Projet Encadré 2
Boîtes à Outils
Ce travail est mené dans le cadre du cours Projet Encadré du Master Traitement Automatique des Langues (Master TAL), donné par la collaboration des universités de Nanterre, Sorbonne Nouvelle paris 3 et INALCO. Cette vitrine permet la démonstration de compétences gagnées au second semestre de la formation. Ce projet est assuré par l'encadrement de nos professeurs : Serge Fleury (Paris 3) et Jean-Michel Daube (INALCO).
Aucun blog de travail n'est disponible pour ce groupe. Des changements de partenaires s'étant fait il y a une dizaine de jour.

Objectif du projet
L'objectif final du projet intitulé Boîte à Outils est le suivant :
obetnir des informations linguistiques de plusieurs rubriques provenant du journal Le Monde. Le projet a pour but de nous familiariser avec un autre type de langage très en vogue il y a quelques années, le langage Perl. Une série de boîte à outils (BaO) seront présentées sur cette vitrine, accompagnées de scripts Perl et Python afin de montrer d'autres méthodes d'application au but pour lequel les BaO ont été crées.

Plan de Travail
Le travail s'est fait de la façon décrite ci-dessous :
1. Lacement des scripts
2. Elaboration de scripts dans d'autres langages de programmation
3. Extraction et analyse des résultats obtenus
4. Fabrication d'une vitrine contenant les boîtes à outils, les résultats et éventuelles remarques
Introduction aux Boîtes à outils
Chaque Boite à outil permet l'exécution d'une tache précise. Cette tâche peut aussi s'effectuer par le biais d'autres langages de programmations que nous expliciteront plus tard.
On peut notamment citer python et ses modules ou bien xslt et les xqueries. A travers les boîtes à outils, on cherche à :
- l'extraction de texte,
- l'étiquettage, la lemmatisation
- et enfin, la classification des différentes rubriques

Boîte à Outils 3 en 1 !
Le script joint ci-contre est une concaténation des trois bao en un script.
Ce dernier permet notamment d'obtenir une sortie de fichier en plus des fichiers de sorties de la bao 1. Les sorties sont rangées par fichiers et par date de publication. Plus loin, nous présentons quatre autres bao1. Les quatre autres bao1, sont quant à elles rangées par items.
Vous pouvez visionner le script ici !
Résultats
Le script a été appliqué sur les rubriques :
- Rubrique A la Une : Sortie .txt , XML,
- Rubrique Médias : Sortie .txt, et XML
- Rubrique Sport : Sortie XML, et .txt
- Rubrique Cinéma : Sortie.txt et XML
- Rubrique Planète : Sortie XML et .txt
- Rubrique Voyage : Sortie .txt et XML
Enfin, la sortie Udpipe, Patron au format txt, et les sorties de patron pour Udpipe : VDN, NPRN, NADPNADP, NADJ, DADJNV, ADJN, Dépendance, et Classification
Zoom sur les résultats
Parmi les résultats recensés après application du classifier Cosine Similarity, nous avons remarqué qu'une seule catégorie avait un résultat plutôt moyen...
Chaque rubrique a un taux de classification qui relève du 98-100%. Or, la rubrique planète semble bien nous donner des petits soucis avec un premier essai montant à 90% de réussite.
Cette chute nous conduit donc à comprendre pourquoi.
Zoom sur les résultats
Quand on affiche le sac de mots dans planète, aucun élément ne ressort, mais beaucoup d'occurences comme "rôles", "films", "acteur", "prix", césar" prennent le pas dans cinéma.
De même, la diversité des mots dans planète montre bien qu'il n'y pas d'occurrence dominante. De plus, il fait partie des rubriques les plus complexe de par sa taille (tout petit).
...
Ce qu'il serait intéressant de faire, c'est de prendre en compte la taille des rubriques en implémentant un coefficient sur la taille. Ceci permettrait de mettre en concurrence cette catégories avec d'autres rubriques aussi petites (voyages, médias notamment). On règle alors un problème de faux positifs, ce qui résoleverait le problème.
Boîtes à Outils : une diversité de langages
Comme dit précédemment, il est possible de concevoir d'autre script ayant le même but que ceux explicités respectivement plus tôt. Les scripts suivants vous présenteront d'autres moyens d'extractions, d'étiquettages, etc.
Une autre façon de faire...
BaO1 REGEX : Si vous êtes curieux?
BaO1 XML::RSS : Vous pouvez jeter un oeil ici!
BaO1 Uniq Regex : Vous êtes conviés à regarder ici !
BaO1 Uniq RSS : Pour plus d'informations regarder ici !
Quelques points...
Concernant la rubrique la plus dure à classer (planète), il existait une autre solution afin d'augmenter le classement de cette catégorie (pour rappel, nous avions un taux de 90% de bon classement) L'une des sous catégories dans plnète faisait fortement défauts à nos résultats de classement. C'était la rubrique internationale. Afin de vérifier l'origine du problème, et par soucis de bien faire, cette dernière (internationale) a été retirée, le script relancé sans, et c'est un taux de 93% que nous obtenons !
Aussi, une extraction de dépendance syntaxique a été mise en place en Perl (relation de type obj) uniquement en regex à partir d'udpipe raw, ainsi qu'un stemmer. Cependant, ce dernier ralentit pas mal le script : environ 6 à 7 fois plus de temps pour 5 point de pourcentage de précision gagnés.
Sur la rubrique économie, on a un délai d'attente de 1400s. La question de le garder ou non s'est alors posé, puisqu'il était question de savoir si cela en valait vraiment la peine. (cf conclusion)
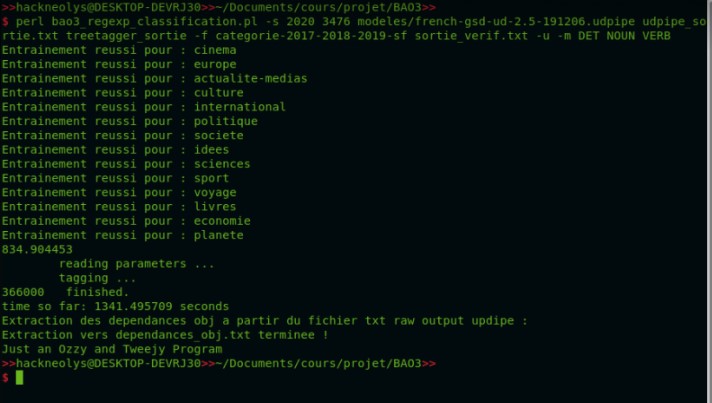
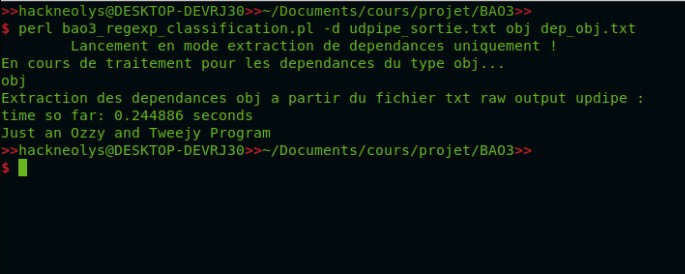
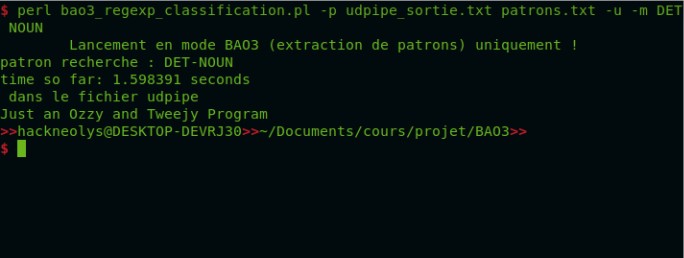
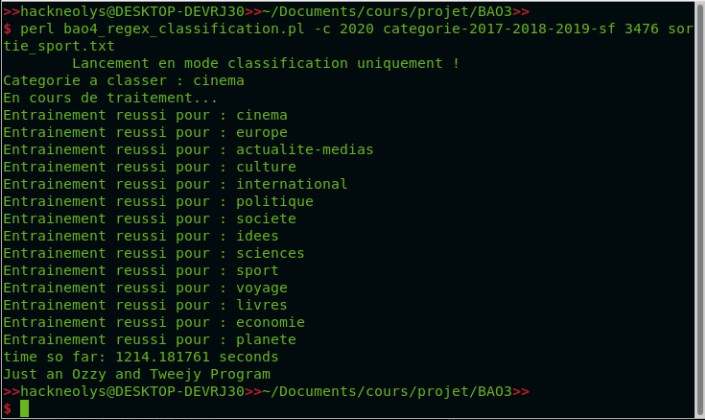
Tableau comparatif
Temps pris en seconde
| Boîte à outil | Langage utilisé | Temps d'exécution |
|---|---|---|
| Bao 1 | Script REGEX | 0.17452 seondes |
| Bao 1 | Script XML::RSS | 2.620818 secondes |
| Bao 1 | Script Uniq Regex | 0,18243 secondes |
| Bao 1 | Script Uniq RSS | 2.727268 secondes |
| Durée moyenne bao3en1 | 1600 secondes | |
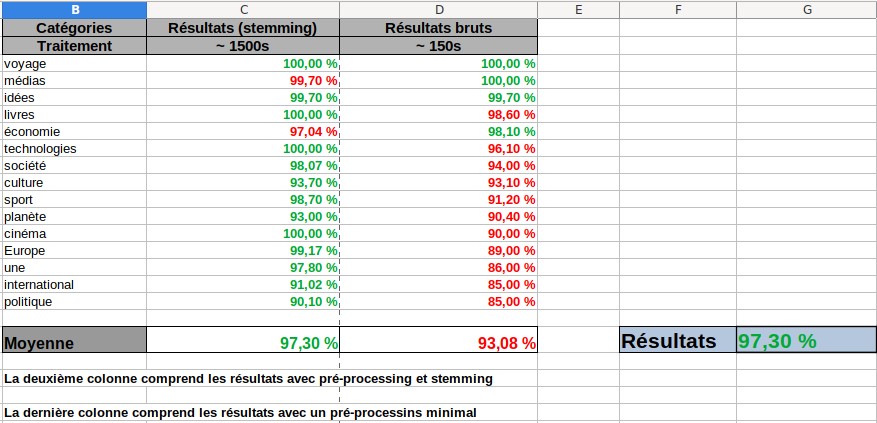
Conclusion
Finalement, la partie qui nous a parut cruciale était la classification des catégories. C'est aussi la partie qui nous a pris le plus de temps à traiter.
L'idée étant de ne pas avoir de résultats digne de classifieurs "classe majoritaire", il était logique d'utiliser le Cosine Similarity.
Les résultats obtenues nous mettent notamment en exergue que les classes qui ont le plus de difficultés à être classées reste ceux dont le sac
de mots ne donne pas de "préférence" lexicale (thème). Pas de prédominance lexicale entraîne du bruits. C'est ce qui dérange par ailleurs la précision
Dans notre cas, le stemming a aidé la précision et nous permet d'augmenter la bonne classification des données sous études. Toutefois, cela im-
-plique un temps de traitement 10 fois plus long pour 4 points de pourcentage gagnés. La vrai question étant : "est ce que cela en vaut la peine ?" Et bien,
les deux points de vue se défendent. D'un côté, sans stemming, nous obtenons des résultats plus que correct. La marge de progression du classifieur n'est pas
exceptionnellement grande. De plus, le temps d'attente est considérablement plus conséquent comparé au lancé sans stemming. On pourrait très bien comprendre
que cela n'en vaut pas vraiment la peine. Or, le résultat post-stemming reste très surprenant et bien qu'il n'y ait pas une marge de progression lourde, elle
reste présente. C'est d'ailleurs cette petite montée qui permet d'atteindre la perfection. Perfection dont on se rapproche davantage ici.
Enfin, les possibilités du programme de la bao3en1 étant nombreuses, il est impossible de tout afficher sur un site web. Au readme est ajouté toutes les nouvelles options.
En voici quelques unes. Le gros script peut s'utiliser pour n'avoir que la bao1, bao2, bao3 ; seulement la bao3 ; seulement la classifcationou bien l'extraction
de patrons ou encore, que extraction de dependances