Secteur TAL Informatique,
Université Sorbonne nouvelle, Paris 3
19 rue des Bernardins, 75005 Paris


1. Les expressions régulières : introduction
1.1. Objectif
Définir des motifs pour reconnaître dans les textes des
chaînes de caractères ayant telle ou telle
propriété. Par exemple, on recherche tous les mots
terminés par le suffixe "able" ou commençant par le
préfixe "pré", toutes les phrases contenant le mot "enfant",
toutes les phrases commençant par "Je", se terminant par un point
d'interrogation, etc.
Un motif est un ensemble d'objets possèdant une propriété reconnaissable.
Reconnaissance de motifs : utilisation dans les éditeurs de texte pour permettre de rechercher des instances d'un mot particulier ou des ensembles de chaînes de caractères.
Exemple 1 : Correction dans un texte des occurrences du mot étiquettage par la forme correcte étiquetage.
Avec WORD : rechercher " étiquettage ", remplacer " étiquetage ".
Ce faisant on évite toutes les occurrences ou la forme graphique du mot est différente. On doit par exemple recommencer l'opération pour corriger les formes étiquetter, étiquettons...
Si on effectue le remplacement " tiquett " par " tiquet ", on aboutit à des erreurs : " étiquete ".
Pour faciliter ce type d'opération, on a recours à une description générique pour représenter la séquence de caractère erronée : on crée pour cela un motif de recherche du modèle erroné.
En Word, on peut réaliser ce type de recherche en utilisant une version brute d'un langage : les expressions régulières qui permettent de décrire des portions de texte à l'aide d'opérateurs.
Dans notre exemple, l'expression régulière [éE]tiquett(ons/er/ez/age) résume toutes les formes fautives.
Elle signifie :
Une chaîne de caractère qui commence soit par é E, contenant ensuite la séquence tiquett et se terminant par ons ou er ou ez ou age....
1.2. Exercices
TD " Word et les expressions régulières "
Manipulations des ER avec WORD : se reporter aux documents td1, td2,td3.
Critères de recherche élaborés
Vous pouvez affiner votre recherche en utilisant des opérateurs et des expressions dans la zone "Rechercher". Un opérateur est un symbole qui contrôle la recherche, et une expression est une combinaison de caractères et d'opérateurs spécifiant un modèle.Pour utiliser les opérateurs, vous devez activer la case à cocher "Critères spéciaux" dans la boîte de dialogue Rechercher ou Remplacer (menu Edition). Pour insérer un opérateur, choisissez "Spécial", puis sélectionnez l'opérateur voulu dans la liste, ou tapez-le directement dans la zone "Rechercher".Word vous permet d'utiliser des critères de recherche élaborés dans la zone "Rechercher" de la boîte de dialogue Rechercher ou Remplacer (menu Edition), ainsi que dans la zone "Contenant le texte" de l'onglet Résumé (boîte de dialogue Recherche approfondie, (commande Fichier Chercher). Voir Boîte de dialogue Recherche approfondie.
Pour rechercher Opérateur Exemples
N'importe quel caractère ? sa?le recherche "sable","saule" et
unique "salle".
N'importe quelle chaîne * a*r recherche, entre autres,
de caractères "affiner", "accoudoir" et "autour".
Un des caractères [ ] s[ea]c recherche "sec" et "sac".
spécifiés
N'importe quel caractère [-] tou[r-t] recherche "tour", "tous"
unique dans cette et "tout". Les sélections doivent
sélection être en ordre croissant.
N'importe quel caractère [!] [!j]oie recherche "voie" et
unique sauf les "soie", mais pas "joie".[!dm]alle
caractères à l'intérieur recherche "balle" et "salle", mais
des crochets pas "dalle" ou "malle".
N'importe quel caractère [!x-z] pa[!j-t]e recherche "page" et
unique, sauf les "paie", mais pas "pale" ou "pape".
caractères à l'intérieur
des crochets
Exactement n occurrences {n} car{2} recherche, entre autres,
du caractère précédent "carré" et "carrousel", mais pas
ou de l'expression "carotte".
précédente
Au moins n occurrences {n;}(si ";" est can{1;}e recherche "cane" et
du caractère précédent votre séparateur de "canne".
ou de l'expression liste par défaut)
précédente
De n à m occurrences {n;m}(si ";" est 10{1;3} recherche "10", "100" et
du caractère précédent votre séparateur de "1000".
ou de l'expression liste par défaut)
précédente
1 ou plusieurs @ cal@e recherche "calle" et "cale".
occurrences du caractère
précédent ou de
l'expression précédente
Le début d'un mot < <(inter) recherche, entre autres,
"intercepter" et "interdit", mais
pas "éreinter".
La fin d'un mot > (in)> recherche, entre autres,
"parrain" et "loin", mais pas
"inverti".
Pour utiliser l'un des opérateurs comme simple caractère, faites-le précéder du signe barre oblique inverse (\) dans la zone "Rechercher" ou "Remplacer par". Par exemple, pour chercher un point d'interrogation, tapez \? dans la zone "Rechercher". Un autre opérateur que vous pouvez utiliser dans la zone "Remplacer par" est l'opérateur \num. Ce dernier réorganise les expressions de la zone "Rechercher" dans l'ordre que vous avez indiqué dans la zone "Remplacer par". Si vous avez tapé (Christiane) (Berger) dans la zone "Rechercher", puis que vous tapez \2 \1 dans la zone "Remplacer par", le texte "Christiane Berger" est remplacé par "Berger Christiane".
Voir aussi : Recherche et remplacement, Recherche et gestion de documents
2. Les expressions régulières
2.1. Outils de base GREP, EGREP
Les premiers utilitaires utilisés sont issus du monde
UNIX. Ces utilitaires permettent de rechercher dans des fichiers des lignes
contenant un motif donné. Leur utilisation implique que l'on maîtrise les expressions
régulières.
2.1.0. Concaténation
* (pas de symbole) l'expression ab désigne la séquence composée des caractères a et b.
2.1.1. Classes de caractères
* . (joker) le point désigne tout caractère autre que le passage à la ligne
* [ ] (ensemble de caractère)
1. Encadrer une liste de caractères quelconques entre crochets, pour signifier que l'expression régulière représente leur union. Ex : [aghinostw] indique l'ensemble des lettres apparaissant dans le mot washington et [aghinostw]* indique l'ensemble des chaînes composées uniquement de ces lettres
2. (-) Placé dans un ensemble entre crochets, mais pas en 1ère position, un tiret sert à définir un intervalle commençant par le caractère qui le précède et se terminant par le caractère qui le suit. Par exemple, [a-z0-9] désigne un caractère qui peut Ítre a, b, c, ..., y , z ou 0, 1, 2, ..., 8, 9.
Attention : [-+*/] désigne l'ensemble des 4 opérateurs arithmétiques mais pas [+-*/]
3. (^) Placé après le crochet de l'exemple précédent, (^) indique que le caractère désigné est un caractère quelconque sauf ceux de l'ensemble.
Exemple : [^aeiou] désigne un caractère qui n'est pas une voyelle minuscule
2.1.2. Positionnement dans la ligne
* Début et fin de ligne : Symboles spéciaux pour le début (^) et la fin ($) d'une ligne
Par exemple, end$ désigne le mot end en fin de ligne alors que $end désigne le mot $end.
2.1.3. Dénombrement
* (fermeture : 0 ou n), l'étoile désigne un nombre quelconque d'occurrences du motif qui le précède
2.1.4. Déspécialisation
anti-slash utilisé comme barre d'échappement :
\$ désigne le caractère $,
\\ désigne le caractère \
2.1.5. Combinaison de motifs
Opérateurs supplémentaires
Dans egrep :
| (disjonction) L'opérateur de disjonction permet de décrire simultanément des segments de texte décrits par l'un ou l'autre des motifs
Exemple : L|l
? (optionnalité) Le point d'interrogation sert à marquer l'optionnalité de l'expression qui le précède.
+ (1 ou n) Cet opérateur permet de désigner un nombre non nul d'occurrences
Exemple : [0-9]+ et [0-9][0-9]* désignent la même chose !
() parenthésage
Les parenthèses permettent d'indiquer comment les éléments de l'expression doivent être groupés. Les opérateurs s'organisent selon des niveaux de priorité :
fermeture > concaténation > union
Ex : a|bc*d
1. On commence par s'intéresser aux signes *.
2. On les regroupe avec leur opérande : a|b(c*)d
3. Ensuite on s'intéresse aux concaténations.
4. 1ère concaténation : a|(b(c*))d
5. 2ème concaténation : a|((b(c*))d).
Enfin, on regarde les unions : (a|((b(c*))d)) mais les () extérieures sont redondantes
2.1.6. Exemples
* motif désignant un ligne vide
^$
* recherche du mot end dans un texte
end capte tous les mots comprenant la séquence end (tendrement, entend)
_end_ ne capte pas le mot end en début de ligne, ni par exemple end suivi d'une virgule.
[^a-z]end[^a-z] isole bien le mot end, mais pas s'il est en début ou fin de ligne. On a donc besoin de trois motifs :
^end[^a-z]
[^a-z]end[^a-z]
end[^a-z]$
2.1.7. Les commandes grep et egrep
Le format de commande est :
grep motif fichier
egrep motif fichier
La sortie du processus est redirigée vers un fichier :
egrep motif fichiersource > fichiercible
Les commandes grep et egrep comportent des options qui permettent de modifier leurs comportements :
- -c : affiche un décompte des lignes comprenant le motif.
- -v : affiche les lignes ne contenant pas le motif.
- -n : chaque ligne contenant le motif est précédée du nuémro de ligne
Format d'utilisation des commandes avec options :
grep [option] motif fichiersource [> fichiercible ]
egrep [option] motif fichiersource [> fichiercible ]
2.1.8. Exercices avec grep/egrep
Se reporter au document : td4 avec grep et egrep.
Expressions régulières : aide-mémoire
OP...RATEUR FONCTION EXEMPLE
. joker 80.86 suites 80186, 80a86, etc.
* 0 ou n fois (.*) n caractères à
l'intérieur de parenthèses
+ 1 ou n fois -+ suite non nulle de tirets
[] classe de caractères [-=:] soit -, soit =, soit :
[^] complémentaire [^ ]+ suite de caractères
à l'exclusion du
blanc
^ début de ligne ^[^ ]+ suite de caractères
à l'exclusion du
blanc en début de ligne
$ fin de ligne ^$ ligne vide
| ou chapitre|sec
tion
\ sens littéral d'un \. le point
caractère spécial
() groupement 19(89|90)
d'expressions
\{n,m\} entre n et m \*\{4,10\} entre 4 et 10 étoiles
occurrences
? zéro ou une
occurrence
2.2. Le langage des expressions régulières
2.2.1. Rappel sur les ensembles
* Ensemble, élément
Un ensemble est une collection d'objets distincts (concrets ou abstraits).
Exemple : A = {a,b,c}.L'ensemble A est constitué des objets a, b et c. Ces derniers sont aussi appelés des éléments de a. On dit que ces éléments appartiennent à A.
Notation :
a Î A, b Î A, c Î A, d Ï A
* Ensemble vide
L'ensemble vide s'écrit ø.
* Sous-ensemble
Un ensemble A est sous-ensemble d'un ensemble B lorsque tous les éléments de A sont aussi éléments de B. Formellement, on écrit :
B Ì A <=> " x Î A, x Î B
" : quantificateur universel qui se lit " pour tout ", i.e. "] x se lit " pour tout x ".
<=> : opérateur d'équivalence qui se lit " si et seulement si ".$ : quantificateur existenciel qui se lit " il existe au moins un ", i.e. $ x se lit " il existe au moins un x ".
* Réunion
La réunion de deux ensembles A et B est un ensemble qui contient tous les éléments qui appartiennent à A ou à B ou aux deux, sans répétition.
union(A,B) = {x / x Î A ou x Î B}
* Intersection
L'intersection de deux ensembles A et B est un ensemble qui contient tous les éléments qui appartiennent à A et à B.
intersection(A,B) = {x / x Î A et x Î B}
* Composition par concaténation (produit)
On définit le produit par concaténation d'éléments de deux ensembles A et B comme l'ensemble de toutes les chaînes composées d'un élément de A et d'un élément de B.
A.B = AB = {xy / x Î A, y Î B}
On peut étendre cette notion de produit à celle d'élévation à la puissance :
A.A = A2 = {xy / x Î A, x Î A}
Exemple :
A = {a,b,c}, B={s,u}
AB = {as,au,bs,bu,cs,cu}
AA = A2 = {aa,ab,ac,bb,ba,bc,cc,ca,cb}
Par convention:
A1 = A et A0 = { l }, où l désigne l'élément neutre dans l'opération de concaténation : i.e. a. l = a.
* Extension d'un ensemble
On appelle extension d'un ensemble la réunion de toutes les puissances entières (non négatives) de cet ensemble.
Exemple : A = {a,b,c}, a Î A*, baba Î A*.
2.2.2. Notion de langage
Un langage formel est un ensemble de chaînes construites sur un
vocabulaire donné.
* Vocabulaire
Un vocabulaire est un ensemble fini de symboles
V={a, b, c...z}
* Chaîne
Une chaîne sur un vocabulaire V est un concaténation de symboles
x = ab
* Concaténation de chaîne
La concaténation de deux chaînes a pour résultat une chaîne obtenue en juxtaposant ces deux chaînes.
avec x = ab y=cd
on obtient xy = abcd
* Langage
Rappel : V* est l'ensemble de toutes les chaînes sur le vocabulaire V.
Par définition un langage est un sous-ensemble de V*.
* réunion
Si L est la réunion des langages L1 et L2, il est composé des chaînes appartenant à L1 ou à L2 ou aux deux.
Exemple :
Si V = {a,b} et L1 = {a,b,ab,ba,aa,bb}, L2 = {ab,aab,aabb,abb}
union(L1,L2) = {x / x Î L1 ou x Î L2} = { a,b,ab,ba,aa,bb,aab,aabb,abb}
* intersection
Si L est la réunion des langages L1 et L2, il est composé des chaînes appartenant à L1 et à L2.
Exemple :
Si V = {a,b} et L1 = {a,b,ab,ba,aa,bb}, L2 = {ab,aab,aabb,abb}
intersection(L1,L2) = {x / x Î L1 et x Î L2} = { ab}
Il est important de se rappeler que les langages sont des ensembles construits sur des vocabulaires donnés, il faut donc toujours spécifier le vocabulaire associé à un langage.
* produit
Le produit par concaténation de deux langages L1 et L2 contient toutes les chaînes formées par la concaténation d'une chaîne de L1 avec une chaîne de L2.
L1.L2 = {xy / x Î L1, x Î L2}
Exemple :
V = {a,b,...z}
L1 = {mo,po,ri,ru}
L2 = {t,che}
L1.L2 = {mot,moche,pot,poche,rit,riche,rut,ruche}
* extension
L'extension d'un langage est la réunion de tous les langages obtenus en élevant le langage à toutes les puissances entières (non négatives).
Exemple : si L = {a,b,....z}, L* est l'ensemble de toutes les chaînes de longueur quelconque formées des lettres de L.
Exercices sur les langages : TP GF
2.2.2. Les expressions régulières
On dispose d'un langage pour définir lLes expressions régulières. La valeur de chaque expression est un motif constitué d'ensemble de chaînes, souvent appelé un langage. On appellera L(E) le langage défini par une expression régulière E.
Dans l'algèbre des expressions régulières on trouve les opérandes atomiques et les langages correspondants suivants :
1. un caractère quelconque x. Le langage L(x) = {x} est un ensemble contenant une chaîne unique composée du seul caractère x.
2. le symbole l qui représente la chaîne vide. L(l) = { l } est le langage dont l'unique élément est la chaîne vide.
3. le symbole ø représente l'ensemble de chaînes vide. L(ø) = ø .
Trois opérateurs permettent de combiner les expressions régulières
* Union (notée | )
L(R|S) = L(R) union L(S), L(R) et L(S) étant des ensembles de chaînes
* Concaténation (pas de symbole)
L(RS) est construit à partir de L(R) et L(S) : pour chaque chaîne r de L(R) et chaque chaîne s de L(S), la chaîne rs, issue de la concaténation de r et de s, est une chaîne de L(RS).
* Extension/Fermeture (postfixe et unaire, noté *)
R* : fermeture de l'ER R : zéro occurrence ou plus des chaînes de R
Si R = a, L(R*) = {l, a, aa, aaa, aaaa, aaaaa, ...}
Si R = a|b, L(R*) contient toutes les chaînes de a et de b de longueur quelconque
priorités : fermeture > concaténation > union
Ex : a|bc*d
1. On commence par s'intéresser aux signes *.
2. On les regroupe avec leur opérande : a|b(c*)d
3. Ensuite on s'intéresse aux concaténations.
4. Premiére concaténation : a|(b(c*))d
5. Deuxiéme concaténation : a|((b(c*))d).
Enfin, on considére les unions : (a|((b(c*))d)) mais les parenthéses extérieures sont redondantes
2.3. Notions de grammaire formelle
2.3.1 Introduction
La théorie des grammaires formelles qui remonte à la fin des années cinquante est
due à Chomsky . Les grammaires formelles peuvent être définies comme des ensembles
de règles parfaitement explicites, applicables de façon mécanique, qui transforment
une entrée en une sortie particulière. L'entrée correspond au symbole initial
et la sortie à une chaîne de caractères.
L'intérêt de cette formalisation pour le TAL est surtout d'avoir permis
établir et de prévoir la complexité informatique qu'engendre l'utilisation de ces grammaires dans des applications de traitement automatique.
Un langage est un ensemble de chaînes construites sur un vocabulaire donné.
Exemple : un langage naturel est un sous-ensemble de l'extension d'un certain vocabulaire.
Une grammaire doit donc au moins servir à définir quelles sont les chaînes qui appartiennent à un langage.
Sur le plan formel, une grammaire est un système constitué d'un nombre fini de composants et destiné à la description d'un langage.
* Système de production
Un système de productions est un couple (V, P) où V est un vocabulaire fini de symboles et P est un ensemble finis de productions.
Les productions ont la forme x -> w où x et w sont des chaînes sur V (mais x ne peut être vide), c'est-à-dire x Î V+ et w Î V*.
Pour définir un système de productions. Il suffit de définir ses deux composantes V et P. Ainsi:
V = {a. b, c} et P = [ba --> ab, ca --> ac, cb --> bc]
constituent un système de productions.
* Dérivation
Un système de productions permet de réécrire des chaînes à partir d'autres chaînes en appliquant des productions.
* Dérivation directe (-->)
On dit que y-->z si et seulement si il existe u, v Î V*, tel que y = uxu, z = uwu et x --> w est une production de P.
Dans le système donné précedemment bbbaaa --> bbabaa est une dérivation directe car on a :
u = bb, v = aa. x = ba et w = .ab
aba --> aab est aussi une dérivation directe (ici v = l).
* Dérivation ( => )
On dit que y => z si et seulement si il existe une suite de chaînes XO, X1 X2, ... Xr (r >= 0), telle que:
y = Xo
z = Xr
Xi --> X(i+l) pour i = 0.1.2..r-1
Dire que z dérive de y signifie donc que, partant de y, on peut aboutir à z par un certain nombre de dérivations directes successives. On dit que r est la longueur de la dérivation.
2.3.2 Définition d'une grammaire formelle
Une grammaire formelle est un quadruplet
G = {Vn, Vt, P, S}
où Vt est un vocabulaire terminal fini. C'est sur ce vocabulaire que sont formées les chaînes (phrases) du langage que la grammaire définie. Ces chaînes appartiennent donc à Vt*.
Vn est un vocabulaire non terminal fini. C'est un vocabulaire auxiliaire utilisé dans les règles de grammaire. Le plus souvent Vn contient les éléments du métalangage utilisé pour dénommer les constituants:
Vn et Vt n'ont aucun élément en commun ; le vocabulaire V de la grammaire est la réunion de Vt et Vn.
Le couple (V. P) est un système de productions. P est un ensemble de productions, appelées dorénavant règles de la grammaire de la forme : x A y --> z où A appartient à Vn et x, y, z appartiennent à V*.
Les deux membres d'une règle sont appelés " partie gauche " et " partie droite " : la partie gauche contient toujours au moins un élément de Vn ; si l'on considère chaque règle x --> y comme un couple (x, y), on peut alors dire que P est un sous-ensemble du produit cartésien V+ x V*.
S est un élément particulier de Vn appelé le symbole initial ou axiome de la grammaire. Une grammaire n'a toujours qu'un seul symbole initial.
Le langage défini par une grammaére G s'écrit L(G). Une phrase de L(G)est toute chaîne x de Vt*, telle que S => x. Le langage défini par une grammaire G est:
L(G) = { x / x appartient à Vt* et S => x}
Exemple : Soit la grammaire G:
Vn = {S, GN, GV. D. N. V}
V, = {le, chat, poisson, mange, dévore}. P est l'ensemble de règles:(I) S-->GN GV
(2) GV-->V GN
(3) GN-->D N
(4) D-->le
(5) N-->chat
(6) N-->poisson
(7) V-->mange
(8) V-->dévore
Cette grammaire reconnaît la phrase : le chat dévore le poisson. Voici la dérivation de cette phrase. Pour chaque dérivation on a indiqué le numéro de la règle appliquée :
(I) GN GV
(3) D N GV
(4) le N GV
(5) le chat GV
(2) le chat V GN
(8) le chat dévore GN
(3) le chat dévore D N
(4) le chat dévore le N
(6) le chat dévore le poisson
2.3.2 La hiérarchie des grammaires formelles
Ces grammaires n'imposent aucune restriction sur les règles de production, qui peuvent être composées à droite et à gauche d'un nombre indéterminé de symboles terminaux et non terminaux.
exemple : G = ({P}, {a,b,c},R,P) où R = {Pab -> ab,P -> c}
Ces grammaires imposent une restriction sur la taille des règles: le côté droit de la règle ne peut pas avoir moins de symboles que le côté gauche.
exemple : G = ({P}, {a,b,c},R,P) où R = {aPb -> acb}
Avec ce type de grammaire, chaque production doit avoir exactement un symbole non terminal à gauche et une chaine non nulle à droite.
Avec ce type de grammaire, chaque production doit avoir exactement un symbole non terminal à gauche et à droite, soit un symbole terminal unique, soit un symbole terminal suivi d'un non termninal (grammaire régulière à droite) ou l'inverse (grammaire régulière à gauche), mais les deux dernières configurations ne sont pas possibles dans la même gramrnaire.
exemple : G = ({P}, {a,b},R,P) où R = {P -> aP, P -> b}
Les grammaires les plus utilisées pour le traitement de la langue naturelle sont les grammaires de type 2 (ou grammaires indépendantes du contexte). Les autres types de grammaires semblent en effet inaptes au traitement automatique des langues naturelles. Les grammaires de type 2 présentent à la fois les restrictions et la richesse qui conviennent à la description de la langue naturelle. Ces grammaires permettent non seulement de reconnaître les phrases correctes mais aussi de leur assigner une représentation en arbre.
2.4. Expressions régulières et automates
2.4.1. Les automates
On peut se représenter le comportement d'un programme destiné à reconnaître un motif particulier comme un cheminement dans un graphe orienté. Les nœuds constituent les états du programme. Les arcs sont étiquetés par des ensembles de caractères. Il existe un arc de l'état s vers l'état t étiqueté par l'ensemble de caractères C si, quand on se trouve dans l'état s, on passe à l'état t uniquement après avoir rencontré un des caractères de l'ensemble C. On dit que l'on effectue une transition de l'état s vers l'état t sur le symbole x qui appartient à l'ensemble C. Les arcs sont pour cette raison appelés transitions. Un nœud est appelé état de départ: c'est celui par lequel commence la recherche du motif. D'autres nœuds sont appelés états d'acceptation: lorsqu'on atteint un de ces nœuds, c'est que le motif a été intégralement reconnu (on dit accepté).
Un tel graphe porte le nom d'automate fini. Un tel automate reçoit une suite de caractères appelée séquence d 'entrée. Il est alors dans l'état de départ, prêt à lire le premier caractère de la séquence d'entrée. Si ce caractère correspond à une transition possible (éventuellement vers le même état), il effectue cette transition et examine le caractère suivant de la séquence d'entrée. Et ainsi de suite. Si l'automate a examiné tous les caractères de la séquence d'entrée et se trouve sur un état d'acceptation, on dit que cet automate accepte ou reconnaît la séquence d'entrée. Si, par contre, l'automate se trouve dans un état où il n'existe aucune transition pour le caractère examiné ou si l'automate se trouve dans un état d'acceptation alors qu'il reste des caractères à examiner, on dit que l'automate rejette la séquence d'entrée. Un automate reconnaît donc une séquence d'entrée s'il existe un chemin de l'état de départ à un état d'acceptation. Ce chemin doit être constitué d'arcs dont les étiquettes contiennent les symboles de la séquence d'entrée dans le bon ordre.
Par convention, les états d'acceptation sont figurés par des doubles cercles. Une flèche arrivant de nulle part signale l'état de départ. Dans le cas où l'ensemble C qui étiquette une transition est réduit à un singleton, c'est-à-dire qu'il ne comporte qu'un seul symbole, on utilise ce symbole comme étiquette, par exemple x et non le singleton {x}. La lettre grecque lambda (L) représente l'ensemble des caractères. L'expression {L - x} recouvre l'ensemble des caractères moins le caractère x. La figure suivante correspond ainsi au graphe de l'automate de reconnaissance du motif constitué par les séquences c'est à dire, c'est-à-dire, c'est-à dire, et c'est à-dire, précédées et suivies d'un nombre arbitraire de caractères quelconques.
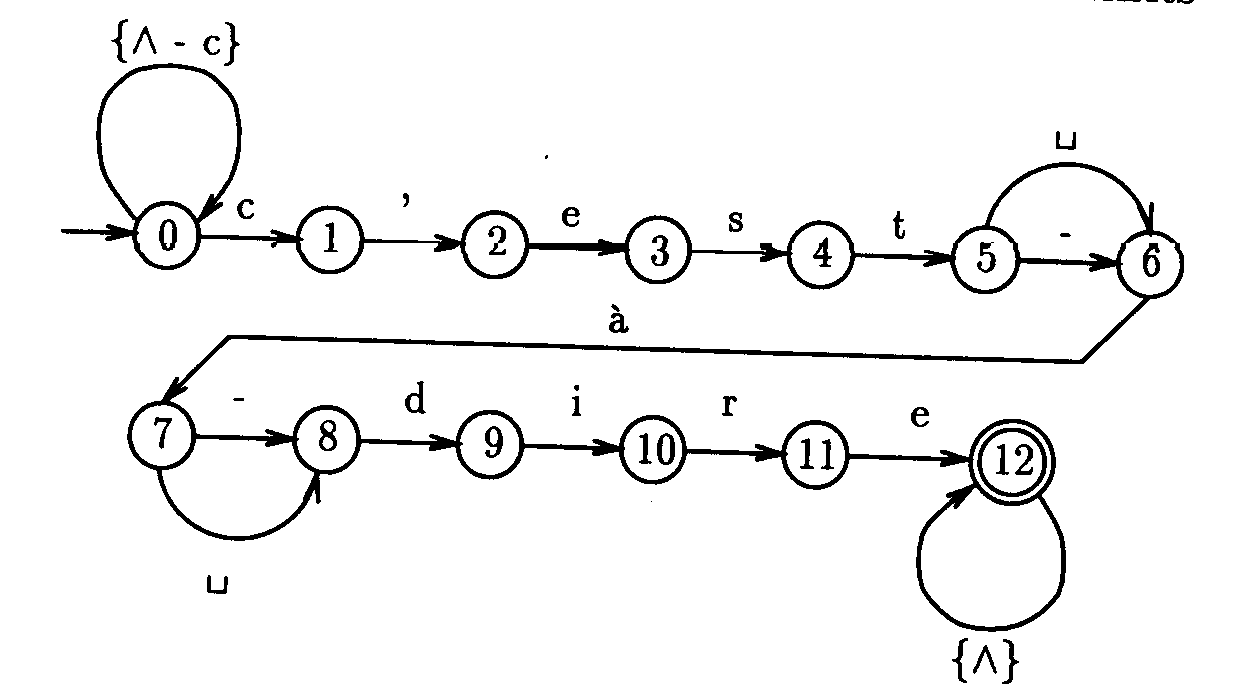
Notons que les automates comme celui-ci n'ont que deux résultats possibles: acceptation ou rejet. Néanmoins, les outils logiciels qui reposent sur de tels automates utilisent souvent de manière plus riche la décision d'acceptation ou de rejet. Pour egrep, par exemple, chaque ligne constitue à tour de rôle la séquence d'entrée et les issues possibles sont différentes: la ligne entière si elle comprend le motif cible, rien dans le cas contraire.
Automates déterministes et non déterministes
Dans l'automate de la figure précédente, dans un état s, pour tout caractère d'entrée s, il existe au plus une transition partant de l'état s et dont l'étiquette contient s. Un automate qui vérifie cette propriété est dit déterministe. Un automate est non-déterministe quand il comporte deux transitions au moins issues d'un même état et contenant le même symbole. Avec un automate non-déterministe, une séquence d'entrée peut correspondre à plusieurs chemins différents. Un automate non-déterministe accepte une séquence d'entrée si au moins un des chemins correspondants débute dans l'état initial et termine par l'état final, quel que soit le nombre des autres chemins débouchant sur un état de non- acceptation. Un automate non déterministe peut être un moyen élégant de pallier les failles de l'automate de la figure précédente. Ce dernier, en effet, va se bloquer s'il rencontre dans la séquence d'entrée une chaîne qui est un préfixe de c'est-à-dire.
Confronté par exemple à : c'est à Paul, c'est à dire que Luc passe son tour
cet automate va entamer la reconnaissance de c'est-à-dire, mais quand il sera arrivé dans l'état 8, après avoir examiné c'est à, il ne trouvera pas de transition pour le caractère courant P. La séquence sera donc rejetée, quand bien même elle comporte effectivement une occurrence de c'est-à-dire un peu plus loin. Une variante non déterministe de cet automate pourrait comporter à la place de la transition de l'état 0 sur l'état 0 sur {L - c} une transition sur L. Le résultat de cette transformation est le suivant. Dans l'état 0, si l'on rencontre le caractère c, deux hypothèses sont explorées simultanément: il s'agit du début de c'est-à-dire (on passe dans ce cas à l'état 1), cette hypothèse débouche sur un échec à la rencontre de P, ou il ne s'agit pas du début de c'est-à-dire (on reste dans l'état 0). Quand est rencontré le deuxième c, on poursuit l'hypothèse demeurant en lice (en restant dans l'état 0) et on essaie une nouvelle hypothèse, celle que la séquence cherchée commence à cet endroit (en passant à l'état 1). Sur les trois hypothèses examinées, une seule, la troisième, conduit à un état d'acceptation.
Il est aisé de transformer un automate déterministe en un programme. A chaque état correspond un fragment de programme qui examine le caractère d'entrée et qui choisit, si elle existe, la transition à suivre à partir de cet état et de ce caractère, en effectuant un saut au fragment de programme représentant l'état d'arrivée de la transition et en passant au caractère suivant de la séquence d'entrée. Le programme débute dans le fragment de programme correspondant à l'état de départ. Si, pour un état et un caractère donné, il ne comprend aucune transition, il retourne un diagnostic de rejet. S'il aboutit au fragment de programme correspondant à un état d'acceptation et qu'il ne reste plus de caractères à examiner, il indique que la séquence est acceptée.
Un automate non déterministe n'est pas directement transposable en un programme, puisqu'en un état donné, face à un caractère, plusieurs hypothèses peuvent être suivies. Cependant, on prouve que tout automate non-déterministe peut être converti en un automate déterministe qui accepte le même ensemble de chaînes de caractères.
2.4.2. Des automates aux expressions régulières
Le motif sous-jacent à un automate est l'ensemble des chaînes de caractères étiquetant les chemins menant de l'état initial à un état final. Dans le cas de l'automate précédent, I'ensemble est le suivant: {c'est à dire, c'est-à-dire, c'est-à dire, c'est à-dire}. Une autre manière, algébrique, de définir un motif est de recourir à des expressions regulières.
Il est possible de convertir une expression régulière en un automate non déterministe à partir duquel on peut obtenir un automate déterministe. Inversement, il est possible de convertir un automate quelconque en une expression régulière. Dans les deux sens, les transformations préservent l'ensemble de chaînes recouvertes. Plus généralement, l'ensemble des motifs définissables par des expressions régulières recouvre exactement celui qu'on peut décrire avec les automates.
Forces et limites des expressions régulières
Les expressions régulières sont souvent plus faciles à comprendre, à concevoir et à écrire que les automates correspondants. En outre, certaines équivalences permettent de simplifier des expressions régulières tout en continuant à décrire le même langage. Les automates équivalents, déterministes constituent les " machines " les plus efficaces que l'on peut réaliser pour reconnaître un motif. Les outils comme grep, awk et lex mettent à la disposition des utilisateurs la puissance des automates tout en permettant de spécifier par des expressions régulières les motifs à utiliser.
Cependant, les expressions régulières et les automates déterministes ne peuvent pas décrire tous les langages. On ne peut pas spécifier par ces moyens un motif dans lequel on dirait qu'une sous-partie apparaît autant de fois (ce nombre de fois étant non spécifié) qu'une autre sous-partie. Par exemple, on ne peut pas utiliser un automate fini pour vérifier qu'il y a autant de balises d'un certain type que de balises d'un autre type d'élément, comme <s> et <u>. On peut indiquer seulement un nombre quelconque de balises: (<s> ou </u>)*, ou un nombre prédéfini : (<s><s><s></u></u></u>). Les langages correspondants ne peuvent donc pas comprendre des relations d'enchâssement de profondeur arbitraire. Il faudra recourir aux langages hors contexte pour rendre compte de telles relations.
