Description du code
Le projet consiste à créer une interfaçe graphique, où l'on peut saisir n'importe quelle adresse URL. Une fois le script lancé via fenetre.py (F2), le site apparait dans une fenêtre indépendante "MainWindow".
Nous étudierons la rubrique ITunes du site Apple soit www.www.apple.com/fr/itunes/what-is/.
#-*-coding:utf-8* : Encodage en UTF-8.
En premier lieu, il faut indiquer à Python d’importer les librairies PyQt. Ceci est fait avec les lignes suivantes :

Ce premier module permet de charger la page web sans en avoir saisir le protocole.
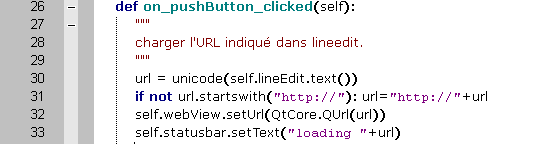
Ce module permet d'activer la touche "Entrée" du clavier pour charger la page.

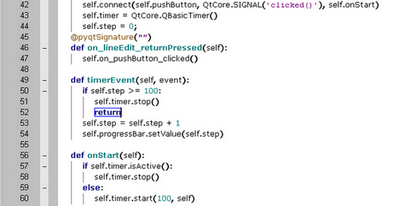
Le code suivant déclencle le chargement de la page lors du double-clique sur le bouton "ALLEZ" et notamment la progression du chargement par le widget "ProgressBar"(def timerEvent/def onStart).
-Bouton "Texte brut"
Le code suivant permet d'extraire le texte brut de la page dans la mini-fenêtre crée dit "TextEdit".
"toPlainText"() : extrait le code source sans les balises HTML.
"re.sub("\s+", " ", self.text)" : permet de substituer toutes les fins de ligne par un espace.
"self.textEdit.setText(self.text)" : affiche les résultats dans le "TextEdit".

-Bouton "nombre d'occurences"
La fonctionnalité "nombre d'occurences" affiche le nombre d'occurences total de la page.

L'utilisation des expressions régulières avec Python se fait en plusieurs étapes :
-Il faut d'abord compiler l'expression régulière au moyen de la fonction re.compile : exp=re.compile("\W+", re.U))
"\W+" est une expression régulière qui permet de rechercher les caractères non alphanumérique tels que: un espace, « , ;!:?... () » pour les supprimer afin de ne récupérer que les mots.
Le signe "+" indique que l'on cherche un ou plusieurs caractères et "U" correspond à Unicode.
-La compilation fournit un objet auquel on peut appliquer diverses méthodes dont la fonction split : listemot=exp.split(html)
-Bouton "nombre d'occurences uniques"

Le code source est identique au module précédent. A partir du nombre d'occurences total, nous pouvons extraire le nombre d'occurences qui n'apparait qu'une seule fois.
html = re.sub('[^0-9]',' ', html) : permet d'extraire le nombre d'occurences uniques de la page en éliminant les doublons.
-Bouton "recherche de cooccurences"
Cette fonction va permettre d'extraire les mots qui suivent un choix de mot de la page.

mot1=unicode(self.lineEdit_2.text()) : saisie du mot du choix de mot dans LineEdit
text = re.sub("\s+", " ", unicode(self.webView.page().mainFrame().toPlainText())) :
extraction dans le texte brut.
m=re.findall(mot1+' \w+', str(text)) :
cette fonction va chercher le mot suivant du mot choisi.
for cooccu in m:
resultat=resultat+cooccu+"\n"
self.textEdit_2.setText(str(resultat)):
affiche le résultat dans le "TextEdit" en sautant une ligne par réponse.
Par exemple, en saisissant "iTunes", nous pouvons constater que le nom de la marque est généralement suivi du mot "Store" au sein de la page. Cette fonction permet d'analyser le contenu textuel de la page web et éventuellement d'étiqueter les occurences.
