ETAPE 1 : script parcours-arborescence-fichiers.pl
OBJECTIF : étiquetage des mots des parties textuelles extraites via CORDIAL
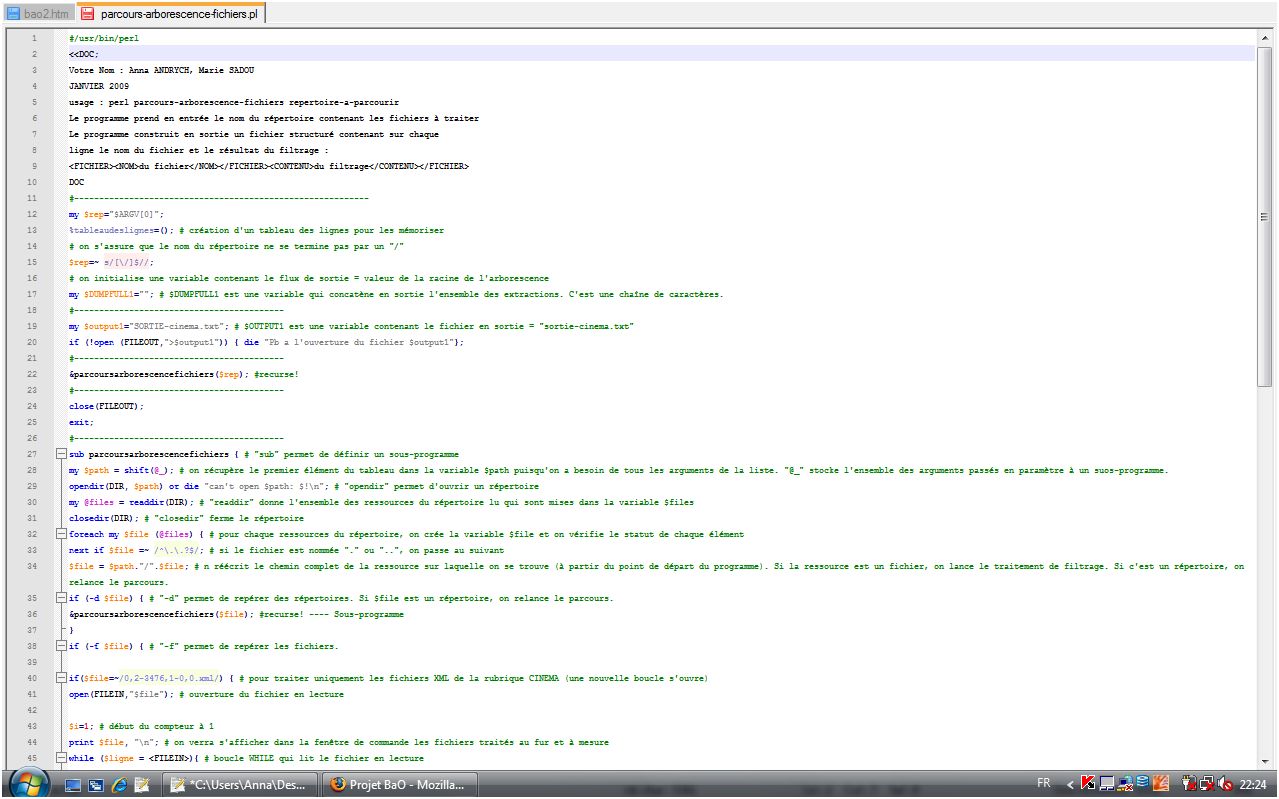
Cette Boîte à Outils 2 nous permet de réaliser un étiquetage des mots des parties textuelles extraites précédemment. Pour se faire, nous avons créé un script en PERL nommé parcours-arborescence-fichiers.pl. La structure globale de ce script nous a été fournie par M.Fleury, puis nous y avons ajouté notre programme de filtrage créé dans la BàO1.
Par ailleurs, l'étiquetage se fait en deux étapes. En effet, d'une part, nous avons traité nos fichiers avec l'étiqueteur CORDIAL. Ce dernier s'utilise via une interface graphique. D'autre part, nous avons eu recours à un autre étiqueteur nommé TREE-TAGGER. Celui-ci s'utilise en ligne de commande. Ainsi, notre script a du subir quelques modifications.
Etant donné que nous avons choisi de travailler sur deux rubriques, nous avons à chaque fois deux scripts. Chacun traitant une rubrique (CINEMA ou CULTURE). Enfin, les deux scripts ne sont pas pour autant si différents, ce ne sont que les noms des fichiers en entrée et en sortie qui vont changer.
Voici donc le script parcours-arborescence-fichiersCINEMA.pl relatif à la rubrique du CINEMA:
Pour voir le script traitant la rubrique CULTURE: parcours-arborescence-fichiersCULTURE.pl
Sorties obtenues grâce à CORDIAL :
Une fois le script lancé sur toute l'arborescence, on obtient en sortie un fichier au format TXT qui réunit toutes les concaténations des parties textuelles extraites : SORTIE-cinema.txt et SORTIE-culture.txt.
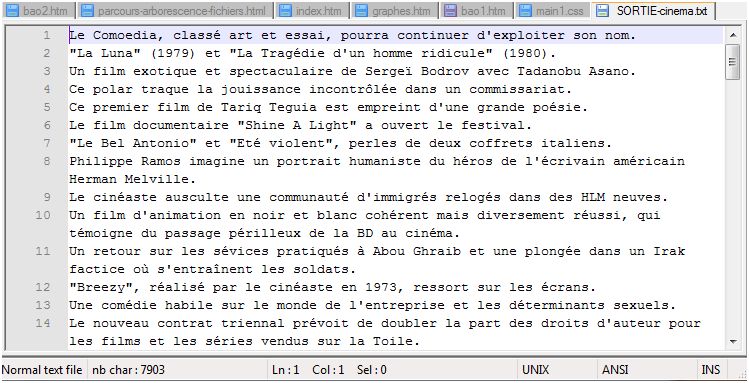
Ces fichiers doivent maintenant être traités par CORDIAL afin de pourvoir procéder au premier étiquetage.
Voici les résultats obtenus :
SORTIE-cinema-CORDIAL.cnr et SORTIE-culture-CORDIAL.cnr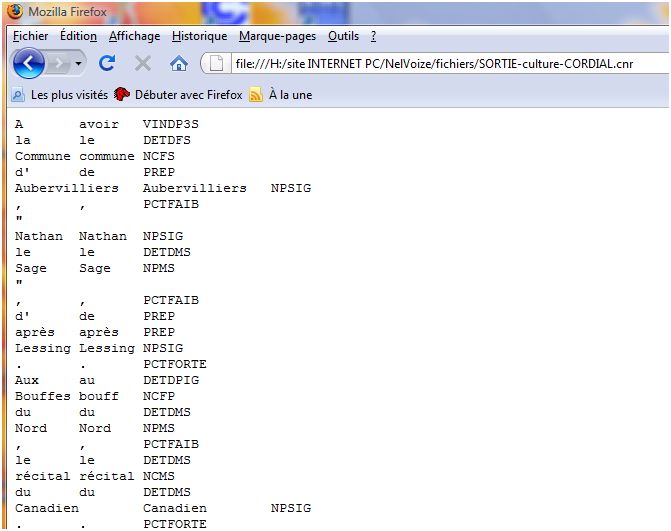
ETAPE 2 : script parcours-arborescence-fichiers2.pl
OBJECTIF : étiquetage via TREE-TAGGER
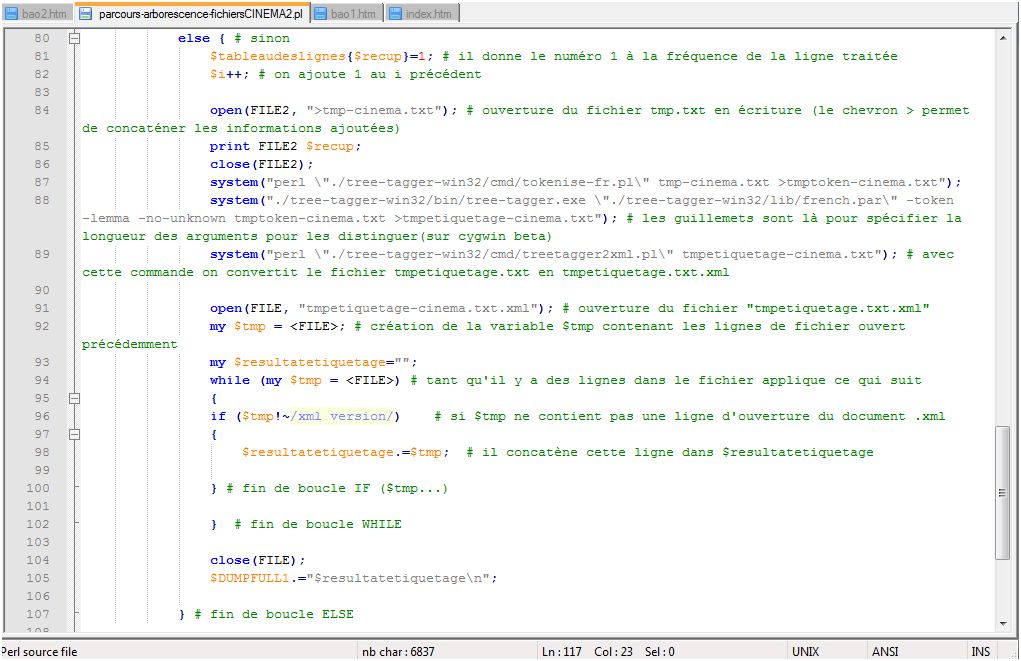
Afin de pouvoir procéder à l'étiquetage avec TREE-TAGGER, il a fallu que nous modifions une partie de notre script. En effet, nous incorporons à notre script la propriété de mettre un mot par ligne puis la phase d'étiquetage en elle-même.
Afin d'obtenir un mot par ligne et un fichier au format XML en sortie, M. Fleury nous a fourni deux scripts nommé tokenize.pl et treetagger2xml(dans le répertoire que nous avons du télécharger: treetagger-win32.zip).
Voici la partie que nous avons ajoutée à notre script parcours-arborescence-fichiersCINEMA2 pour la rubrique du CINEMA:
Pour voir le script traitant la rubrique CULTURE : parcours-arborescence-fichiersCULTURE2.
Sorties obtenues grâce à TREE-TAGGER :
Nous obtenons alors deux fichiers (un pour chaque rubrique) au format XML contenant un mot étiqueté par ligne : SORTIE-cinema2.xml et SORTIE-culture2.xml.
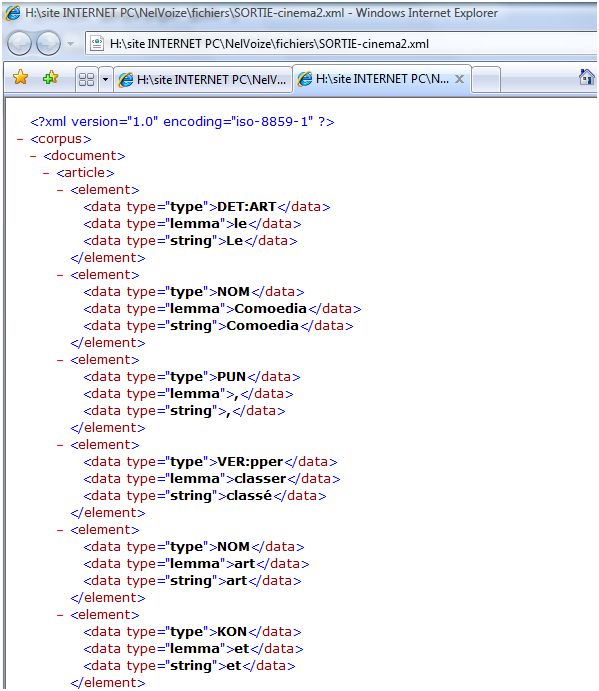
NB : On peut remarquer que les étiquettes des parties du discours ainsi que la présentation de la sortie diffèrent entre TREE-TAGGER et CORDIAL. En clair, l'étiqueteur des mots CORDIAL semble beaucoup plus précis dans la description des formes analysées que TREE-TAGGER. Par exemple, pour le mot spectaculaire, CORDIAL trouve comme catégorie ADJSIG (adjectif singulier) et TREE-TAGGER se limite à donner seulement ADJ (adjectif).
Nous avons eu quelques soucis avec TREE-TAGGER puisqu'au départ, nous n'avions pas mis les lignes supplémentaires, relatives à TREE-TAGGER au bon endroit dans notre script modifié. Ainsi, le programme écrasait constamment les résultats dans notre fichier de sortie et nous n'arrivions à récupérer uniquement la dernière phrase du dernier document traité.