Explication
Nous avons, dans un premier temps, entré tous les patrons morpho-syntaxiques dans deux fichiers texte brut, en prenant soin de bien respecter la syntaxe des POS tag utilisés par chaque outil (TreeTagger et UDPipe). Nous utiliserons ces fichiers lors de l’exécution du script Perl.
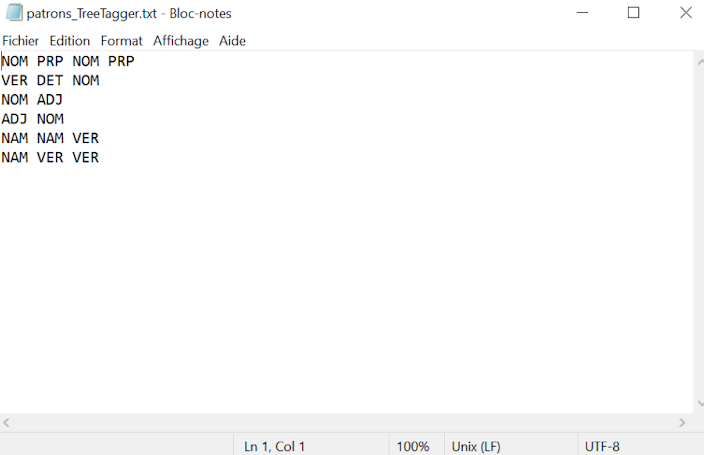
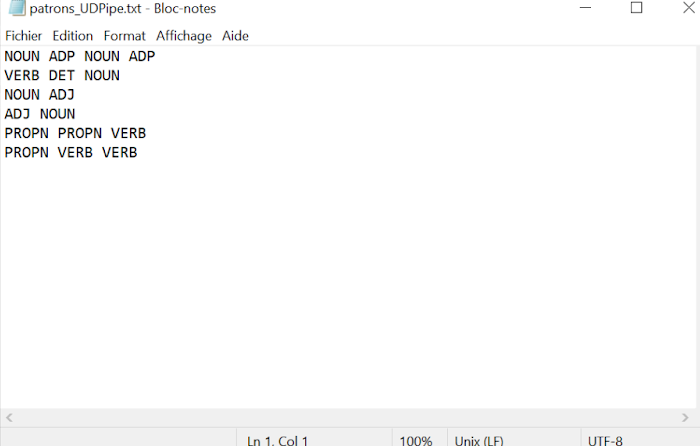
- Nous récupérons tout d’abord la liste de patrons morpho-syntaxiques du fichier de patrons.
- Ensuite, nous lisons le fichier annoté. Si nous trouvons dans le fichier une partie de discours (part-of-speech, POS) qui correspond également à la première étiquette d’un patron, nous récupérons la suite de POS et de tokens associés de la même longueur que le patron.
- Nous comparons par la suite le patron et la suite de POS extraite. Si les deux coïncident, nous sauvegardons la suite de tokens associée dans une table de hashage qui regroupe, à la fin du programme, toutes les séquences trouvées.
Extraction des patrons morphosyntaxiques
Extrcation à partir des sorties TreeTagger
Les fichiers annotés par TreeTagger étant des fichiers XML, nous avons utilisé des expressions régulières pour extraire les séquences de mots correspondant aux patrons morpho-syntaxiques.
Dans les fichiers TreeTagger, les différents types de prépositions sont annotés “PRP”, ou bien “PRP:det”. Grâce aux expressions régulières, il suffit de mettre seulement “PRP” dans les patrons pour que les deux types d’étiquettes soient extraites. Il n’y a pas besoin de rajouter “.+?” dans le patron, d’autant plus qu’avec cet ajout, l’extraction pour ce patron ne marche pas.
Pour exécuter ce programme, nous devons nous placer sur le répertoire de travail ProjetEncadre et donner en argument le numéro/les caractères correspondant à une rubrique.
perl ./BAO3/Perl/BAO3_ExtractionPatrons_TreeTagger.pl numero_rubriqueExtrcation à partir des sorties UDPipe
Pour l’extraction des patrons morpho-syntaxiques, nous utilisons la sortie UDPipe brute, c’est-à-dire au format CONLL, et non la version transformée en XML.
Contrairement à la version TreeTagger, nous n’utilisons pas ici les expressions régulières pour récupérer les POS et les tokens. Nous employons la fonction split de Perl et attrapons les informations nécessaires grâce à leur position sur la ligne.
Dans les POS tags utilisés par UDPipe, l’étiquette pour les prépositions n'existe pas. C’est l’étiquette des adpositions (prépositions et postpositions) qui est utilisée : “ADP”.
Comme pour le programme pour les fichiers TreeTagger, il faut se placer à un endroit précis de l’arborescence : le répertoire de travail ProjetEncadre.
perl ./BAO3/Perl/BAO3_ExtractionPatrons_UDPipe.pl numero_rubriqueRésultats obtenus
| Script Perl | Résultats |
|---|---|
| Fichier | Liste extraction TreeTagger |
| Fichier | Liste extraction UDPipe |
Comparaison des résultats
Grâce aux sorties de ces programmes, nous pouvons remarquer des erreurs d’étiquetage de la part de TreeTagger et de UDPipe. Voici des listes non exhaustives des fautes trouvées.
Erreurs d’étiquetage TreeTagger
- La double quote (”) est étiquetée comme NOM.
- Les mots dans la séquence “d’un” ne sont pas séparés. De plus, “d’un” est annoté comme ADJ.
- La suite “qu’il n’y” est annotée comme “ADJ NOM”.
- “UN GRAPHIQUE –” ou bien “LE CHIFFRE –” sont annotés comme “NAM NAM VER:futu”.
- “…” est annoté comme ADJ ou NOM.
La plupart des erreurs de TreeTagger sont peut-être liées à la ponctuation, comme l’utilisation des quotes françaises et non de quotes droites. Par conséquent, la tokenisation n’a pas eu lieu et l’annotation tend donc à être fausse.
L’autre type d’erreurs semble reposer sur la mauvaise interprétation des mots en majuscules.
Erreurs d’étiquetage UDPipe
- “jusqu’en” n’est pas séparé et il est annoté soit en NOUN, soit en ADJ.
- Dans le même genre, “jusqu’à” n’est pas séparé et il est considéré comme ADP (induit par “à”) ou comme ADV (induit par “jusqu’”).
- “d’Emmanuel” est encore une fois non séparé. Selon les circonstances, il est annoté comme PROPN, ADJ ou DET.
On note également des différences d’étiquetage entre UDPipe et TreeTagger qui explique les écarts dans les résultats des deux programmes. Quelques exemples sont présentés ci-dessous :
| Token | Annotation TreeTagger | Annotation UDPipe |
|---|---|---|
| “premier” | NUM | ADJ |
| “l’union” | NOM | NOUN ou PROPN |
| “d’euros” | NOM | ADJ |
| “due” | VER:pper | ADJ |
Extraction des relations en dépendances
Vu que nous utilisons la sortie UDPipe mais au format XML, nous pourrions utiliser une bibliothèque en Perl pour pouvoir se baser sur un modèle d’arborescence XML.
Néanmoins, nous décidons ici de s'appuyer uniquement sur les données textuelles brutes qui sont à notre disposition. Pour cela, l’emploi des expressions régulières est simple et très efficace pour rechercher la présence de la relation attendue .
L’outil TreeTagger n’effectuant pas d’annotations syntaxiques de dépendance, nous sommes obligés de nous référer à l’annotation de UDPipe.
Nous suivons ici aussi les mêmes étapes que les deux autres méthodes. Nous perdons juste la notion de “frère” issu du format XML, qui est supportée par les méthodes XSLT et XQuery.
Commande permettant l’exécution du programme :
perl ./BAO3/Perl/BAO3_ExtractionDep_UDPipe.pl numero_rubrique "relation_dep"ATTENTION : Il y a un petit élément à prendre en compte.
Vu que nous travaillons ici sur la version XML de la sortie UDPipe (avec les données au format CONLL), les seules fichiers sur lequel nous pouvons travailler sont ceux qui ont été reformatés, c’est-à-dire les 8 rubriques que nous avons marqués auparavant dans le tableau de la BAO2.
| Script Perl | Résultats |
|---|---|
| Fichier | Liste extraction relation en dépendance |