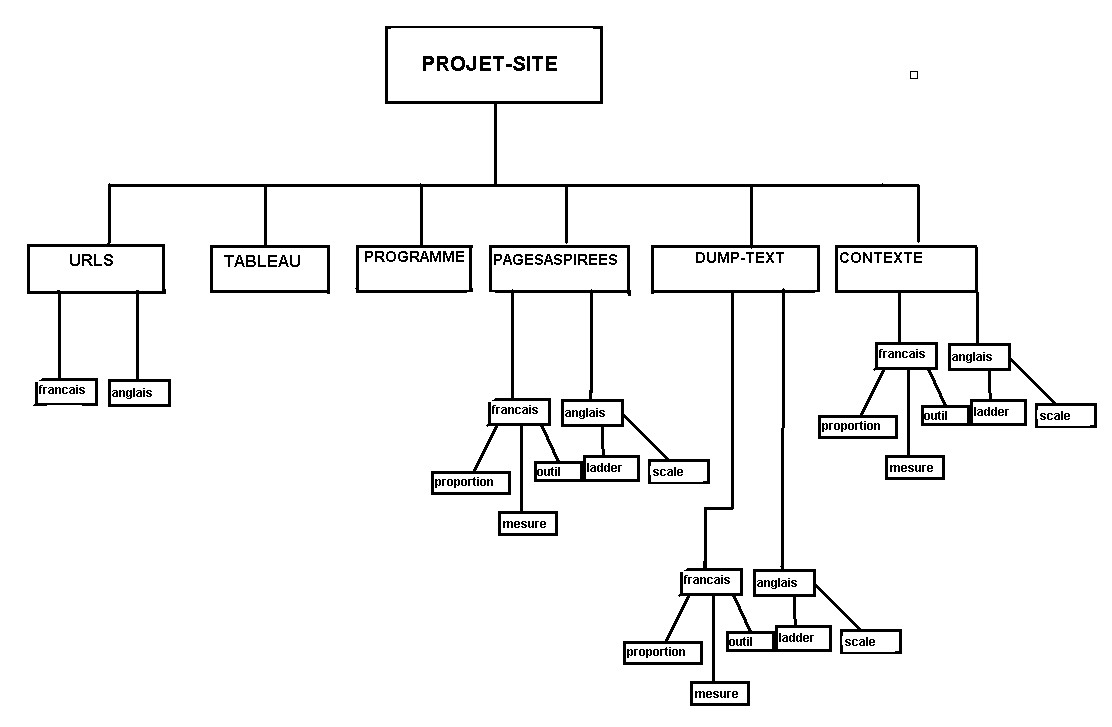
-Première étape: Choix des données à traiter et regroupement par sens
Tout d'abord nous avons repéré sur le net une
cinquantaine de pages contenant le mot échelle, en
français et en anglais.Nous avons ensuite dégagé
pour les deux langues les differents sens du mot. Processus nous
obligeant à créer une arborescence de dossiers
spécifiques à chaque sens, c'est à dire cinq sens
qui se déclinent en cinq dossiers, trois en français et
deux en anglais.
Français:Outil, mesure et proportion.
Anglais:Ladder et scale.
Voici l'arborescence des dossiers de notre projet.
-Deuxième étape : Problèmes rencontrés
Ces specificités dans les dossiers nous ont obligé
à prendre en compte dans chaque étape de l'ecriture de
notre script les différences de sens. Pour conserver un maximum
de lisibilité dans l'exploration des dossiers du projet, nous
avons décidé de divisé le travail en deux script,
un pour la langue française et l'autre pour l'anglais. En effet
les différentes commandes UNIX "wget", "lynx" et "egrep" nous
obligaient à définir les dossiers de destination pour
chaque sens. Or, placer dans un seul et même dossier les
résultats des commandes entrainait trop de confusion et ne
permettait pas de distinguer clairement les pages francaises des pages
anglaises.
Hélas, cette solution entraîne des complications lors de
l'utilisation du script sous cygwin, danslequel il faut préciser
pour chaque lancement le chemin du fichier URL, le sens, et le motif
recherché.
Exemple:


Cette méthode implique aussi l'utilisation de plusieur boucle.
En effet la composition du script nous a contraint à utiliser
une boucle par sens, il y a donc autant de boucle que de sens, c'est
à dire trois passages en français et deux passage en
anglais.
-Troisème étape: Outils de collecte et commandes utilisées
WGET: aspiration de pages web
La
collecte des données devait être faite par la
commande Wget utilisée sous l'environnement Cygwin.
Wget
permet l'aspiration de pages Web.
Lors
des premiers essais, nous avons rencontré certains
problèmes qui ont été
résolus grâce
à l'utilisation
d'options avec la commande Wget.
La commande Wget permet d'aspirer des pages Web
isolées dont
l'adresse est notée en argument. Comme nous avions
copié les URLs dans des fichiers texte et afin
d'automatiser les tâches, nous avons utilisé
l'option -O
pour rediriger le résultat vers un fichier que l'on nomme. C'est
entre autres lors de l'utilisation de cette commande qu'il était
imperatif d'avoir un script par langue:
-pour le français on trouve la ligne suivante: wget -O ./PAGESASPIREES/francais/$sens/$i.html $ligne
-pour l'anglais on trouve celle-ci: wget -O ./PAGESASPIREES/anglais/$sens/$i.html $ligne
Il y a donc deux dossiers bien distincts , évitant de
mélanger les page aspirées par langues mais aussi par
sens!!
LYNX: Formatage des données
L'aspiration du texte brut des pages web a été
effectué
à l'aide de la commande Lynx avec l'option -dump dans
l'environnement Cygwin.
Le script shell devait permettre de lire les pages html contenues dans
les différents dossiers du répertoire Wget et
d'enregistrer ces pages
"dumpées" dans un nouveau
répertoire - dump, organisé en
sous-répertoires reprenant le nom des dossiers
html d'origine.
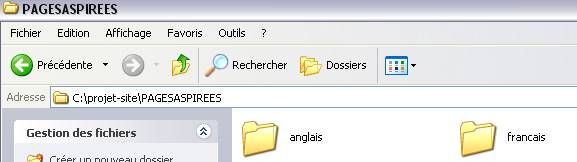
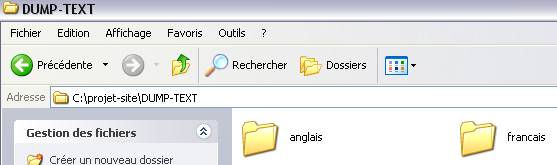
Nous avons bien les mêmes noms de sous-dossiers pour pour les pages aspirées et les pages "dumpées"!!
Nous avons aussi précisé dans le script les sens possibles afin de faciliter l'utilisation du programme:
En français: echo "Quel sens du mot: outil, mesure ou proportion? "
read sens
En anglais: echo "Quel sens du mot: ladder ou scale? "
read sens
EGREP: extraction des contextes
Afin d'illustrer les
différents usages du mot "échelle" dans chaque langue, nous
devions extraire des
contextes. Nous avons
utilisé la commande egrep (toujours sous Cygwin).
Egrep recherche le motif recherché "échelle" dans le
script français, "scale" et "ladder" dans le script anglais (en
minuscules et
au
singulier) .
L'option -i (que nous
avons
utilisée) permet de chercher le motif "barrage" en ignorant
la casse. Les résultats de
l'extraction sont redirigés vers un autre fichier : pour
cela il faut ajouter en fin de
ligne de commande le chevron fermant de redirection ">" suivi du
nom
du fichier qui
contiendra le résultat de l'extraction.
Pour le motif "échelle" : egrep -i "$motif" ./DUMP-TEXT/francais/$sens/$i.txt > ./CONTEXTE/francais/$sens/$i.txt
Pour le motif "ladder" et "scale": egrep -i "\b$motif\b" ./DUMP-TEXT/anglais/$sens/$i.txt > ./CONTEXTE/anglais/$sens/$i.txt
A noter que pour le français, l'accent aigu de "échelle"
posait problème lors de l'entrée des données, nous
avons abandonné, sous les conseils avisés de Mr Fleury,
la balise "\b" delimitant la taille du contexte.
Conclusion:
Nous
avons représenté les étapes de notre
travail (Url/Wget/Lynx/Egrep) dans un tableau récapitulatif qui
retrace les relations entre les tâches accomplies. (cliquez
sur
les liens ci-dessous pour les visualiser).