BAO1
Dans la BAO 1, nous allons présenter le script qui nous a permis d'extraire, de filtrer et de nettoyer le contenu de la balise <description>. Mais avant d'obtenir le script final, nous sommes passés par plusieurs étapes intermédiaires que nous allons décrire dans ce qui suit.
Les scripts Perl
1- Le filtreur (phase 1)
#!/usr/bin/perl
open(FILEINPUT,"$ARGV[0]");
while ($ligne = <FILEINPUT>){
if ($ligne=~/REGEXP/) {
print $ligne;
}
}
close(FILEINPUT) ;
Dans ce premier script, il s'agit d'identifier les lignes qui contiennent l'expression régulière que l'on recherche. Pour ce faire, on ouvre un fichier en lecture. Ensuite, on utilise une boucle while pour lire le fichier. Tant qu'il y a une ligne à lire, on entre dans la boucle "if". Dans la condition de cette boucle "if", on doit spécifier le motif de l'expression régulière. Et l'instruction de cette boucle représente l'impression de la ligne qui contient cette expression régulière.
Cliquez ici pour télécharger notre filtreur (phase 1)
2- Le nettoyeur
Dans ce premier script,
#!/usr/bin/perl
open(FILEINPUT,"$ARGV[0]");
while ($ligne = <FILEINPUT>){
$ligne=~s/RECHERCHE/REMPLACEMENT/g;
print $ligne;
}
close(FILEINPUT);
Dans ce deuxième script, il s'agit de nettoyer les lignes qu'on obtient après avoir lu le fichier avec la boucle while. La ligne en gras montre qu'on remplace l'élément qu'on recherche par un autre. Par ailleurs on remarque l'utilisation du modificateur g, qui permet d'effectuer une recherche globale de toutes les occurrences.
Cliquez ici pour télécharger notre nettoyeur
haut de page
3- Le filtreur (phase 2)
#!/usr/bin/perl
open(FILEIN,"$ARGV[0]"); # on ouvre le fichier qu'on va lire
open(FILEOUT, ">resultatsMODIF.txt"); # on ouvre le fichier sur lequel on va écrire
$i=1; # compteur qui sert à numertorer les lignes filtrées
while ($ligne = <FILEIN>){ # tant qu'il y a qqch à lire, on rentre dans la boucle, le perl ne fonctionne que par ligne
if ($ligne=~/<description>([^<]+)<\/description>/){ # si on trouve ce motif, on entre dans la boucle
print FILEOUT "contenu de la ligne n°$i : $1\n";
$i++; # on incrémente le compteur
}
}
close(FILEIN);
close(FILEOUT);
Dans ce troisième script, on remarque, en gras, plusieurs modifications. En effet, le filtreur (phase 2) comporte une ligne qui permet d'ouvrir un fichier en écriture. Dans les précédents scripts, l'impression du résultat se fait directement sur la ligne de commande. Par ailleurs, on remarque l'ajout d'un compteur pour numéroter les lignes.
Le filtreur (phase 2) permet aussi d'imprimer les lignes sans les deux balises <description> (ouvrante et fermante). Pour ce faire, on déspécialise le slash "/" de la balise fermante </description> grâce au métacaractère anti-slah "\". Ensuite, on récupère le motif qui est mis entre parenthèses grâce à une expression régulière et on l'affecte à la variable $1. Celle-ci est, ensuite, imprimée dans le fichier qui a été ouvert en écriture.
Cliquez ici pour télécharger notre filtreur (phase2)
haut de page
4- Le filtreur-nettoyeur
#!/usr/bin/perl
open(FILEIN,"$ARGV[0]");
open(FILEOUT, ">filtpropres.txt");
$i=1; #compteur qui sert à numertorer les lignes filtrées et nettoyées
while ($ligne = <FILEIN>){
if ($ligne=~/<description>([^<]+)<\/description>/){
my $propre=$1;
$propre=~s/é/é/g;
$propre=~s/ê/ê/g;
print FILEOUT "contenu de la ligne n°$i : $propre\n";
$i++;
}
}
close(FILEIN);
close(FILEOUT);
Dans ce quatrième script, il s'agit, tout simplement, de fusionner le nettoyeur avec le filtreur (phase 2).
Cliquez ici pour télécharger notre filtreur-nettoyeur
haut de page
5- Parcours arborescence
#/usr/bin/perl
#-----------------------------------------------------------
my $rep="$ARGV[0]";
# on s'assure que le nom du répertoire ne se termine pas par un "/"
$rep=~ s/[\/]$//;
# on initialise une variable contenant le flux de sortie
my $DUMPFULL1="";
#----------------------------------------
my $output1="SORTIE.xml";
if (!open (FILEOUT,">$output1")) { die "Pb a l'ouverture du fichier $output1"};
#----------------------------------------
&parcoursarborescencefichiers($rep); #recurse!
#----------------------------------------
print FILEOUT "<?xml version=\"1.0\" encoding=\"iso-8859-1\" ?>\n";
print FILEOUT "<PARCOURS>\n";
print FILEOUT "<NOM>Votre nom</NOM>\n";
print FILEOUT "<FILTRAGE>".$DUMPFULL1."</FILTRAGE>\n";
print FILEOUT "</PARCOURS>\n";
close(FILEOUT);
exit;
#----------------------------------------------
sub parcoursarborescencefichiers {
my $path = shift(@_);
opendir(DIR, $path) or die "can't open $path: $!\n";
my @files = readdir(DIR);
closedir(DIR);
foreach my $file (@files) {
next if $file =~ /^\.\.?$/;
$file = $path."/".$file;
if (-d $file) {
&parcoursarborescencefichiers($file); #recurse!
}
if (-f $file) {
# TRAITEMENT à réaliser sur chaque fichier
# Insérer ici votre code (le filtreur)
print $i++,"\n";
}
}
}
#----------------------------------------------
Ce cinquième script représente le programme qu'on utilise pour parcourir l'arborescence des fils RSS (fichiers). Autrement dit, le répertoire qui contient les fils RSS au format XML. Avec les précédents scripts, il n'est pas possible de passer en argument un répertoire au script Perl.
Pour parcourir l'arborescence d'un répertoire, on utilise le "Parcours arborescence" qui exécute plusieurs opérations.
Dans la première phase, on commence, d'abord, par affecter à la variable "$rep" le répertoire passé en argument. On s'assure que le nom du répertoire ne se termine pas par un slash, en substituant le slash en fin de chaîne par rien. Ensuite, on initialise, à vide, une variable scalaire locale (my $DUMPFULL1), qui va stocker l'ensemble des extractions.
Dans la seconde phase, on initialise une autre variable locale ($output1). Cette variable correspond au fichier physique, qui va contenir les caractères imprimés, dans lequel on va mettre l'ensemble des parties textuelles concaténées. On remarque également que la sortie est au format XML.
Dans la troisième phase, un appel de sous programme est effectué grâce au symbole &. Nous avons mis ce sous programme en rouge.
Dans la phase qui suit, on prépare la sortie avec plusieurs balises. Parmi ces balises, on a la balise <FILTRAGE>, qui va contenir la variable $DUMPFULL1.
Dans la dernière phase, on exécute le sous programme, lequel est défini par la commande sub. Il faut, par la suite, vérifier grâce à un next if si le nom du fichier contenu dans $file contient "..". Si c'est le cas, on passe au suivant, sinon on réécrit le chemin absolu qui pointe vers l'élément voulu. Pour ce faire, on ajoute le nom correct au reste du chemin ($path). On utilise, pour cette opération, le point, qui permet la concaténation de tous ces éléments. ($file = $path."/".$file;).
Dans la dernière phase, on vérifie si l'élément qui est contenu dans $file est un répertoire ou un fichier. Cette vérification se fait grâce à deux boucles if. La première utilise la commande -d, qui permet de s'assurer si l'élément est un répertoire. Si c'est le cas, alors on relance le parcours. La deuxième boucle if utilise la commande -f pour voir si l'élément est un fichier. Si la valeur est vraie, alors lance le traitement de filtrage et de nettoyage avec impression du résultat dans la variable $DUMPFULL1.
Cliquez ici pour télécharger notre Parcours arborescence
haut de page
6- Script final
#/usr/bin/perl
#-----------------------------------------------------------
my $rep="$ARGV[0]";
# on s'assure que le nom du répertoire ne se termine pas par un "/" si ça se termine par / on remplace par rien
$rep=~ s/[\/]$//;
# on initialise une variable contenant le flux de sortie
my $DUMPFULL1="";
my %tableaudestextes=();
#----------------------------------------
my $output1="Sortie.xml";
if (!open (FILEOUT,">$output1")) { die "Pb a l'ouverture du fichier $output1"};
#----------------------------------------
&parcoursarborescencefichiers($rep); # on appelle le sous programme
#----------------------------------------
sub parcoursarborescencefichiers { # on entre dans le sous programme
my $path = shift(@_); # on met dans la variable $path le contenu de la variable mise en argument
opendir(DIR, $path) or die "can't open $path: $!\n"; # opendir : ouvre un rep - si on arrive pas : le pgm s'arrete et on envoie un message d'erreur
my @files = readdir(DIR); # on lit le contenu du répertoire et on renvoie une liste qu'on stocke dans @files
closedir(DIR);
foreach my $file (@files) { # pour chaque ressource dans @files,on crèe $files
next if $file =~ /^\.\.?$/; # on passe au suivant si on trouve . ou .. car on risque une boicle infinie
$file = $path."/".$file; # on réécrit tout le chemin du fichier - le point permet la concaténation
if (-d $file) { # on entre dans cette boucle si il y a dans $file un répertoire (-d vérifie que l'argument est un répertoire)
&parcoursarborescencefichiers($file); #recurse!
}
if (-f $file) { # on entre dans cette boucle si il y a dans $file un fichier (-f vérifie que l'argument est un fichier)
if (($file=~/0,2-651865,1-0,0.xml/) || ($file=~/0,2-3236,1-0,0.xml/)){
open(FILEIN,$file); # on ouvre le fichier qu'on va lire
#$i=1; # compteur
printf "$file\n"; # on voit si ça travaille
while ($ligne = <FILEIN>){ # tant qu'il y a qqch à lire, on rentre dans la boucle
#chomp($ligne);
if ($ligne=~/<description>([^<]+)<\/description>/){
if (($ligne!~/Retrouvez *l.*ensemble *des/) && ($ligne!~/Lisez *l.*int.*gralit.* *de *l.*article *pour *plus *d.*information./) && ($ligne!~/Toute *l.*actualit.* *au *moment *de *la *connexion/)) {
my $propre=$1;# on prend le motif et on le met dans $propre
if ($propre=~/^(.+)<img width='1' height='1'.*$/) {$propre=$1};
$propre=~s/&#39;/\'/g;
$propre=~s/&#34;/\"/g;
$propre=~s/é/é/g;
$propre=~s/ê/ê/g;
$propre=~s/&eacute;/é/g;
$propre=~s/&egrave;/è/g;
$propre=~s/&icirc;/\î/g;
$propre=~s/&ocirc;/\ô/g;
$propre=~s/&ccedil;/\ç/g;
$propre=~s/&agrave;/\à/g;
$propre=~s/&/&/g;
$propre=~s/</\</g;
$propre=~s/>/\>/g;
if (exists($tableaudestextes{$propre})) {
$tableaudestextes{$propre}++;
}
else {
$DUMPFULL1.="$propre\n";
$tableaudestextes{$propre}++;
}
} # fin de if
} # fin de if
} # fin de while
close(FILEIN);
}
}
}
}
#----------------------------------------------
print FILEOUT "<?xml version=\"1.0\" encoding=\"iso-8859-1\" ?>\n"; # on dit que la sortie doit être au format XML
print FILEOUT "<PARCOURS>\n";
print FILEOUT "<NOM>Marco et Nassim</NOM>\n";
print FILEOUT "<RUBRIQUE>0,2-651865,1-0,0.xml : technologies 1 an ; 0,2-3236,1-0,0.xml : médias 1 an </RUBRIQUE>\n";
print FILEOUT "<FILTRAGE>".$DUMPFULL1."</FILTRAGE>\n";
print FILEOUT "</PARCOURS>\n";
close(FILEOUT);
exit;
Ce script final intègre un parcours arborescence, un filtreur et un nettoyeur.
Tout d'abord, on remarque en bleu au début du script, l'initialisation à vide d'une nouvelle variable, qui est un tableau associatif précédé d'un %. Ce dernier permet d'éviter des lignes doublons. Rappelons qu'un "tableau associatif" est une structure qui permet de mettre en relation deux éléments de type scalaire. C'est un ensemble de couples de scalaires où l'un des éléments (la clé) référence l'autre (la valeur).
Ce tableau associatif va contenir les lignes qu'on imprime. Plus loin les boucles if et else en bleu permettent de faire un tri pour éviter les doublons. La boucle "if (exists($tableaudestextes{$propre}))" empêche les lignes déjà écrites d'être à nouveau écrites. La boucle else, quant à elle, effectue l'opération inverse, en écrivant les lignes qui n'ont pas encore été écrites. Ces lignes sont stockées dans le tableau associatif pour éviter les éventuels doublons.
Un peu plus loin, on remarque également que la sortie est au format XML (Sortie.xml).
Dans la partie ayant trait au filtrage, une boucle if permet de préciser les rubriques sur lesquelles on travaille (Technologies = 0,2-651865,1-0,0 ; Médias = 0,2-3236,1-0,0.xml).
Un peu plus loin on utilise une autre boucle if (if (($ligne!~/Retrouvez *l.*ensemble *des/) && ($ligne!~/Lisez *l.*int.*gralit.* *de *l.*article *pour *plus *d.*information./) && ($ligne!~/Toute *l.*actualit.* *au *moment *de *la *connexion/)) {). Celle-ci est un filtre qui permet de ne pas imprimer certaines lignes. On utilise des expressions régulières (. ; *) pour anticiper les éventuelles erreurs au niveau de certains caractères qui seraient mal encodés (e.g., é, è, ê, '). Juste après, on remarque une autre boucle if (if ($propre=~/^(.+)<img width='1' height='1'.*$/) {$propre=$1};). Cette dernière sert à ne pas imprimer d'éventuels balises images (pavés publicitaires), en récupérant le motif qui est entre parenthèses dans $1 puis dans $propre.
Dans la partie ayant trait au nettoyage que nous avons mise en rouge, on remarque qu'il y a beaucoup plus de lignes de remplacement, afin de bien recoder toutes les entités html et décimales que nous avons rencontrés durant le traitement de nos fils RSS.
Enfin, dans la dernière partie du script qui concerne la mise en forme de la sortie, on remarque l'ajout de la balise <rubrique>.
En sortie, on obtient un fichier au format XML, comme l'illustre la capture d'écran ci-dessous.
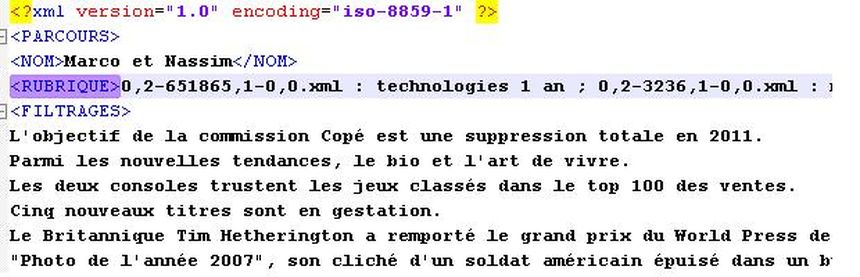
Cliquez ici pour télécharger la sortie en entier au format XML
Cliquez ici pour télécharger notre script final (pour Treetagger)
Pour obtenir une sortie au format txt, qui soit compatible avec les exigences de Cordial, le script final, que nous avons décrit plus haut, est un peu modifié. En effet, toutes les balises XML sont supprimées, car Cordial ne prend en entrée que des fichiers au format texte brut
Cliquez ici pour télécharger notre script final (pour Cordial)