Outils pour le script
Pour
arriver à obtenir un script digne de ce nom, nous avons
dû intégrer à notre script quelques
commandes ainsi que des expressions régulières.
./Commandes
| #!/bin/bash :
# ligne d'entête du script appellant l'interpréteur de commande bash. Cette commande permet l'execution du script. echo " " : # cette commande affiche sur la sortie standard la chaîne de caractères entre guillements. echo " " > fichier : # la chaine entre guillements sera enregistrée dans un fichier. Si le nom du fichier existe déjà, il sera écrasé, sinon # il sera tout simplement crée. echo " " >> fichier : # la chaine entre guillements sera enregistrée dans un fichier et concaténée à la chaîne déjà existente. read var : # lecture à partir de l'entrée standard (le clavier) et enregistrement dans la variable var. for file in `ls $rep` { ... } : # - ls $rep liste le contenu du repertoire rep. # - la boucle for file in `ls $rep` { ... } attribue à chaque ligne du listing la variable file et execute ce qu'il y a # entre les accollades. for file in `cat $rep` { ... } : # - cat $fic permet de lire le contenu d'un fichier # - la boucle for file in `cat $rep` { ... } attribue à chaque ligne du fichier contenu dans le repertoire rep # la variable file et execute ce qu'il y a entre les accollades. wget -O : # wget est une commande disponible sous la console UNIX. Elle permet d'aspirer localement des pages web. De nombreuses # options sont disponibles pour cette commande ici. La commande wget avec l'option -O permet de specifier le chemin où # devra être sauvegardée la page aspirée. exemple: wget -O ../pagesAspirees/1.html index.html # wget aspire le contenu du fichier index.html et le stocke dans le fichier 1.html contenu dans le dossier pagesAspirees lynx -dump : # l'outil lynx est un navigateur en ligne de commande. Beaucoup d'options sont également disponibles sur ce site # mais l'option qui nous interesse ici est -dump. Elle nous permet d'afficher le contenu d'un fichier. exemple: lynx -dump ../pagesAspirees/1.html > dump/fic.txt # la commande redirige le contenu textuel du fichier 1.html dans le fichier fic.txt mv : # cette commande permet de renommer des fichiers ou des répertoires. Tout dépend des arguments qui la suivent. exemple: mv resultat-extraction.html ../contexte/contxtA/resultat.html # Le fichier resultat-extraction.html est renommé ../contexte/contxtA/resultat.html. Pour plus d'informations, consulter le manuel (MAN) de la commande mv en français. cd : # cette commande permet de se déplacer dans l'arborescence de repertoires exemples: cd [projet_encadre] : on change de repertoire courant pour aller dans celui de projet_encadre cd . : on reste dans le repertoire courant cd .. : on remonte d'un cran dans l'arborescence c~ : on se place automatiquement dans le repertoire utilisateur pwd : # cette commande nous indique dans quel répertoire on se trouve |
haut de page
./Expressions régulières:
$ Les expressions régulières sont des expressions logiques qui permettent de définir un modèle de chaîne de caractères.Elles sont utilisées pour établir si une chaîne de caractères correspond ou non à un modèle donné.Nous les avons utilisées pour extraire le contexte des mots (voir 4ème étape).
$ Vous trouverez dans le tableau ci-dessous l'ensemble des expressions utilisées ainsi que leur signification.
\b délimite la frontière d'un mot | signifie "ou" ex: a|b chaîne qui contient "a" ou "b" [ ] permet de définir un ensemble de caractères.le signe - définit un intervalle. ex: [0-9] chaîne qui contient un chiffre allant de 0 à 9 + affiche une ou plusieurs fois ce qui précède. ex: linux+ chaîne qui contient la chaîne "linu" suivi d'un ou de plusieurs "x" . n'importe quel caractère alphanumérique ou d'espacement ex: .linux. chaîne "linux" précédée et suivie d'un caractère. * affiche 0 ou plusieurs fois ce qui précède ex: linux* chaîne contenant "linux" ou "linuxx" ou "linuxxx" etc... ( ) détermine un groupe de caractères ex: (un|le) site: chaîne qui contient "un site" ou "le site" |
Pour en savoir plus sur ces expressions utilisées en perl,cliquer ici
haut de page
Etapes pour l'écriture du script
./Arborescence de travail
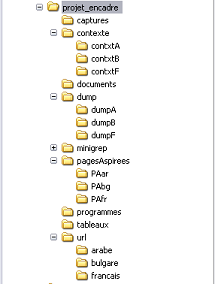
Après avoir fini la collecte des cinquante URLs pour les trois langues, tout était prêt pour commencer à faire nos traitements sur les pages WEB en question. Mais avant de commencer il a fallu fabriquer une arborescence des dossiers cohérente mais surtout pratique.
| $ Pour
pouvoir accéder plus facilement à nos dossiers
nous avons
décidé d'organiser les repertoires de la
manière
suivante: $ Dans chaque dossier de projet_encadre, des sous-dossiers ont été crées et ils correspondent chacun aux differentes langues choisies les repertoires: url: différentes pages web avec les sens du mot "raison" pages-Aspirées: pages aspirées en local à partir des sites Web dump: fichiers texte débalisés à partir des pages aspirées contexte: fichiers html dans lesquels figurent les contextes minigrep: contient le programme minigrep pour la recherche du contexte tableaux: les tableaux générés par le script |
|
haut de page
1ère étape
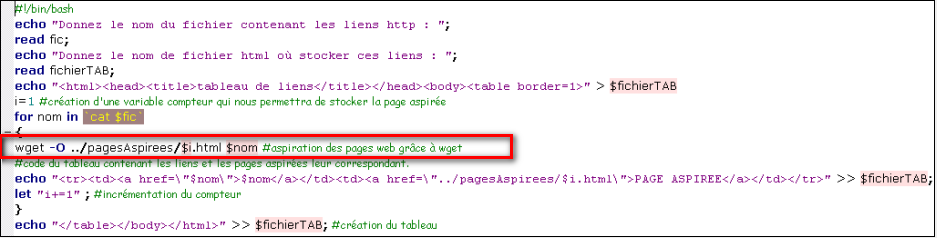
$ Création d'un tableau de liens:
L'idée est d'écrire un script qui lirait un fichier contenant une liste d'URL. Il produirait par la suite un fichier HTML avec les pages Web en question.
 |
| $ Pour
acceder au script, il faut avant tout bien se placer sous le bon
repertoire avec cd puis
lancer le lancer à partir de cygwin. $ L'intervention de l'utilisateur est requise à deux reprises: une fois pour indiquer le nom de fichier où se trouvent les URLs et une autre où on lui demande de donner un nom au fichier tableau généré.Voir echo et read |
|
|
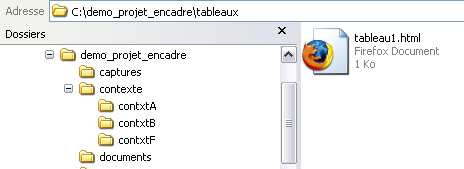
| $ Et voilà ce qu'on doit obtenir: un fichier HTML contenant les liens dans le repertoire tableaux. |
|

haut de page
2ème étape
$ Création d'un tableau avec les URLs et les pages aspirées localement
Dans le même script on intègre la commande wget pour l'aspiration des pages.
 |
| Voilà
ce qu'on obtient lors de l'execution du script: |
|
|
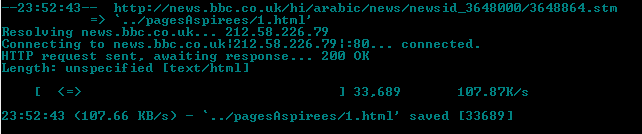
| et voici ce qui apparaît dans notre dossier pagesAspirées |
|
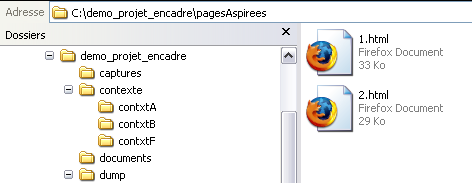
haut de page
3ème étape
$ Ajouter au tableau une autre colonne dans laquelle figurera les pages dumpées à partir des pages aspirées et ce avec la commande lynx -dump
 |
Problèmes pour les caractères cyrilliques et arabes:
Nous n'avons pas réussi à dumper les pages aspirées du bulgare et de l'arabe.Les fichiers texte obtenus étaient complètement illisibles.Rien ne pouvait nous indiquer si c'était de l'arabe, du cyrillique ou du japonais...Après avoir essayer de le faire sous un environnement UNIX et sous lequel nous n'avions pas non plus réussi, nous avons été contraintes de l'executer manuellement c'est-à-dire de selectionner le contenu des pages aspirées et de faire un copier-coller sous un éditeur de texte.Heureusement qu'il n'y avait qu'une cinquantaine d'URLs. Ce problème reste donc à resoudre.
haut de page
4ème étape
$ Extraction du contexte et ajout d'une quatrième colonne en intégrant des boucles for. (script détaillé ici)
 |
Comme vous pouvez le voir sur le script ci-dessus, au lieu d'intégrer la commande egrep pour extraire le contexte comme l'ont fait nombre de nos camarades, nous avons eu recours au programme minigrep multilingue. C'est un programme écrit en langage perl.Il supporte les caractères UNICODE et permet d'extraire aisement les motifs.Nous l'avons donc intégré dans notre script et ce pour chacune des trois langues. Le motif est stocké sous un fichier texte sous la forme: MOTIF=mot(s)
Comme avec egrep le ou les mots en question peut être précedés ou suivis d'expressions régulières pour obtenir une extraction du motif pertinente.
ici:
|
perl
./minigrep/mini-grep-multilingue.pl "UTF-8"
./dump/dumpB/$i.txt ./minigrep/motifb.txt #
on appelle mini-grep-multilingue.pl, on lui spécifie le
codage (ici UTF-8)
et on
lui indique où se trouve le fichier à traiter.A
partir du motif écrit
dans motifb.txt, il extraira le contexte.
|
Sous Cygwin:
Après avoir aspiré les pages web et débalisé leur contenu, le script appelle le programme mini-grep via la commande perl.
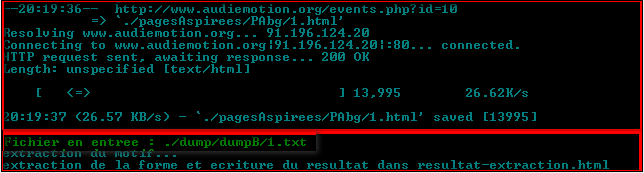 |
Comme on peut le voir ci-dessus, le programme prend en entrée le fichier ./dumpB/1.txt et procède à l'extraction du motif et de son contexte à partir de ce fichier.Pour savoir comment installer ce petit programme très intelligent,cliquer ici
haut de page