...:::Projet LA VIE DES MOTS SUR LE WEB par Agnieszka, Marie et Sophie:::...
 Le script optimisé pour le site. Pour le télécharger en version qui marche, cliquez le lien au dessous du script
Le script optimisé pour le site. Pour le télécharger en version qui marche, cliquez le lien au dessous du script
SCRIPTS FINAUX
Notre travail est basé sur quelques scripts, mais certains n'étaient utiles que pendant le travail.
1. préliminaires:
Les scripts marchent ŕ partir de quelques données en entrée et sont dépendants de la configuration de fichiers et données.
Voici l'arborescence obligatoire pour le script :
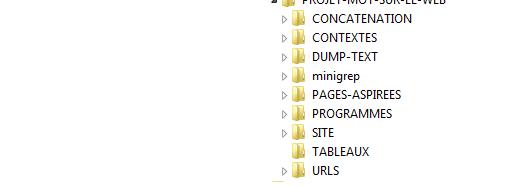
Le chemin absolu des fichiers du script se trouve dans le fichier rm_don.txt, qui est lui męme répertorié dans le dossier PROGRAMMES, tous les scripts prennent la variable dossier dans ce fichier.
****************************************************************************
2. les scripts
le nettoyeur | le script principal | le script général | le script pour concaténer | mode d'emploi
****************************************************************************
2.1 le nettoyeur
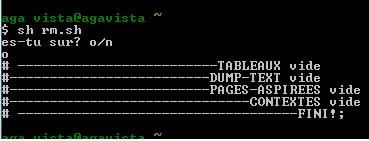
C'est le premier script, utilisé pour nettoyer les dossiers des fichiers créés pendant les lancements précedents : il se situe dans le répertoire racine de l'utilisateur de cygwin (pour plus de facilité : dčs qu'on fait fonctionner cygwin, on le lance sans devoir changer le répertoire courant).
| #!/bin/bash | |
| #les deux fichiers rm.sh et rm_don.txt doivent ętre mis dans le répertoire de travail de cygwin : c/cygwin/home/'utilisateur' oů utilisateur=ce qui est affiché dans cygwin (pour le connaître, faire pwd juste au début de travail) | |
| echo "es-tu sur? o/n" | # précaution, il demande confirmation ŕ l'utilisateur |
| O="o"; | # variable qui sera utilisée pour connaître le répertoire de l'utilisateur |
| read choix; | # lire la décision de l'utilisateur |
| if [ $choix = $O ]; then | # si l'utilisateur tape "o" pour confirmer l'envie de supprimer les fichiers, on vide progressivement tous les dossiers qui ont été auparavant remplis par le script |
| { | |
| read rep < rm_don.txt; | |
| #!/bin/bash | #le répertoire de travail se trouve dans le fichier |
| # aprčs, les opérations sont récursives : on ouvre le dossier, on supprime tout dedans et on affiche le message (pour que l'utilisateur sache qu'il se passe quelque chose) | |
| cd $rep/TABLEAUX/; | |
| rm -f -r * | # commande supprimant les fichiers. Option -f pour forcer la suppression męme si le répertoire est vide, option -r pour supprimer aussi les répertoires. |
| echo "# -------------------------TABLEAUX vide" | |
| cd $rep/DUMP-TEXT/; | |
| cd ./FR/ | |
| rm -f -r *; | |
| cd ../EN/; | |
| rm -f -r *; | |
| cd ../PL/; | |
| rm -f -r *; | |
| echo "#-------------------------DUMP-TEXT vide" | |
| cd $rep/PAGES-ASPIREES/; | |
| cd ./FR/; | |
| rm -f -r *; | |
| cd ../EN/ | |
| rm -f -r *; | |
| cd ../PL/ | |
| rm -f -r *; | |
| echo "#-------------------------PAGES-ASPIREES vide" | |
| cd $rep/CONTEXTES/; | |
| cd ./PL | |
| rm -f -r *; | |
| cd ../FR | |
| rm -f -r *; | |
| cd ../EN | |
| rm -f -r *; | |
| echo "#------------------------------CONTEXTES vide" | |
| echo "# -----------------------------------FINI!;" | |
| } | |
| else echo "bye"; | # ce qui se passe si l'utilisateur tape quelque chose d'autre que le "o" : programme fini. |
| fi; | |
| exit; |
et le modčle du fichier d'entrée
****************************************************************************
2.2 fait-tableau
C'est le script principal. Il a pour tâche d'aspirer les pages web sur le disque local, d'en extraire le texte et de montrer le contexte du mot choisi. En entrée, il a besoin de savoir oů travailler, (il le prend du fichier avec les données, explication en point 2.3), de la liste des URLS (variables fic, fic1, fic2 pour les 3 langues étudiées), du nom du fichier html avec des tableaux ŕ créer (variable tablo) et de la liste des sens puisque qu'on a travaillé sur un mot français possédant des variantes sémantiques et lexicales en anglais et polonais (variable sens) --------------------------------------------------------| #!/bin/bash | |
| #!/bin/bash | |
| read chemin; | |
| read fic; | # fichier contenant les liens français : "; |
| read fic1; | # fichier contenant les liens anglais: "; |
| read fic2; | # fichier contenant les liens polonais : "; |
| read tablo; | # fichier html ou stocker les liens : "; |
| read sens; |
--------------------------------------------------------
#création des dossiers selon les sens répertoriés:
--------------------------------------------------------
mkdir $chemin/PAGES-ASPIREES/FR/$sens/;
mkdir $chemin/DUMP-TEXT/FR/$sens/;
mkdir $chemin/CONTEXTES/FR/$sens/;
mkdir $chemin/PAGES-ASPIREES/EN/$sens/;
mkdir $chemin/DUMP-TEXT/EN/$sens/;
mkdir $chemin/CONTEXTES/EN/$sens/;
mkdir $chemin/PAGES-ASPIREES/PL/$sens/;
mkdir $chemin/DUMP-TEXT/PL/$sens/;
mkdir $chemin/CONTEXTES/PL/$sens/;
--------------------------------------------------------
#on crée le site web qui contiendra les tableaux. On va écrire progressivement les lignes dans le fichier html (variable tablo)
--------------------------------------------------------
<.table><.tr><.td><.p>echo "<.html><.head><.meta http-equiv=\"Content-Type\" content=\"text/.html; charset=ISO 8859-2\"/><.title>tableau sens<./.title><./.head><.body>" > $tablo;<./.td><.td><./.td><./.tr><./.table>
--------------------------------------------------------
# création de la premičre partie du tableau, pour le français:
1. on écrit les lignes permettant de créer le tableau, avec tous les paramčtres de largeur, couleur etc.
--------------------------------------------------------
echo "<.table border=\"4\" align=center><.h2> FRANCAIS <./.h2><./.td><./.tr>" >> $tablo;
--------------------------------------------------------
2. on initialise notre compteur et on crée une boucle : pour chaque ligne dans le fichier contenant des URLS (et donc pour chaque adresse web d'une langue donnée) on fait un certain nombre d'opérations :
--------------------------------------------------------
i=1
for nom in `cat $fic`;
{
--------------------------------------------------------
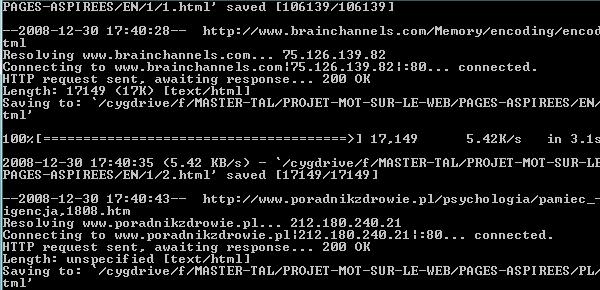
wget: on aspire les pages web et on les stocke dans les PAGES-ASPIREES. Option -O pour stocker le site dans un fichier.
lynx: regarde le site aspiré et en extrait le texte seul en l'écrivant dans un fichier texte. Option -dump pour stocker dans un fichier; -nolist pour ne pas écrire les liens contenus dans le site.
--------------------------------------------------------
wget -O $chemin/PAGES-ASPIREES/FR/$sens/$i.html $nom
lynx -dump -nolist $nom > $chemin/DUMP-TEXT/FR/$sens/$i.txt
--------------------------------------------------------
lire le motif (il dépend du sens, le script va chercher le motif en boucle: si la boucle tourne pour la 4čme fois, il cherchera le sens 4 dans un fichier.
egrep: extraire les lignes contenant le motif et les stocker dans un fichier texte. Option -i pour ne pas tenir compte de la casse dans le motif
--------------------------------------------------------
read motif < $chemin/PROGRAMMES/MOTIF/fr$sens.txt;
egrep -i "\b$motif\b" $chemin/DUMP-TEXT/FR/$sens/$i.txt > $chemin/CONTEXTES/FR/$sens/$i.txt
--------------------------------------------------------
ŕ la fin de la boucle, on remplit une ligne du tableau, en mettant les liens vers les fichiers créés et on augmente le compteur.
--------------------------------------------------------
echo "<.tr><.td><.a href = \"$nom\">url $i<./.a><./.td><.td><.a href=\"../PAGES-ASPIREES/FR/$sens/$i.html\">page aspirée $i<./.a><./.td><.td> let "i+=1" ;
}
--------------------------------------------------------
la boucle est finie
la deuxičme boucle fait exactement la męme chose mais pour les URLS des sites en anglais
-------------------------------------------------------- echo "<.tr><.td colspan =\"4\" align=center><.h2> ANGLAIS <./.h2><./.td><./.tr>" >> $tablo;
a=1
for nom in `cat $fic1`
{
read motif < $chemin/PROGRAMMES/MOTIF/en$sens.txt;
wget -O $chemin/PAGES-ASPIREES/EN/$sens/$a.html $nom
lynx -dump -nolist $nom > $chemin/DUMP-TEXT/EN/$sens/$a.txt
egrep -i "\b$motif\b" $chemin/DUMP-TEXT/EN/$sens/$a.txt > $chemin/CONTEXTES/EN/$sens/$a.txt
echo "<.tr><.td><.a href = \"$nom\">url $a<./.a><./.td><.td><.a href=\"../PAGES-ASPIREES/EN/$sens/$a.html\">page aspirée $a<./.a><./.td><.td> let "a+=1" ;
}
--------------------------------------------------------
la 3eme boucle est un peu différente compte tenu de l'encodage du polonais qui pose des problčmes. Jusqu'au commentaire suivant tout se passe de la męme maničre
-------------------------------------------------------- echo "<.tr><.td colspan=\"4\" align=center><.h2> POLONAIS <./.h2><./.td><./.tr>" >> $tablo;
b=1
for nom in `cat $fic2`;
{
read motif < $chemin/PROGRAMMES/MOTIF/pl$sens.txt;
wget -O $chemin/PAGES-ASPIREES/PL/$sens/$b.html $nom;
--------------------------------------------------------
Lynx prend par défaut l'encodage du systčme, il faut le forcer ŕ encoder les fichiers en sortie en UTF-8, d'oů l'option -display_charset=UTF-8
-------------------------------------------------------- lynx -dump -nolist -display_charset=UTF-8 $nom > $chemin/DUMP-TEXT/PL/$sens/$b.txt;
--------------------------------------------------------
Pour obtenir les motifs en UTF-8 et pour avoir un rendu correct du site en sortie, on utilise le script écrit en perl par Pierre Marshal et M. Fleury. On a fait quelques modifications sur ce script, pour les voir, rendez vous sur le blog ).
Les commentaires sur le fonctionnement de ce script et le script sont visibles ici: site plurital.
Pour installer le minigrep --> page de Pierre
-------------------------------------------------------- perl $chemin/minigrep/minigrepmultilingue2.pl "UTF-8" $chemin/DUMP-TEXT/PL/$sens/$b.txt $chemin/PROGRAMMES/MOTIF/pl$sens.txt $chemin/CONTEXTES/PL/$sens/$b.html;
--------------------------------------------------------
la sortie de perl étant en .html et non en .txt, c'est le seul changement.
-------------------------------------------------------- echo "<.tr><.td> let "b+=1";
}
echo "<./.table><.br>" >> $tablo;
#fin du tableau
--------------------------------------------------------
et on finit la page html.
-------------------------------------------------------- echo "<./.body><./.html>" >> $tablo;
****************************************************************************
Le script principal traite plusieurs URLs en 3 langues, en créant une page html avec 3 tableaux.
Comme on a répertorié 7 sens du mot mémoire sur lequel on travaille, on a besoin de lancer le script 7 fois pour obtenir 7 pages html.
Le script va prendre alors les données de différents sources, en fonction du sens.
pour cela, un petit script tout simple : sh fait-tableau-v6_charset_minigrep.sh < donnees1.txt
sh fait-tableau-v6_charset_minigrep.sh < donnees2.txt
sh fait-tableau-v6_charset_minigrep.sh < donnees3.txt
sh fait-tableau-v6_charset_minigrep.sh < donnees4.txt
sh fait-tableau-v6_charset_minigrep.sh < donnees5.txt
sh fait-tableau-v6_charset_minigrep.sh < donnees6.txt
sh fait-tableau-v6_charset_minigrep.sh < donnees7.txt
il fait fonctionner le script principal en l'alimentant des données dont il a besoin en entrée :
variables : chemin, fic, fic1, fic2, tablo et sens doivent ętre écrits dans les fichiers de données. ****************************************************************************
On nous a demandé de faire des nuages de mots. On a décidé de le faire avec l'outil donnant les résultats les plus agréables ŕ voir, WORDLE.
En entrée, le programme demande du texte pour en faire des statistiques et dessiner les nuages.
On a automatisé le travail au maximum en concaténant le contenu des fichiers contextes dans un męme fichier.
-------------------------------------------------------- #!/bin/bash
# fic=fichier contextes .txt
read chemin < rm_don.txt; #rep de travail
--------------------------------------------------------
on écrit un fichier contenant les numéros des sens (chez nous, il ressemble ŕ:
1
2
3
4
5
6
7
pour chaque sens, une boucle fonctionne:
-------------------------------------------------------- for sens in `cat donneesCAT.txt`;
{ i=1
for fichier in `ls $chemin/CONTEXTES/FR/$sens`
--------------------------------------------------------
il lit tous les fichiers français du sens donné et en écrit ŕ la suite les contextes dans un fichier txt. La ligne d'echo permet de voir combien de fichiers ont été concaténés.
-------------------------------------------------------- {
cat $chemin/CONTEXTES/FR/$sens/$i.txt >> $chemin/CONCATENATION/FR/sens$sens.txt; # concatčne tous les fichiers francais de meme sens
#echo "******************************" >> $chemin/CONCATENATION/FR/sens$sens.txt;
let i+=1;
}
}
--------------------------------------------------------
information pour l'utilisateur: "ne t'inquičte pas, je travaille":)
et les męmes boucles pour l'anglais.
-------------------------------------------------------- echo "patience...";
for sens in `cat donneesCAT.txt`; #liste des sens, entree manuellement
{
i=1
for fichier in `ls $chemin/CONTEXTES/EN/$sens`
{
cat $chemin/CONTEXTES/EN/$sens/$i.txt >> $chemin/CONCATENATION/EN/sens$sens.txt; # concatene tous les fichiers anglais de meme sens
#echo "******************************" >> $chemin/CONCATENATION/EN/sens$sens.txt;
let i+=1;
}
}
echo "encore un peu...";
for sens in `cat donneesCAT.txt`; #liste des sens, entree manuellement
--------------------------------------------------------
pour le polonais on n'a pas de fichiers texte mais des html, ce qui fait qu'on doit concaténer les fichiers html et les nettoyer en enlevant les balises et en-tętes avant de faire des nuages:
-------------------------------------------------------- {
t=1
for page in `ls $chemin/CONTEXTES/PL/$sens`
{
cat $chemin/CONTEXTES/PL/$sens/$t.html >> $chemin/CONCATENATION/PL/sens$sens.html; # concatene tous les fichiers polonais de meme sens
#echo "******************************" >> $chemin/CONCATENATION/PL/sens$sens.html;
let t+=1;
}
}
echo "fini";
--------------------------------------------------------
aprčs, il faut donc ouvrir tous les fichiers en NOTEPAD++ (et seulement ces 7 fichiers) et faire le ménage dedans.
J'ai utilisé les expressions réguličres et fonction "remplacer tout dans les fichiers ouverts".
-------------------------------------------------------- ****************************************************************************
il faut donc
1. s'assurer que les dossiers sont vides:
2. changer le répertoire pour le répertoire de travail
3. lancer le script general:
il travaille, on le voit:
ici, c'est le minigrep qui travaille:
etc.
une fois que c'est fini, on lance le script de concaténation :
les nuages peuvent ętre réalisées en utilisant Wordle
2.3 script général
2.4 script pour concaténer
Pour lancer le script,