GASPAR, UN DISPOSITIF EXPERIMENTAL POUR LE TRAITEMENT AUTOMATIQUE DU LANGAGE NATUREL AVEC LA PROGRAMMATION A PROTOTYPES
REPRESENTATION ET CLASSIFICATION EVOLUTIVES DES CONNAISSANCES POUR LE LANGAGE NATUREL
Serge Fleury
ELI (Equipe Linguistique et Informatique)
Ecole Normale Supérieure de Fontenay-St Cloud
31 avenue Lombart
F-92260 Fontenay aux Roses
e-mail : fleury@ens-fcl.fr
http://www.ens-fcl.fr/~fleury/
Résumé.
Notre travail s'inscrit dans le cadre du Traitement Automatique du Langage Naturel (TALN). Notre démarche vise à la mise en oeuvre d'un dispositif informatique cohérent avec les problèmes posés par les phénomènes linguistiques traités par ce dispositif (en particulier la construction du sens). Nous présentons ici le dispositif GASPAR qui construit des représentations des mots sous la forme d'objets informatiques appelés des prototypes ; GASPAR associe à ces objets les comportements syntaxiques et sémantiques des mots en prenant appui sur des informations extraites à partir d'un corpus. GASPAR a pour première tâche de construire progressivement une représentation informatique des mots, sans présumer de leurs descriptions linguistiques ; il doit ensuite reclasser les mots représentés et mettre au jour, de manière inductive, les classes de mots du sous-langage étudié. Nous montrons comment la programmation à prototypes permet de représenter des mots dynamiquement par apprentissage et par affinements successifs. Elle permet ensuite d'amorcer un début de classement de ces mots sur la base de leurs contraintes syntaxico-sémantiques en construisant des hiérarchies locales de comportements partagés. Ce travail met aussi en avant la nécessité de disposer d'un méta-niveau d'analyse dans un dispositif de TALN pour évaluer ou contrôler les opérations réalisées par les processus mis en place dans ce dispositif. Ce méta-niveau d'analyse doit surtout permettre à l'utilisateur du dispositif d'interpréter les résultats construits par les processus de représentation et de classement mis en place.Mots clés : Linguistique basée sur corpus, langage à prototype, apprentissage et classement automatique, contrôle, méta-représentation, réflexivité
1. Introduction
Nous présentons ici la mise en œuvre d'un dispositif expérimental de Traitement Automatique du Langage Naturel qui porte le nom de GASPAR [FLE 97]. Ce dispositif vise à établir une représentation et un classement évolutifs de mots représentés sous la forme d'objets informatiques appelés des prototypes. Nous soulignons d'abord les problèmes posés par la représentation d'unité de langue dans un dispositif de TALN. Puis nous présentons le cadre de représentation choisi pour construire des représentations informatiques des mots et des comportements associés. Nous décrivons également les processus mis en place pour une représentation et un classement automatiques des mots avec GASPAR. Nous introduisons enfin la nécessité de disposer d'un méta-regard sur les informations manipulées par le dispositif pour évaluer et contrôler les différentes opérations réalisées par le dispositif sur les informations traitées.
2. Un dispositif de TALN pour représenter la mouvance
Le traitement automatique du langage naturel doit passer par une phase de représentation des éléments linguistiques contrainte à figer les connaissances à modéliser. Or un examen des comportements des mots révèle des variations qu'il semble difficile de fixer dans des structures de représentations statiques. La langue évolue en permanence et les résultats acquis par la description linguistique sont toujours remis en question par la prise en compte de nouvelles informations. Il en va de même pour les comportements lexicaux : les savoirs associés aux mots ne sont pas donnés une fois pour toute. Ces derniers peuvent bouger et remettre en cause des représentations construites à un moment donné. Puisqu'il n'est pas satisfaisant de se contenter d'un modèle apriorique pour construire une représentation des comportements des unités lexicales, notre travail de représentation s'inscrit dans une approche expérimentale qui ne présume pas complètement des choses à représenter. L'hypothèse suivie dans ce travail pour la représentation des informations linguistiques consiste à ne pas prédéterminer de manière figée ni les structures définies pour cette représentation ni leurs classements. Nous convenons avec [HAT 91] que "la construction d'une hiérarchie est un processus incrémental" et qu'une hiérarchie "évolue et s'améliore en fonction des résultats obtenus jusqu'à ce qu'une certaine forme de stabilité soit atteinte". Notre démarche met en place un processus de représentation évolutif : les structures de représentation construites devront pouvoir être affinées dès que de nouveaux savoirs seront mis à jour. On peut en effet considérer que les comportements des mots ne sont pas tous prédéfinis mais que ceux-ci "émergent" dans le contexte dans lequel ces mots "agissent". Il n'est donc pas raisonnable de les considérer comme acquis par définition. Il s'agit au contraire de les mettre en lumière ainsi que les corrélations multiples qui existent entre les mots dans un flot continu de discours. Notre démarche consiste en quelque sorte à "faire émerger" les comportements des mots puis à les représenter ou à affiner les représentations existantes et enfin à classer les structures de représentation construites.
Notre travail vise à la mise au point d'outils de modélisation adaptés à des problèmes fondamentaux de représentation des connaissances en sémantique lexicale. L'hypothèse suivie dans ce travail est que ces connaissances ne sont pratiquement jamais complètes et intangibles. Au contraire, il faut gérer leur extension et leur modification. Si les descriptions linguistiques se bornent à refléter un savoir partagé sur le monde, en particulier si le lexique est organisé (de manière hiérarchique ou non) sur la base de connaissances (le monde objectif), on perd une grande partie des mécanismes à l'oeuvre dans le langage naturel. L'interprétation permet en effet la mise en oeuvre de processus sémantiques qui créent de nouvelles acceptations et de nouveaux emplois non dérivables de la connaissance encyclopédique. Dans ce cas les parcours (arborescents ou non) n'apprennent rien que l'on ne sache déjà [RAS 95]. Figer les savoirs linguistiques dans des taxonomies figées et non évolutives ne convient guère à la structure sémantique des langues et assez mal à celle des discours de spécialité [BIB 93]. Un travail de représentation des faits de langue doit donc s'attacher à rendre les savoirs de base évolutifs en sachant qu'un ajustement est toujours potentiellement à venir sur ces savoirs. L'enrichissement des connaissances repose dans notre travail sur l'utilisation de corpus dans des domaines de spécialité, ici les comptes rendus d'hospitalisation en médecine coronarienne. Notre travail de représentation et de classement s'appuie sur une recherche initiale au niveau des mots des régularités et des redondances d'utilisation dans des corpus donnés. Nous ne nous imposons ni une représentation prédéfinie des informations linguistiques ni un classement prédéfini de ces informations, mais nous choisissons une démarche qui tente de construire ces représentations puis d'établir progressivement leur classement en tenant compte des informations délivrées par le travail d'acquisition de savoirs à partir de corpus. Ce travail utilise le prototype
(dans le cadre de la programmation à prototypes [BLA 94]) comme un outil de représentation de faits linguistiques dans la mesure où nous pensons qu'il peut répondre à certains problèmes que posent ces faits de langue. Cet outil conduit à construire des structures de représentation simples et ajustables pour rendre compte justement des problèmes d'ajustements qui sont à l'oeuvre dans la construction du sens dans le langage naturel.
3. Acquisition de savoirs en corpus
L'hypothèse suivie ici est qu'il y a peu de sens à vouloir faire de l'acquisition sémantique en dehors d'un sous-langage. Notre travail de représentation et de classement s'appuie sur une recherche initiale au niveau des mots des régularités et des redondances d'utilisation dans des corpus donnés. Le corpus utilisé par GASPAR est celui qui est constitué dans le cadre du projet MENELAS [ZWE 94] pour la compréhension de textes médicaux. Ce corpus est utilisé par le Groupe de Travail Terminologique et Intelligence Artificielle (PRC-GDR Intelligence Artificielle, CNRS). L'unité thématique de ce corpus a trait aux maladies coronariennes. Les informations extraites sont des arbres d'analyse fournis par des outils d'extraction terminologique (LEXTER, AlethIP), ces arbres étant ensuite simplifiés dans le but de déterminer les arbres élémentaires de dépendance qu'il est possible d'associer aux mots (ZELLIG) : sont considérés comme élémentaires les arbres mettant en évidence une relation binaire entre deux mots pleins, nom ou adjectif, dans des schémas comme, par exemple,
N Prep N ou N Adj. Cette chaîne de traitements est présentée infra. Notre travail s'inscrit dans une reprise de l'approche harrisienne [HAR 70-88] et vise à automatiser les traitements de représentation des mots et de leur classement (en utilisant des informations extraites à partir de corpus) et à souligner les limites de cette induction de savoirs. Un premier objectif est de construire des représentations informatiques évolutives de mots à partir d'informations extraites sur corpus. Le travail de représentation mis en place ne construit donc pas une représentation prédéterminée du sens attaché aux mots ou aux structures syntaxiques représentées, il doit proposer des amorces d'interprétation qui doivent être affinées par un travail d'interprétation plus fin. Le second objectif est de classer les mots représentés et de tendre vers la détermination de classes sémantiques, de manière inductive. Tout d'abord, il convient de souligner que le classement automatique présenté ici s'appuie principalement sur des contraintes syntaxiques associés aux mots. Dans notre travail, la syntaxe est utilisée pour dégrossir la représentation et le classement des mots mais ne permet pas à elle seule de classer les mots représentés. A l'inverse des approches harrissiennes et statistiques, notre approche ne conduit pas à la détermination de classes sémantiques satisfaisantes mais elle constitue une méthode d'amorçage pour l'élaboration de l'ontologie du domaine, nous suivons sur ce point la démarche suivie par [HAB 96a] : la construction de l'ontologie du domaine étudié nécessite un part d'interprétation. Notre approche de classement des mots est conçu en fait pour aider à accéder aux sens [HAB 97d]. Il est important de souligner que les résultats construits ne sont pertinents que pour les corpus étudiés. Les relations syntactico-sémantiques mises en avant par le travail d'extraction de savoirs sont propres aux corpus examinés, le travail de représentation et de classement des mots sur la base des savoirs reçus est donc lui aussi complètement dépendant de ces corpus. Si on peut envisager d'élaborer une ontologie à partir des résultats construits (un travail d'interprétation sur les résultats construits reste à définir et à faire), celle-ci ne sera elle aussi pertinente que pour le corpus étudié [ZWE 97].
La phase d'acquisition d'informations à partir de corpus prend appui sur la systématicité structurelle et sémantique propre aux sous-langages [HAR 70-88] afin de mettre au jour les proximités de cooccurrences entre mots pour dégager les relations sémantiques sous-jacentes. Le point de départ du travail de représentation est donc constitué par le corpus MENELAS. Les informations utilisées par les processus de représentation informatique des mots et des arbres associés sont issues d'une chaîne de traitements composée des logiciels LEXTER, AlethIP et ZELLIG. Le but de ces outils est d'une part d'extraire des informations à partir de corpus (LEXTER, AlethIP) et d'autre part de simplifier ces informations puis de caractériser leurs fonctionnements (ZELLIG). LEXTER prend en entrée des textes arbitrairement longs et produit des arbres d'analyse de séquences nominales en décomposant ces séquences en Tête et Expansion et ce de manière récursive. Il est important de souligner que la démarche de LEXTER est endogène c'est à dire que le travail d'analyse s'appuie uniquement sur les résultats d'analyse déjà construits pour analyser des séquences ambigües. Si le corpus contient la séquence "angine de poitrine instable", on a deux analyses possibles pour cette séquence : (1)
[angine de poitrine] instable, (2) angine de [poitrine instable]. LEXTER va prendre appui sur des séquences déjà analysées pour produire une analyse de cette séquence. Si on a la séquence "angine de poitrine" et si l'on n'a pas "poitrine instable", LEXTER produira l'analyse (1). L'approche endogène suivie par LEXTER s'inscrit parfaitement dans le cadre de représentation qui est le nôtre. Le logiciel ZELLIG a ensuite pour tâche de simplifier les arbres d'analyse fournis ici par LEXTER et de mettre en évidence les relations élémentaires de dépendance entre mots pleins, nom ou adjectif, dans des schémas comme, par exemple, N Prep N ou N Adj.
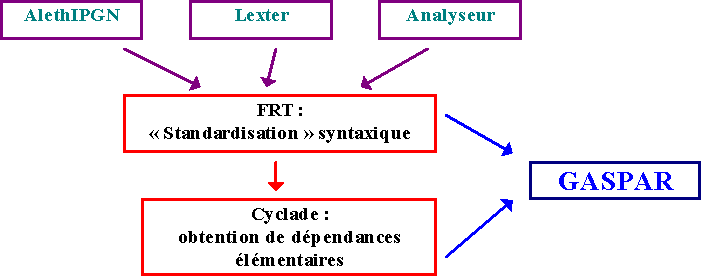
Figure 1. Une chaîne de traitements automatiques.
Les arbres issus de LEXTER sont d'abord transformés en arbres syntagmatiques via le transducteur FRT (un module de ZELLIG) [HAB 97a]. Le programme Cyclade (un autre module de ZELLIG) est ensuite chargé de déterminer les arbres élémentaires via un filtrage de quasi-arbres [HAB 96b]. Ces dépendances élémentaires associent à un élément gouverneur (nommé tête) soit un argument soit un circonstant. "Les dépendances élémentaires ainsi définies n'ont pas forcément de réalisation effective dans le corpus mais ils correspondent à des relations de dépendance vérifiées dans les arbres d'analyse, si l'on passe par une représentation logique de ces arbres et de ces dépendances élémentaires". La figure qui suit présente de manière synthétique le séquencement des activités réalisées par ZELLIG. Il convient de souligner que le dispositif GASPAR n´utilise qu´une partie des résultats produits par la chaîne de traitements autour de Zellig : en l´occurrence, un corpus de mots et d´arbres simplifiés associés.
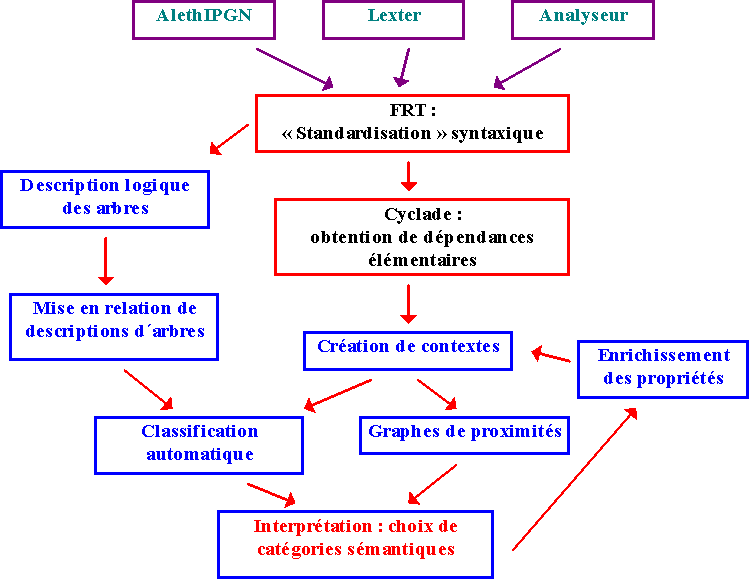
Figure 2. ZELLIG, une chaîne de recyclage d´arbres.
On résume ici de manière synthétique ce que la chaîne de traitements réalise pour produire les arbres minimaux à partir du corpus initial. Le point de départ est constitué de rapports médicaux.
Patient âgé de 70 ans, diabétique, qui a présenté il y a un an une douleur thoracique nocturne probablement en rapport avec un infarctus antéro-septal. Il est toujours symptomatique sous la forme d'un angor d'effort qu'il a lui-même négligé, avec semble-t-il plusieurs épisodes de préchordialgies de repos. La coronographie met en évidence des lésions bitronculaires. L'occlusion de l'IVA est responsable d'une hypokinésie antérieure. Une sténose serrée, diagonale et circonflexe est responsable de l'angor d'effort.
LEXTER produit ensuite des arbres d'analyse de séquences nominales en décomposant ces séquences et en les structurant. Sur la séquence "alteration severe de la fonction ventriculaire gauche", on obtient l'analyse suivante.
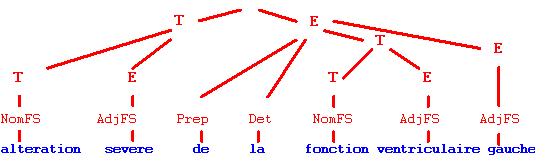
Figure 3. LEXTER.
Enfin, ZELLIG met en évidence les dépendances élémentaires dans ces arbres d'analyse. À partir de l'arbre précédent, les arbres élémentaires (a, b, c, d) mis au jour sont décrits dans la figure qui suit :
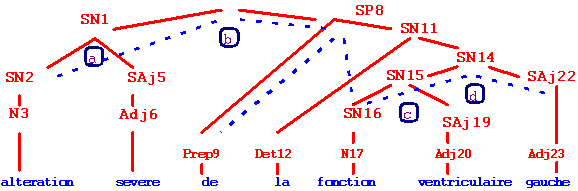
Figure 4. ZELLIG.
GASPAR est une chaîne de traitements automatiques pour la représentation et le classement automatiques de mots et de leurs comportements syntaxico-sémantiques.
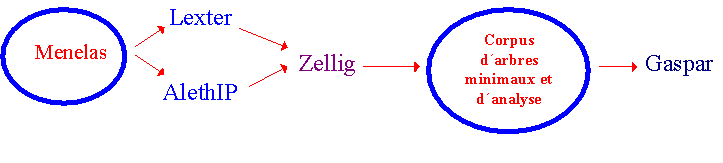
Figure 5. Traitements avant GASPAR.
GASPAR dispose, au départ, d'informations extraites à partir d'un corpus (sous la forme d'un fichier texte) : pour chaque mot, GASPAR dispose d'informations morphologiques et sémantiques décrivant ces mots, d'une liste d'arbres élémentaires et d'une liste d'arbres d'analyse associés aux arbres élémentaires (des contraintes peuvent être attachées aux composants des arbres, on y reviendra infra). Ces descriptions sont généralement peu précises ou en tout cas sous-déterminées. GASPAR utilise ces informations pour construire des prototypes afin de représenter les mots et leurs comportements (les arbres associés). Le processus de représentation s'appuie uniquement sur ces informations pour construire des prototypes. Le dispositif GASPAR se fixe plusieurs objectifs. Il doit réaliser une génération automatique des représentations syntaxico-sémantiques associées aux mots, par affinements successifs. Ce travail de représentation prend appui sur des savoirs extraits à partir de corpus. Le sens des mots n'est pas prédéfini dans la représentation construite de ces mots. C'est l'examen des informations contextuelles associées au mot qui doit permettre de proposer des pistes de sens possibles. Il doit ensuite construire des hiérarchies (évolutives) de base de connaissances (évolutives par nature). Notre approche vise à travailler à partir d'informations attachées aux mots. Le système doit construire des représentations informatiques de ces mots, il doit ensuite repérer les partages possibles de ces informations. Cette démarche de représentation ascendante créé initialement des macro-structures approximatives qu'il convient d'affiner progressivement, soit en tenant compte de nouvelles informations issues du travail d'extraction à partir de corpus, soit en tenant compte des informations que la situation contextuelle délivrera. Il s'agit en fait de mettre en place et d'affiner l'équilibre qui existe entre des savoirs localement répartis et des savoirs partagés qui établissent des liens entre les éléments représentés. Pour mener à bien cette tâche, il est clair que le système doit pouvoir manipuler et assimiler un grand nombre d'informations pour réaliser ces objectifs de représentation et de classement. Actuellement, le système GASPAR prend appui sur la micro-syntaxe attachée aux mots pour construire un réseau de pôles de comportements partagés par des ensembles de prototypes. Les classes de mots construites sont des ébauches imparfaites qui permettent un organisation du matériel lexical. Ces classes doivent ensuite aider à affiner le travail de description des mots représentés sous la forme de prototypes. De fait la construction progressive de la description des mots passe par un apprentissage manuel de nouveaux savoirs. C'est à l'utilisateur du dispositif d'interpréter et d'évaluer les objets construits et les résultats produits. Ce travail d'interprétation est d'ailleurs un passage obligé de toutes les approches en classification automatique (en analyse de données par exemple, mais aussi dans des traitements syntaxiques à la Grefenstette [GRE 93-94]). Le système construit s'inscrit d'ailleurs dans une approche qui vise à établir un dialogue entre le dispositif informatique construit et les problèmes posés par les faits linguistiques étudiés. L'intervention manuelle du linguiste s'inscrit parfaitement dans une telle approche. En outre l'environnement de programmation choisi permet à tout moment d'affiner les représentations construites.
4. PàP : Programmation A Prototypes
L'outil de représentation choisi est la programmation à prototypes (désormais notée PàP) [BLA 94]. La PàP s'est développée à la fin des années 80, à partir des travaux entre autres de Liebermann et de l'équipe d'informaticiens de Stanford et de Sun Microsystems qui ont par la suite développé le langage à prototypes Self [SEL 93-95]. La PàP conduit à penser différemment pour construire une représentation informatique d'un certain domaine de connaissances. Il ne s'agit pas de partir d'une somme de connaissances figées et connues par avance mais de construire progressivement les entités informatiques suivant les connaissances dont on dispose sur le domaine visé. Si les informations à représenter ne sont pas connues de manière définitive, il est possible de commencer le processus de représentation en utilisant les informations déjà recensées puis d'affiner dynamiquement les objets construits dès que de nouvelles informations sont disponibles. Si de nouvelles connaissances sont mises au jour, on peut affiner le processus de représentation déjà amorcé en tenant compte de ces nouvelles informations sans avoir à reconstruire entièrement de nouvelles structures. Notre travail utilise le prototype comme un outil de représentation de faits linguistiques dans la mesure où nous pensons qu'il peut répondre à certains problèmes que posent ces faits de langue. Cet outil conduit à construire des structures de représentation simples et ajustables pour rendre compte justement des problèmes d'ajustements qui sont à l'oeuvre dans la construction du sens dans le langage naturel. La flexibilité du modèle de représentation choisi constitue une propriété fondamentale pour développer des processus de représentation capables de rendre compte des aspects mouvants du domaine décrit. Il convient de préciser que l'approche de la PàP n'a rien à voir avec celle adoptée par les cognitivistes tels que Rosch dans leur présentation de la prototypie [Rosch 75-76].
Par la suite nous utilisons les expressions suivantes : on appelle prototype de mot/d'arbre l'objet informatique (le prototype) défini pour représenter un mot/arbre.
4.1. Une entité, un prototype
A partir d'un élément particulier d'un domaine à représenter, on construit un objet informatique sans passer par un filtre prédéfinitoire (la notion de classe n'existe pas). Si on considère les noms
stenose et lesion, ils partagent des informations et des comportements : ils appartiennent à la même catégorie, ils partagent des comportements syntaxiques. Il est donc intéressant d'utiliser la représentation de l'un de ces mots pour représenter l'autre. Si la catégorie syntaxique de stenose n'est pas encore représentée, on définit automatiquement les objets pour la représenter avec les attributs adéquats. On construit donc un objet informatique, le prototype stenose, à partir d'un savoir (de sens commun) que l'on a sur ce nom : stenose est un nom féminin singulier. On crée un objet avec des attributs qui porte ces valeurs.
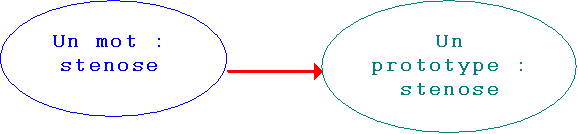
Figure 6. Un mot, un prototype.
4.2. Représentation d'une entité similaire par clonage et différenciation
Une fois que l'on a construit un objet particulier, on utilise deux opérations fondamentales pour représenter d'autres éléments sous la forme de prototypes : le clonage et l'ajustement. L'opération de clonage produit une copie conforme de l'objet cloné. Il convient ensuite d'ajuster le prototype issu du clonage pour représenter adéquatement le nouvel élément. Sur chaque objet créé, on peut à tout moment ajuster sa représentation en ajoutant de l'information ou en retirant, les modifications ne s'appliquant que sur les objets auxquels les messages de modifications sont adressés.
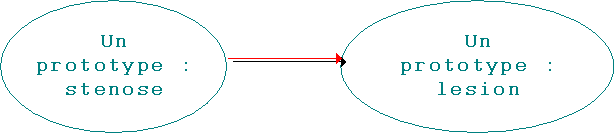
Figure 7. Copie et ajustement de prototype.
Dans notre exemple, l'opération de clonage appliquée au prototype
stenose permet l'obtention d'une copie conforme de ce prototype. Pour représenter le nom lesion, on ajuste ensuite les attributs du prototype résultant en donnant à ces derniers les valeurs adéquates. On peut ensuite représenter les contraintes syntaxiques associés à stenose.Si la catégorie de l'arbre élémentaire n'est pas encore représentée, on génère automatiquement un prototype d'arbre pour la représenter avec les attributs adéquats.
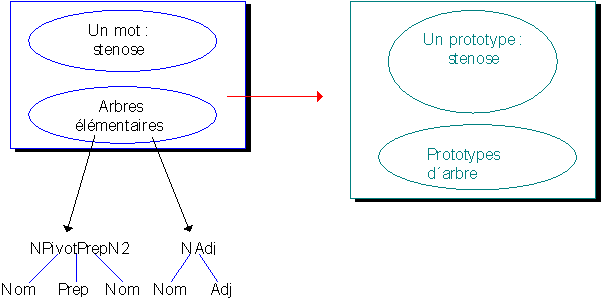
Figure 8. Un arbre, un prototype.
Puisque les mots stenose et lesion partagent des arbres élémentaires (les arbres NPivotPrepN2 et NAdj), les prototypes d'arbres déjà construits pour stenose et partagés par lesion seront associés au prototype associé à lesion. On affecte ensuite aux prototypes de mots construits leurs comportements syntaxiques (les prototypes d'arbres associés).
4.3. Partage des structures et des comportements communs par délégation
La PàP met en place une représentation de savoirs que l'on peut considérer comme peu organisée au départ. Les savoirs représentés sont répartis sur une myriade de structures peu connectées entre elles à priori. La PàP ne rejette pas pour autant toute idée de classification. Elle met en place un système d'héritage simple basé sur la délégation qui permet de factoriser localement des comportements partagés. Dans la mesure où il est possible d'ajuster dynamiquement les prototypes (ajout ou retrait d'attribut), on peut à tout moment construire des liens de délégation. Dans le cas de nos prototypes
stenose et lesion, ces deux objets partagent des savoirs, on factorise donc les comportements communs aux représentations de ces deux mots.
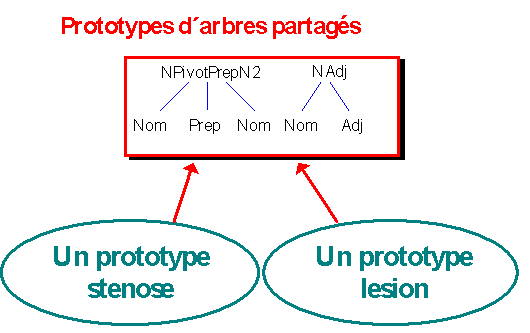
Figure 9. Partage de comportements.