PARTIE 3 (egrep)
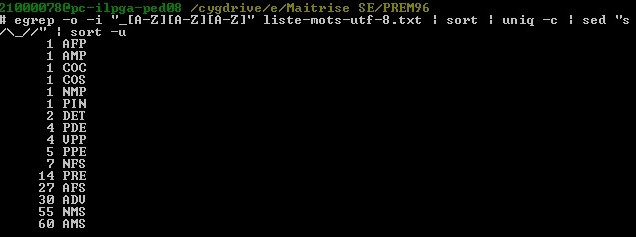
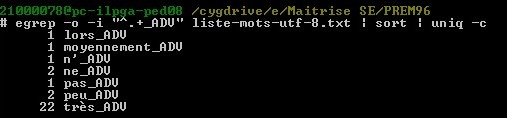
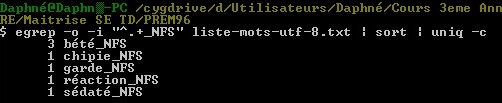
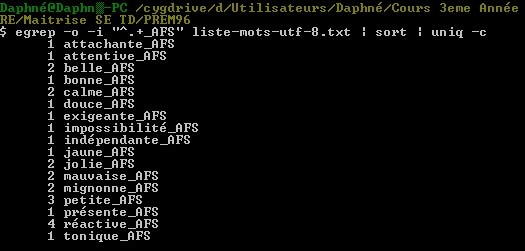
Utilisation TextUtils Niveau 0 Tťlťcharger les textes de travail Textes de travail†: index des mots du corpus prťmaturťs. On trouvera dans l'archive prťcťdente un fichier regroupant l'ensemble des mots du corpus (un par ligne).











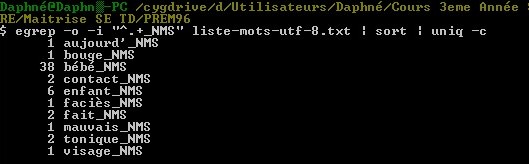
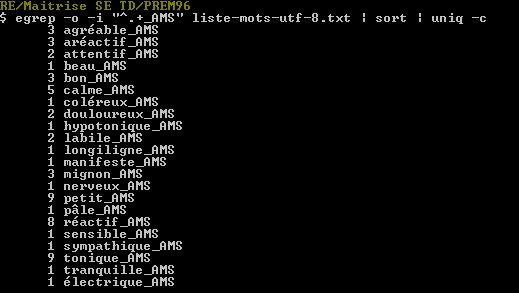
PARTIE 3 (egrep)
Utilisation TextUtils Niveau 0 Tťlťcharger les textes de travail Textes de travail†: index des mots du corpus prťmaturťs. On trouvera dans l'archive prťcťdente un fichier regroupant l'ensemble des mots du corpus (un par ligne).

