FILTRAGE
Les fils RSS
Un fil (feed) RSS est un fichier XML contenant les informations essentielles sur les changements du contenu d'un site Internet. Ce fichier est régulièrement mis à jour et publié sur le site en question pour offrir aux visiteurs une vue synthétique des informations qu'ils recherchent.
Dans notre cas, le fil RSS contient les titres et les résumés des articles publiés sur le site du journal Le Monde. Le début d'un fichier RSS avec une notice (item) ressemble à ceci :
<channel> <title>Le Monde.fr : A la Une</title> <link>http://www.lemonde.fr</link> <description>Toute l'actualité au moment de la connexion</description> <copyright>Copyright Le Monde.fr</copyright> <image> <url>http://medias.lemonde.fr/mmpub/img/lgo/lemondefr_rss.gif</url> <title>Le Monde.fr</title> <link>http://www.lemonde.fr</link> </image> <pubDate>Wed, 06 Dec 2006 17:58:09 GMT</pubDate> <item> <title> George W. Bush promet d'étudier "très sérieusement" le rapport Baker sur l'Irak </title> <link> http://www.lemonde.fr/web/article/0,1-0@2-3218,36-842716,0.html?xtor=RSS-3208 </link> <description> Le rapport sur un éventuel changement de stratégie en Irak préconise un dialogue avec l'Iran et la Syrie, une relance du processus de paix israélo-arabe, et une pression accrue sur le gouvernement irakien pour plus de sécurité. </description> <pubDate>Wed, 06 Dec 2006 17:27:51 GMT</pubDate> <guid isPermaLink="false"> http://www.lemonde.fr/web/article/0,1-0@2-3218,36-842716,0.html?xtor=RSS-3208 </guid> <enclosure url="http://medias.lemonde.fr/mmpub/edt/ill/2006/12/06/ h_1_ill_842748_baker.jpg" type="image/jpeg" length="2252"> </enclosure> </item>
Ainsi, ce qui nous intéresse est le contenu des éléments <title> et <description> (en gras dans l'exemple) qui sont enfants de l'élément <item>, lui même étant directement enfant de la racine du document <channel>.
Notez bien que les éléments de même nom figurent aussi dans l'entête du fichier. Nous ne voulons pas extraire leur contenu ce qui va demander un traitement spécifique dans la partie suivante.
remonter
Le script de filtrage
Le script perl filtreRSS.pl prend en argument le nom du répertoire qui contient l'arborescence des fichiers RSS. Il parcourt récursivement cette arborescence et lorsqu'il trouve des fichiers XML, il se met à la recherche des balises <title> et <description> et il les enregistre dans le fichier SORTIEfiltreRSS.xml.
Avant de recopier le contenu extrait dans notre fichier-sortie, il fallait faire une conversion des caractères qui étaient dans les documents originaux saisis sous la forme d'une entité HTML (commençant par &) lesquelles empêchent la bonne formation du document, lorsqu'elles ne sont pas déclarées comme une entité dans la DTD associée à ce document. Le même traitement nécessite toutes les occurrences du caractère &, donc même s'il ne joue pas le rôle de marqueur d'une entité.
Nous avons rajouté les lignes suivantes dans notre script pour faire des substitutions des entités par les caractères :
#pour les entités HTML $ligne=~s/'/\'/g; $ligne=~s/"/\"/g; $ligne=~s/é/é/g; $ligne=~s/ê/è/g; $ligne=~s/ê/ê/g; $ligne=~s/&nbsp//g; #pour le & tout seul $ligne=~s/&/and/g;
Les fins de ligne...
La nécessité de ne pas inclure dans notre fichier XML le contenu des éléments <title> et <description> fils de la racine <channel> demandait une modification du code fourni par les enseignants. Une solution un peu improvisée mais fonctionnelle était de rajouter des fins de lignes à l'expression qui sélectionne les balises avant de récupérer leur contenu :
if ($ligne=~/<title>([^<]+)<title>\n/||$ligne=~/<description>([^<]+)<description>\n/)
En fait, dans les fichiers avec lesquels nous avons travaillé, les caractères de contrôle marquants les fins de lignes étaient, pour des raisons inconnues, différents après les balises dans l'entête du fichier (fins de ligne Windows CRLF - 0D0A) et dans la suite du document (fins de ligne Unix LF - 0A). Nous pouvons bien voir ceci dans un éditeur de texte qui affiche les caractères de contrôle :

Et pour être sûr, le même endroit avec Hex Dump affichant les octets :
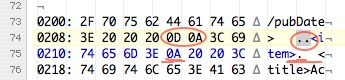
En exécutant le script (enregistré en ISO-Latin1 avec les fins de ligne Unix) dans un terminal UNIX de Mac OS X, ceci a suffit pour que seulement les balises désirées soient extraites.
remonter
Caractéristique du corpus
Notre corpus, stocké dans le fichier SORTIEfiltreRSS.xml, contient donc le contenu de 6114 éléments <title> ou <description> (ce qui fait 3057 dépêches), 112720 mots et 727510 caractères. Ces chiffres ont été obtenus à partir du fichier contenant uniquement le contenu textuel du notre corpus (voir ici) passé en argument à la commande Unix wc -lwc.