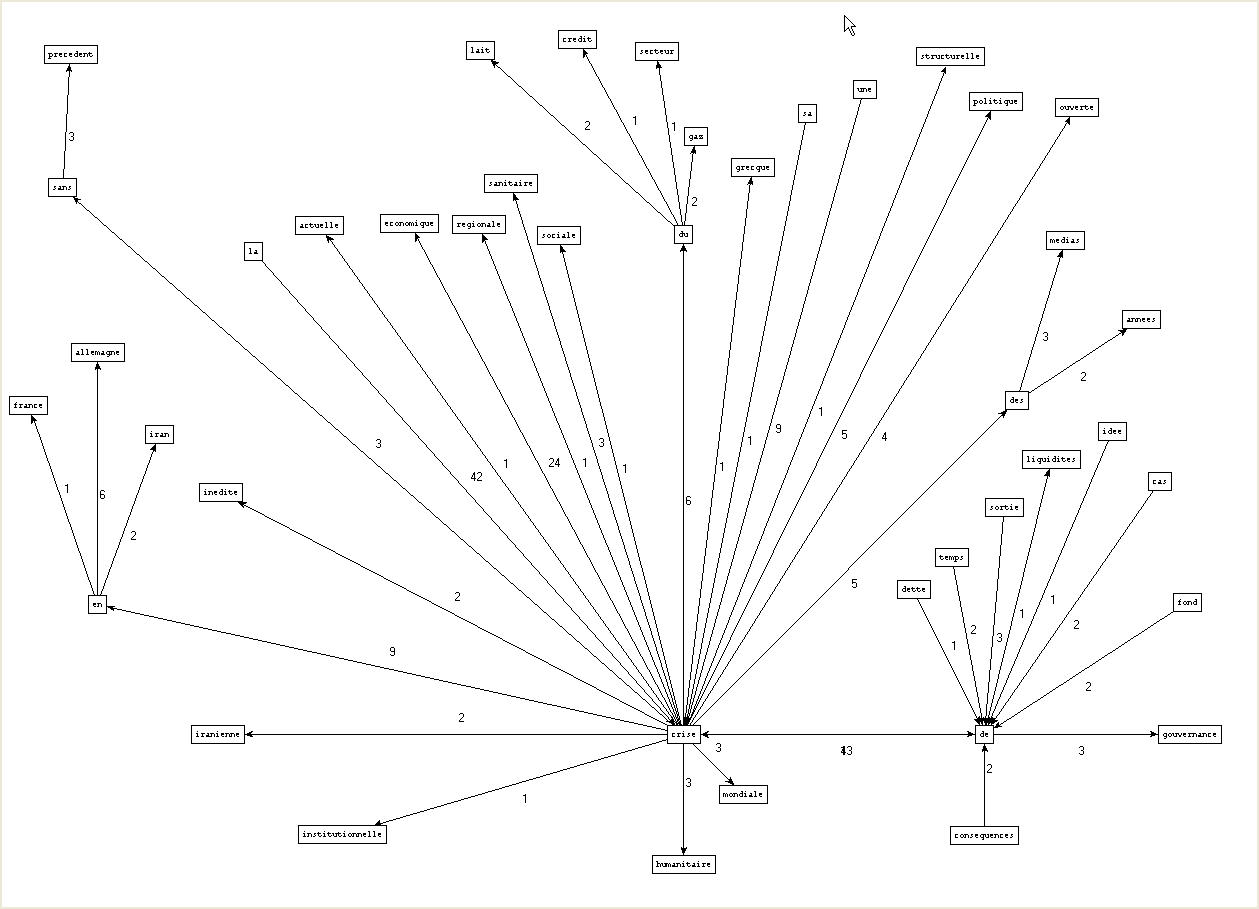
Analyse
Le corpus ici traité a également été analysé avec l'outil Lexico3, qui nous a permis de tirer des conclusions quant à la représentation de la crise financière durant l'année 2009 dans le journal Le Monde. Nous avons ensuite comparé les résultats de notre étude lexicométrique avec les graphes que nous avions obtenu grâce aux boîtes à outils et avons tiré de cette comparaison d'intéressantes conclusions.
Tout d'abord, voici les résultats de notre analyse lexicométrique : crise_financiere_2009.pdf
Cette étude a été réalisée dans le cadre du cours de Statistiques Textuelles de Monsieur André Salem.
Les similarités observées entre l'étude lexicométrique et le graphe réalisé grâce aux boîtes à outils sont nombreuses, ce qui nous permet de démontrer la pertinence d'une telle chaîne de traitement :
-tout comme dans l'analyse lexicométrique, le graphe nous montre que le terme "crise" ne fait pas seulement référence à la crise "financière". Il y a aussi : "crise iranienne", "crise humanitaire" , "crise sanitaire", etc.
-l'aspect inédit de cette année de crise est également mis en valeur dans le graphe : "crise sans précédent",etc.
-concernant les cooccurrents en liaison avec la crise financière, ils restent pertinents et nous permettent de rendre compte de l'impact de cette crise.Par exemple, le terme "crise économique" apparaît 24 fois.
La complémentarité des deux analyses est démontrée par le fait que l'analyse lexicométrique nous permet d'avoir une représentation temporelle de la crise financière au cours de l'année 2009, ce que ne nous permet pas les graphes de mots. A contrario, les graphes de mots nous permettent une analyse rapide et une représentation visuelle immédiate d'un terme dans un corpus, ce que ne nous permet pas l'analyse lexicométrique.
Conclusion
Le traitement en chaîne utilisé ici rassemble toutes les fonctionnalités étudiées dans les boîtes à outil diverses. Cela nous permettrait d'aller vers la réalisation d'un web service permettant de générer des graphes à partir de fils RSS. Nous pourrions évidemment ajouter au web service des options, afin de rendre plus pertinent :
-la possibilité de visualiser un motif précis au format html, grâce à la sortie Xslt
-la possibilité de créer un rapport lexicométrique avec Lexico3, qui viendrait compléter l'analyse
effectuée à l'aide du graphe : ce rapport serait bien sûr effectué par des linguistes et remis au client du web service
-la possibilité de créer des graphes colorisés ou même des représentations de l'information en trois dimensions
-la possibilité de créer des nuages de mot, étape que l'on intégrerait au processus grâce au travail effectué au 1er semestre sur les nuages de mots
Ce web service permettrait aux linguistes, aux agences de presse, de communication, aux publicitaires etc. de pouvoir analyser de façon rapide et pertinente l'information issue d'un grand corpus. Ce serait un gain de temps et d'argent précieux pour ces entreprises.
Remerciements
Nous tenons à remercier particulièrement nos trois professeurs : S. Fleury, R. Belmouhoub et J.M. Daube pour leurs enseignements et leur soutien tout au long de l'année.
Nous remercions également nos collègues avec qui nous avons pu travailler de façon enrichissante et efficace.
Nous remercions aussi les étudiants des années précédentes pour les informations que nous avons pu obtenir grâce à leur travail passé.
Enfin, nous remercions Claire Guiraud pour son explication détaillée sur ce que sont les web services.