Parcourir toute l'arborescence et extraire les contenus textuels de tous les fils (classement des textes extraits par rubrique)
Rappel du contexte du projet : en schéma
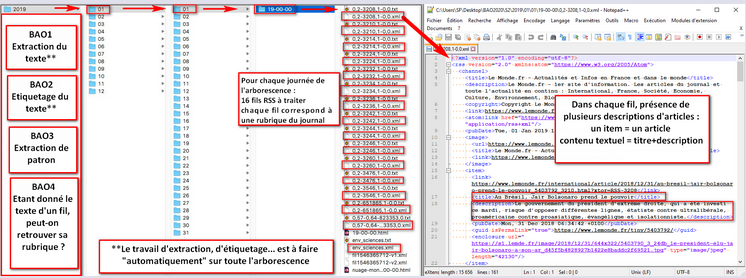
2 programmes d'extraction des contenus textuels : une avec des REGEXP l'autre avec XML::RSS :
Ligne de commande pour lancer le programme :
perl script.pl 2020 rubrique > sortie