BAO3
Dans la BAO 3, nous avons extrait les patrons NOM ADJ et NOM PREP NOM à partir des sorties étiquetées via Treetagger et Cordial. Nous allons présenter, dans un premier temps, l'extraction des patrons NOM ADJ et NOM PREP NOM, à partir de la sortie générée par Treetagger. Pour ce faire, nous avons utilisé une requête XPATH couplée à une feuille de styles XSL. En effet, pour pouvoir parcourir une arborescence XML et la transformer, il faut utiliser ces deux outils simultanément.
Nous avons donc élaboré trois feuilles de styles, afin d'obtenir le résultat souhaité. Un script Perl a également été utilisé pour extraire les patrons NOM ADJ et NOM PREP NOM, à partir de la sortie générée par Treetagger. Nous avons étudié ce script Perl dans la cadre du cours "Programmation pour le TAL en Perl Paris III - Agora" enseigné par M. Serge Fleury.
Dans un second temps, nous avons extrait les mêmes patrons, à partir de la sortie étiquetée avec Cordial. Nous avons utlisé, pour ce faire, deux scripts Perl. Le premier a été élaboré par M. Jean Michel Daube (Inalco) dans le cadre du cours "Programmation et projet encadré - 2ème semestre" et le second par M. Serge Fleury dans le cadre du cours "Programmation pour le TAL en Perl Paris III - Agora".
Avant d'entrer dans le coeur de la BAO 3, nous vous proposons une définition de XPATH et XSLT. Précisons que nous nous sommes basés sur les définitions proposées par le cours "Document structuré" de M. Serge Fleury (L8T06). Les slides de ce cours peuvent être consultés sur Le site Agora de Paris 3.
XSLT
Complément indispensable dXML, le langage XSL a deux principaux usages. Il permet dabord de convertir un document XML en un format adapté à laffichage ou à limpression (HTML pour le Web, RTF ou PDF pour limpression, etc.). Mais XSL est bien plus quun simple langage de feuilles de styles, cest aussi un véritable langage de programmation, grâce auquel on peut effectuer toutes sortes de traitements sur les documents XML : en modifier la structure, en extraire des informations, en filtrer le contenu, etc.
XPATH
XPath est un standard du W3C pour décrire des localisations de noeud et extraire des valeurs de l'arbre du document XML. En effet, pour pouvoir transformer un document XML, il faut pouvoir extraire des fragments XML (noeuds) d'un document, donc définir ces fragements.
Extraction de patrons à partir de la sortie étiquetée avec Treetagger
1- Extraction avec une requête XPATH et une feuille de styles XSL (méthode 1)
* Extraction du patron NOM ADJ
Nous avons commencé, tout d'abord, par mettre notre fichier étiqueté avec Treetagger dans la console XML de Cooktop, comme le montre l'image qui suit.
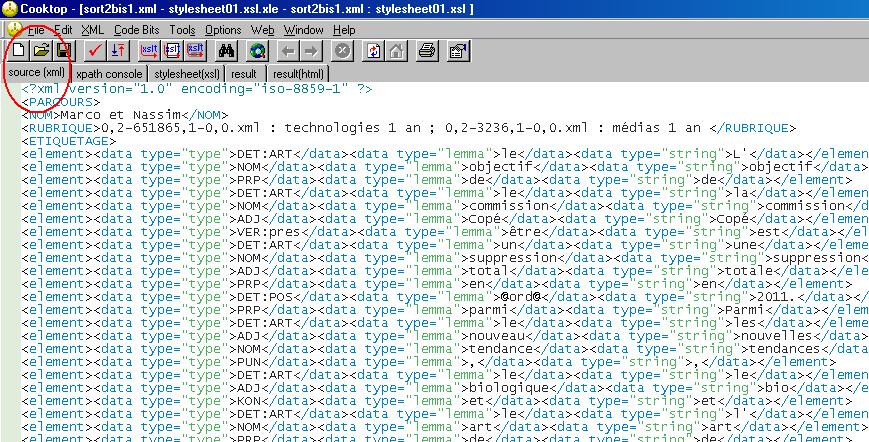
Cliquez sur l'image pour l'agrandir
haut de page
Nous avons, par la suite, écrit notre requête Xpath dans la console Xpath de Cooktop, comme on peut le voir ci-dessous.
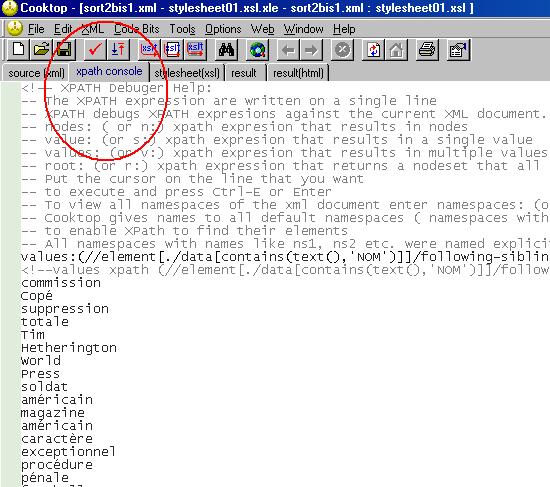
Cliquez sur l'image pour l'agrandir
On peut constater que le résultat n'est pas celui que l'on recherche. Nous avons alors intégré notre requête Xpath à notre feuille de styles (1). Nous pouvons y voir la sortie en mode HTML, l'espace entre le nom et l'adjectif grâce à la balise <xsl:text> et l'emplacement de la requête dans feuille de styles. Voir ci-dessous cette feuille de styles.
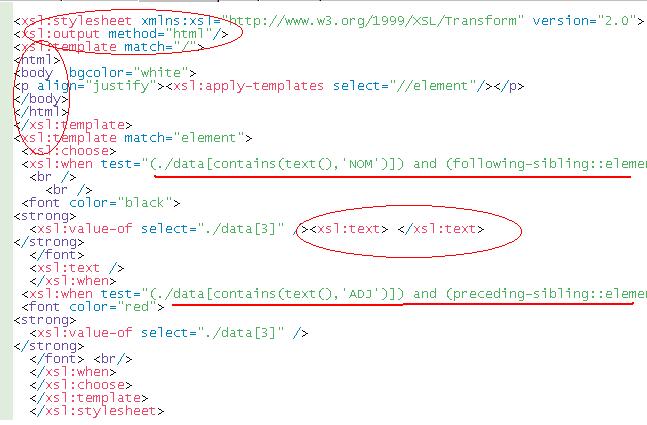
Cliquez sur l'image pour l'agrandir
haut de page
Grâce à cette feuille de styles, on obtient un résultat satisfaisant, comme on peut le voir ci-dessous. Cependant, nous voulions l'améliorer, afin de l'intégrer à un tableau avec l'aide de M. Serge Fleury.

Cliquez sur l'image pour l'agrandir
Pour obtenir une sortie HTML dans un tableau, nous avons utilisé notre feuille de styles (2) qui suit.
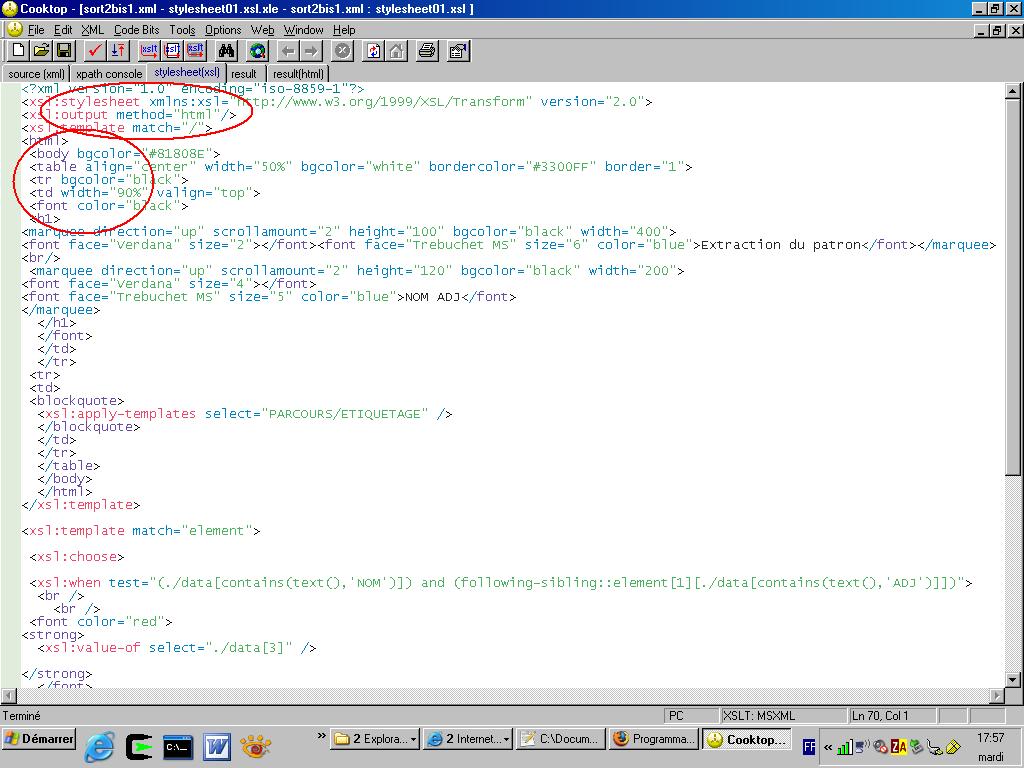
Cliquez sur l'image pour l'agrandir
haut de page
Avec cette feuille de styles améliorée, nous obtenons une sortie HTML du patron NOM ADJ dans un tableau, comme on peut le voir ci-dessous.
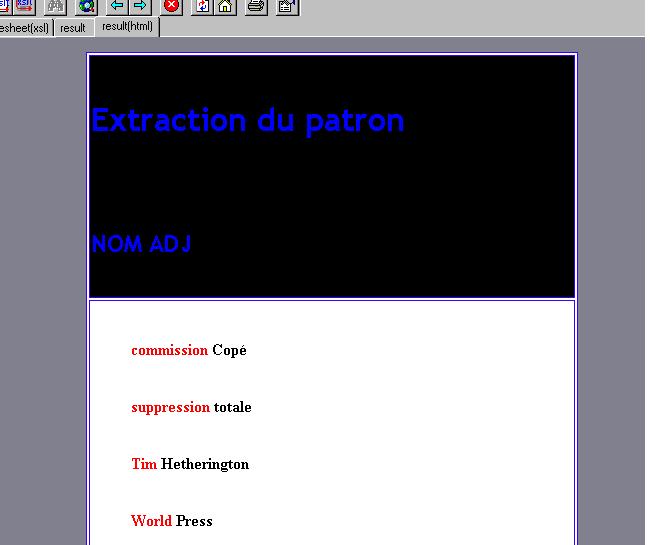
Cliquez sur l'image pour l'agrandir
haut de page
Pour obtenir une sortie au format texte sans balises qui soit adaptée à la BAO 4, nous avons utilisé notre feuille de styles (3), en précisant que la sortie doit être au format texte, comme on peut le voir ci-dessous.
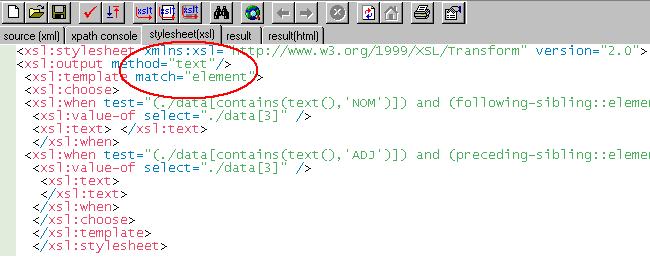
Cliquez sur l'image pour l'agrandir
Avec cette feuille de styles, nous obtenons une sortie du patron NOM ADJ, comme on peut le voir ci-dessous.
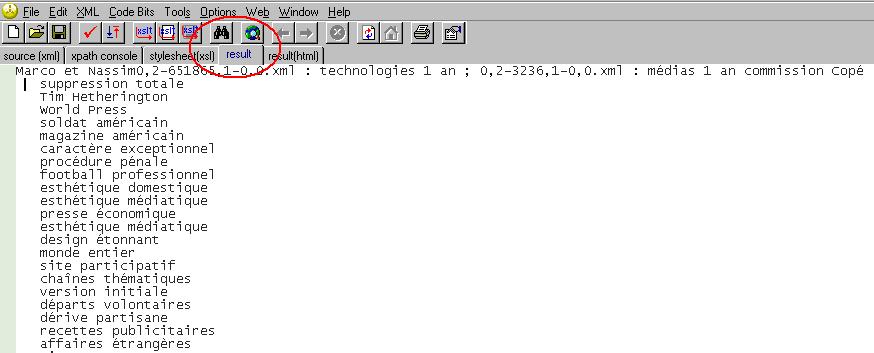
Cliquez sur l'image pour l'agrandir
Cette sortie répond à nos exigences. Mais on peut remarquer que le contenu de la balise <NOM> et <RUBRIQUE> gène l'affichage des patrons. Pour résoudre ce problème, nous avons supprimé ces deux balises dans le fichier XMl étiqueté et relancé la transformation sur Cooktop. Le résultat répond enfin à toutes nos exigences, comme on peut le voir ci-dessous.

Cliquez sur l'image pour l'agrandir
haut de page
Télécharger le fichier étiqueté sans balises <NOM> et <RUBRIQUE>
Télécharger la sortie générée par la feuille de styles (3)
Á présent, nous vous proposons, dans la première colonne du tableau qui suit, les deux premières feuilles de style que nous avons présentées plus haut (1 et 2). Dans la deuxième colonne, nous avons mis le fichier XML étiqueté, qui pointe vers sa feuille de styles. Nous obtenons alors une transformation XSLT dès lors que l'on clique sur le fichier XML.
| Résultats de l'extraction | |
|---|---|
| feuille de styles (1) | Fichier XML étiqueté pour la sortie normale |
| feuille de styles (2) | Fichier XML étiqueté pour la sortie améliorée |
* Extraction du patron NOM PREP NOM
Pour l'extraction du patron NOM PREP NOM, nous avons utlisé deux feuilles de styles munies d'une requête XPATH. La première génère, comme on peut le voir ci-dessous, une sortie HTML
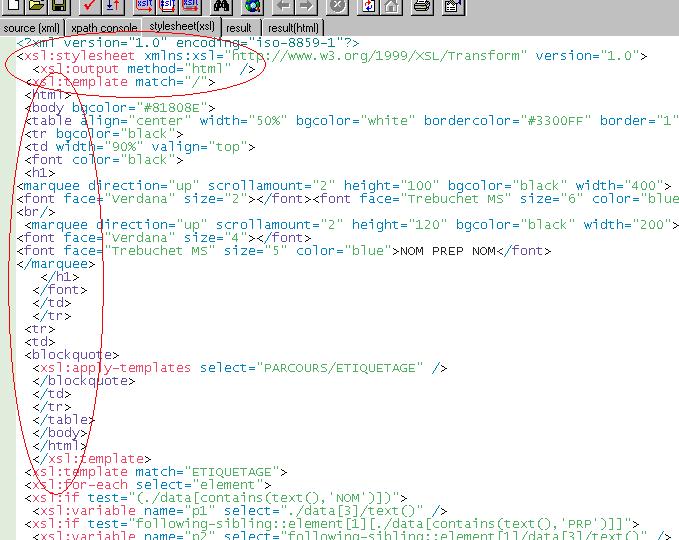
Cliquez sur l'image pour l'agrandir
Cliquez ici pour voir le résultat de la transformation avec la feuille de styles.
La seconde feuille de styles génère une sortie au format texte pour la BAO 4, comme on peut le voir ci-dessous.
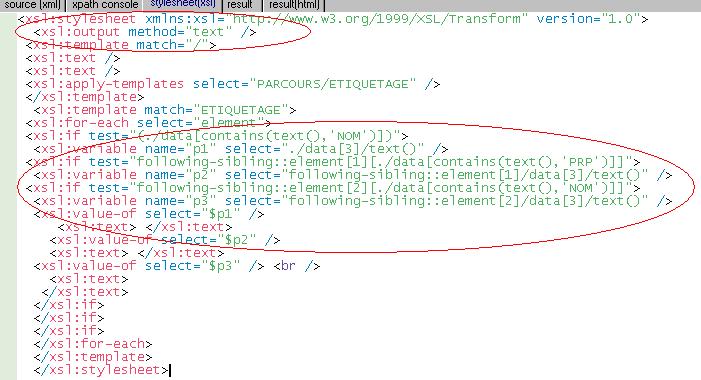
Cliquez sur l'image pour l'agrandir
haut de page
Cliquez ici pour voir le résultat de la transformation.
2- Extraction avec un script Perl à partir de la sortie étiquetée avec Treetagger (méthode 2)
Dans le cadre du cours "Programmation pour le TAL en Perl Paris III - Agora", nous avons étudié un script Perl pour extraire des patrons syntaxiques à partir de la sortie étiqueté avec Treetagger. Nous avons adapté ce script pour qu'il puisse extraire le patron NOM ADJ et NOM PREP NOM.
Le script Perl qui sert à extraire le patron NOM ADJ
#/usr/bin/perl
open(FILE,"$ARGV[0]");
open (FILEOUT, ">sortie_SF_NOMADJ_tree.txt");
my @lignes=<FILE>;
close(FILE);
while (@lignes) {
my $ligne=shift(@lignes);
chomp $ligne;
my $sequence="";
my $longueur=0;
if ( $ligne =~ /<element><data type=\"type\">NOM<\/data><data type=\"lemma\">[^<]+<\/data><data type=\"string\">([^<]+)<\/data><\/element>/) {
my $forme=$1;
$sequence.=$forme;
$longueur=1;
my $nextligne=$lignes[0];
if ( $nextligne =~ /<element><data type=\"type\">ADJ<\/data><data type=\"lemma\">[^<]+<\/data><data type=\"string\"><([^<]+)<\/data><\/element>/) {
my $forme=$1;
$sequence.=" ".$forme;
$longueur=2;
}
}
if ($longueur == 2) {
print FILEOUT "$sequence\n";
}
}
close(FILE);
close(FILEOUT);
Dans ce script on met, dans un premier temps, toutes les lignes du fichier XML (Treetagger), dans un tableau (@lignes). Ensuite, on prend le premier indice du tableau grâce à la fonction shift et on l'affecte à la variable my $ligne. On enlève les sauts de ligne et on initialise à vide la variable $sequence, qui va contenir le patron NOM ADJ.
On utilise, par la suite, deux boucles if imbriquées, qui vont filtrer le patron que l'on recherche. Grâce à une expression régulière en bleu (tout sauf chevron), on récupère, dans chaque boucle if, le motif (forme graphique = string) dans la variable prédéfinie $1. Si la variable $longueur équivaut à la valeur == 2, alors on imprime le contenu de la variable $sequence.
Cliquez ici pour voir la sortie du patron NOM ADJ.
Le script Perl qui sert à extraire le patron NOM PREP NOM
#/usr/bin/perl
open(FILE,"$ARGV[0]");
open (FILEOUT, ">sortie_SF_NOMPRPNOM_tree.txt");
my @lignes=<FILE>;
close(FILE);
while (@lignes) {
my $ligne=shift(@lignes);
chomp $ligne;
my $sequence="";
my $longueur=0;
if ( $ligne =~ /<element><data type=\"type\">NOM<\/data><data type=\"lemma\">[^<]+<\/data><data type=\"string\">([^<]+)<\/data><\/element>/) {
my $forme=$1;
$sequence.=$forme;
$longueur=1;
my $nextligne=$lignes[0];
if ( $nextligne =~ /<element><data type=\"type\">PRP.*<\/data><data type=\"lemma\">[^<]+<\/data><data type=\"string\">([^<]+)<\/data><\/element>/) {
my $forme=$1;
$sequence.=" ".$forme;
$longueur=2;
my $nextligne=$lignes[1];
if ( $nextligne =~ /<element><data type=\"type\">NOM<\/data><data type=\"lemma\">[^<]+<\/data><data type=\"string\">([^<]+)<\/data><\/element>/) {
my $forme=$1;
$sequence.=" ".$forme;
$longueur=3;
}
}
}
if ($longueur == 3) {
print FILEOUT "$sequence\n";
}
}
close(FILE);
close(FILEOUT);
Cliquez ici pour voir la sortie du patron NOM PREP NOM.
Ce script a le même fonctionnement que le premier, qui extrait le patron NOM ADJ. Cependant, nous l'avons modifié dans la deuxième boucle if (en rouge), en utilisant une expression régulière (.*) pour pouvoir prendre en compte certains patrons NOM PREP NOM, dont le second élément peut être une "PRP:det", comme on peut le voir dans l'image ci-dessous. Grâce à cette modification, on récupère 186 patrons NOM PREP NOM, au lieu de 107 patrons sans cette modification.

Cliquez sur l'image pour l'agrandir
haut de page
Á la suite de l'extraction du patron NOM ADJ et NOM PREP NOM avec un script Perl (méthode 2), nous avons constaté que le nombre de patrons NOM ADJ (127 patrons) et NOM PREP NOM (186 patrons) était le même comparé aux résultats obtenus, plus haut, avec la requête XPATH couplée à une feuille de styles (méthode 1).
On peut conclure que bien que la méthode d'extraction soit différente (XPATH-XSL VS script Perl), le résultat est le même, car le fichier étiqueté est le même. En effet, les mêmes anomalies sont observées avec les deux méthodes d'extraction. On trouve, par exemple, les mauvais patrons NOM ADJ "site Internet" (Internet n'est pas un adjectif), "box ADSL" (ADSL n'est pas un adjectif) ou "Laurence Parisot" (Parisot n'est pas un adjectif) et l'absence du patron "vie commune" pour les raisons que nous avons déjà évoquées dans la BAO 2. On trouve aussi le patron NOM PREP NOM "début 2009 C'", avec les deux méthodes d'extraction. Ce patron est le résultat d'un étiquetage incorrect.
Concernant le patron NOM PREP NOM, les deux méthodes d'extraction génèrent une sortie assez volumineuse comparée à celle que on a obtenue avec l'étiquetage de Cordial (cf. infra, Extraction de patrons à partir de la sortie étiquetée avec Cordial).
Ceci s'explique, entre autres, par le fait que Treetagger étiquette le token du dans des patrons comme "propriétaire du journal" ou "holding du groupe", comme une préposition:déterminant. On verra que dans la sortie de Cordial du patron NOM PREP NOM, ce type de patrons est absent, car du est reconnu comme un déterminant.
Extraction de patrons à partir de la sortie étiquetée avec Cordial
1- Extraction du patron NOM ADJ
* Extraction du patron NOM ADJ avec le premier script
Le script, ci-dessous, prend en entrée deux paramètres. Le premier paramètre est le fichier étiqueté avec Cordial au format cnr. Le second paramètre est un fichier au format texte, qui contient la liste des patrons que l'on recherche.
#/usr/bin/perl
# use locale;
open(FICCORDIAL, "$ARGV[0]");
open (OUT, ">sortiecordNOMADJ_JMD.txt");
while ($ligne= <FICCORDIAL>) {
next if ($ligne!~/\t/);
chomp $ligne;
if ($ligne !~/PCT/){ #on s"arrete à la ponctuation.
@decoup=split(/\t/, $ligne);
push (@token, $decoup[0]);
push (@lemme, $decoup[1]);
push (@partof, $decoup[2]);
$i++;#comptage des parties du discours.
}
else {
open(FICPATRONS, "$ARGV[1]");
while ($patrons=<FICPATRONS>) {
chomp $patrons;
my $compare="";
#foreach my $element(@partof) {
#$compare=$compare."\t".$element;
#}
$compare=join("\t", @partof);
my $j=0;
my $k=0;
while ($compare=~/$patrons/g) {
my $avant = $`;
my $apres = $';
while ($avant=~/\t/g) {$j++};
while ($apres=~/\t/g) {$k++};
print OUT "@token[$j..$i-$k-1]\n";
$j=0;
$k=0;
}
}
close (FICPATRONS);
$i=0;
@token=();
@lemme=();
@partof=();
}
}
Dans ce script, on commence d'abord par lire chaque ligne du fichier étiqueté avec une boucle while. Avec un next if, on saute les lignes, qui ne contiennent pas une tabulation. On supprime, avec la fonction chomp les éventuels retour à la ligne. Si la ligne ne contient pas une ponctuation (PCT), on fait le traitement en rouge. Dans ce traitement, il s'agit de segmenter, grâce à la commande split, chaque ligne du fichier en entrée en trois colonnes, avec comme séparateur une tabulation (\t).
On obtient trois colonnes d'éléments. Chaque colonne du fichier est placée dans un tableau (@token, @lemme, @partof), grâce à la commande puch. Si la ligne contient une ponctuation, on passe au traitement de la boucle else. Dans cette dernière, on lit le deuxième paramètre et on enlève les éventuels retours à la ligne. On initialise à vide la variable $compare, qui va contenir les éléments du tableau @partof séparés par une tabulation. On utilise la commande join pour transférer le contenu du tableau @partof dans la variable scalaire $compare. Pour effectuer cette opération, on peut aussi utiliser une boucle foreach (en bleu), qui concatener les parties du discours avec une tabulation (\t) avant de trouver un PCT (ponctuation). Rappelons qu'avec cette méthode, on doit spécifier dans cette ligne : print OUT "@token[$j-1..$i-$k-1]\n";.
L'étape qui suit est la création de deux variable ($j et $k), auxquelles on affecte la valeur "0". Une boucle while permet, ensuite, de comparer la liste des patrons que l'on recherche stockée dans la variable $patrons avec les parties du discours, qui se trouvent dans la variable $compare. S'il il y a correspondance entre ces deux variables, alors on identifie et on imprime les tokens (mots) qui correspondent aux parties du discours du patron recherché. Pour ce faire, on utilise un paramétrage des indices du tableau @token (@token[$j..$i-$k-1]) pour faire une bijection (cf. la ligne en vert) entre les parties du discours de $compare et les éléments de @token.
Pour lancer ce premier script, nous avons utlisé une liste de 33 patrons NOM ADJ. Celle-ci contient toutes les combinaisons possibles, sauf celles qui contiennent des noms propres. Autrement dit, on extrait tous les noms communs quelque soit le genre et le nombre du nom et de l'adjectif. On prend également en compte les adjectifs numéraux, comme on peut le voir ci-dessous.
NCFS ADJFS
NCMS ADJMS
NCMS ADJINV
NCMS ADJFS
NCFIN ADJFS
NCI ADJHFS
NCMS ADJIND
NCFS ADJSIG
NCFS ADJNUM
NCFP ADJPIG
NCFP ADJIND
NCMP ADJPIG
NCMP ADJIND
NCMP ADJMS
NCFS ADJIND
NCFP ADJFP
NCMS ADJSIG
NCPIG ADJMIN
NCPIG ADJIND
NCPIG ADJMP
NCMS ADJMIN
NCMIN ADJMP
NCMIN ADJINV
NCMIN ADJIND
NCMS ADJMP
NCSIG ADJSIG
NCFS ADJMP
NCSIG ADJFS
NCMIN ADJMS
NCMP ADJMIN
NCMP ADJMP
NCMP ADJSIG
NCFS ADJMS
Cliquez ici pour télécharger cette liste de patrons
Cliquez ici pour télécharger le premier script Perl
haut de page
On obtient alors 132 patrons NOM ADJ. Parmi ces patrons, on trouve trois patrons ayant comme deuxième éléments un adjectif numéral, selon l'étiquetage de Cordial :
Exposition L' ;
Exposition L' ;
tranche 13-24.
On remarque que les deux premiers patrons sont extraits suite à étiquetage erroné.
En outre, on relève d'autres patrons, qui sont issus d'un mauvais étiquetage :
* DVD haute (haute ne modifie pas DVD, car il réfère au mot "définition" qui suit) ;
* pays le plus (le plus n'est pas un adjectif) ;
* écrans plus de (plus de n'est pas un adjectif) ;
* départ d'ici (d'ici n'est pas un adjectif).
Cliquez ici pour télécharger la sortie de patrons NOM ADJ - premier script Perl - Cordial
* Extraction du patron NOM ADJ avec le deuxième script Perl
Nous présentons, ci-dessous, un deuxième script Perl pour extraire le patrons NOM ADJ. Nous avons étudié ce script dans le cadre du cours "Programmation pour le TAL en Perl Paris III - Agora".
#/usr/bin/perl
open(FILE,"$ARGV[0]");
open (FILEOUT, ">sortie_SF_NOMADJ.txt");
my @lignes=<FILE>;
close(FILE);
while (@lignes) {
my $ligne=shift(@lignes);
chomp $ligne;
my $sequence="";
my $longueur=0;
if ( $ligne =~ /^([^\t]+)\t[^\t]+\tNC.*/) {
my $forme=$1;
$sequence.=$forme;
$longueur=1;
my $nextligne=$lignes[0];
if ( $nextligne =~ /^([^\t]+)\t[^\t]+\tADJ.*/) {
my $forme=$1;
$sequence.=" ".$forme;
$longueur=2;
}
}
if ($longueur == 2) {
print FILEOUT "$sequence\n";
}
}
close(FILE);
close(FILEOUT);
Cliquez ici pour télécharger le deuxième script Perl
On remarque que ce script a le même mode de fonctionnement que le script que nous avons utilisé plus haut pour extraire le patron NOM ADJ à partir de la sortie étiquetée avec Treetagger. Cependant, une légère modification (en rouge) a été apportée. En effet, dans la sortie étiquetée avec Cordial, la spécificité du genre et du nombre doit être prise en compte. Une expression régulière (.*) est donc nécessaire pour extraire les patrons.
Par ailleurs, on obtient une liste composée de 128 patrons NOM ADJ. On constate qu'il y a une différence de quatre patrons, si on compare cette liste avec celle qu'on nous avons obtenue, plus haut, avec le premier script Perl. Ces quatre patrons sont les suivants :
Exposition L' ;
Exposition L' ;
Bouclettes locales ;
écran plus de.
Dans les trois premiers patrons, il y a des guillemets ", entre le nom et l'adjectif. Dans le dernier patron, on trouve un \r entre le nom et l'adjectif, comme on peut le voir dans les captures d'écran ci-dessous :
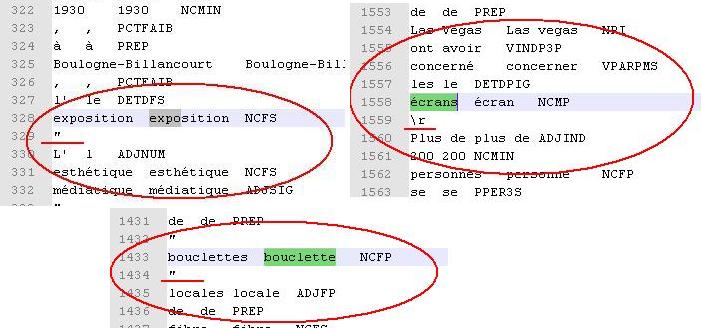
haut de page
Les expressions régulières qu'utilise ce deuxième script ne prennent pas en compte les cas où il y a des guillemets ou un \r entre la première et la deuxième séquence du patron NOM ADJ. Cependant, ce script est facilement adaptable pour extraire d'autres patrons.
Cliquez ici pour télécharger la sortie de patrons NOM ADJ - deuxième script Perl - Cordial
2- Extraction du patron NOM PREP NOM
Les deux scripts que nous allons voir, à présent, sont les mêmes que nous avons employés dans la partie précédente. La seule différence réside dans la spécification de la liste de patrons NOM PREP NOM pour le premier script Perl et la modification de l'expression régulière dans le deuxième script Perl.
* Extraction du patron NOM PREP NOM avec le premier script
Comme ce script n'a pas été modifié, nous présentons seulement la liste des patrons (53) NOM PREP NOM que l'on recherche.
NCFS PREP NCFS
NCMS PREP NCMS
NCMS PREP NCFS
NCFS PREP NCMS
NPFS PREP NCMS
NCMP PREP NCFS
NCFP PREP NCFS
NCMS PREP NCMP
NCMIN PREP NPSIG
NCMP PREP NCMP
NCFS PREP NPMS
NCFS PREP NPFS
NCFS PREP NPI
NCFS PREP NPSIG
NCMP PREP NCMIN
NCMS PREP NPMS
NPMS PREP NPI
NCFS PREP NCMP
NCFS PREP NCMIN
NCMS PREP NPFS
NCMS PREP NCFP
NPI PREP NCFS
NCMS PREP NCPIG
NCSIG PREP NCFS
NCFP PREP NCMP
NCMIN PREP NPMS
NCMP PREP NCI
NCMS PREP NPSIG
NPMS PREP NPSIG
NCMIN PREP NCFS
NCMP PREP NCFP
NCFP PREP NPI
NPI PREP NPMIN
NCFS PREP NPMIN
NCMS PREP NCI
NCMS PREP NCMIN
NCMIN PREP NPI
NCPIG PREP NPFS
NCMS PREP NPI
NCFP PREP NCPIG
NCMP PREP NPFS
NCFP PREP NCMIN
NCMP PREP NCMS
NCI PREP NPSIG
NCPIG PREP NCFP
NCFP PREP NPFS
NCI PREP NCMP
NCFP PREP NPMS
NCFS PREP NCFP
NCI PREP NCMIN
NCPIG PREP NCMIN
NPMS PREP NCMS
NPI PREP NCI
Cliquez ici pour télécharger cette liste de patrons
haut de page
À travers la lecture de cette liste, nous pouvons remarquer que nous avons pris en compte toutes les combinaisons de NOM PREP NOM, y compris celles qui sont composées de noms propres. On obtient 129 patrons NOM PREP NOM.
Signalons, quand même, une anomalie au niveau de l'étiquetage de Cordial à la ligne 1875, laquelle a généré un mauvais patron NOM PREP NOM, comme le montre l'image ci-dessous. En effet, "Evoqué" n'est pas un NOM. Treetagger réagit, d'ailleurs, de la même manière en considérant "Evoqué" comme un NOM (ligne 1871).

Cette anomalie est due, selon Cordial, à une erreur d'orthographe.
On note également l'absence des patrons "holding du groupe", "propriétaire du journal" et "transformation du château", car du est reconnu comme un déterminant, alors que Treetagger l'étiquette comme un PRP:det (cf. supra, Extraction de patrons à partir de la sortie étiquetée avec Treetagger).
Cliquez ici pour télécharger la sortie de patrons NOM PREP NOM - premier script Perl - Cordial
* Extraction du patron NOM PREP NOM avec le deuxième script Perl
#/usr/bin/perl
open(FILE,"$ARGV[0]");
open (FILEOUT, ">sortie_SF_NOMPRPNOM.txt");
my @lignes=<FILE>;
close(FILE);
while (@lignes) {
my $ligne=shift(@lignes);
chomp $ligne;
my $sequence="";
my $longueur=0;
if ( $ligne =~ /^([^\t]+)\t[^\t]+\tN.*/) {
my $forme=$1;
$sequence.=$forme;
$longueur=1;
my $nextligne=$lignes[0];
if ( $nextligne =~ /^([^\t]+)\t[^\t]+\tPREP/) {
my $forme=$1;
$sequence.=" ".$forme;
$longueur=2;
my $nextligne=$lignes[1];
if ( $nextligne =~ /^([^\t]+)\t[^\t]+\tN.*/) {
my $forme=$1;
$sequence.=" ".$forme;
$longueur=3;
}
}
}
if ($longueur == 3) {
print FILEOUT "$sequence\n";
}
}
close(FILE);
close(FILEOUT);
Cliquez ici pour télécharger le deuxième script Perl
Ce script prend en entrée le fichier étiqueté avec Cordial et génère une liste de patrons NOM PREP NOM. Trois boucles if sont utilisées pour aboutir à ce résultat. On peut constater, en rouge dans la première et troisième boucle if, l'expression régulière (.*) pour récupérer toutes les combinaisons possibles. Rappelons que le métacaractère . signifie un caractère quelconque, sauf \n (comportement par défaut, modifiable). Le métacaractère * marque la possible répétition du caractère précédent (ou de l'expression précédente entre parenthèses). On obtient alors 129 patrons NOM PREP NOM.
Cliquez ici pour télécharger la sortie de patrons NOM PREP NOM - deuxième script Perl - Cordial
Ce résultat montre que pour le patron NOM PREP NOM, l'utilisation de deux scripts différents permet d'avoir le même nombre de patrons, sans doute à cause de l'utilisation d'un même fichier étiqueté. Ce qui n'est pas le cas pour le patron NOM ADJ (cf. supra, 1- Extraction du patron NOM ADJ).