1) Méthode Spacy en Python
-------------------------------------------------------------
Objectifs
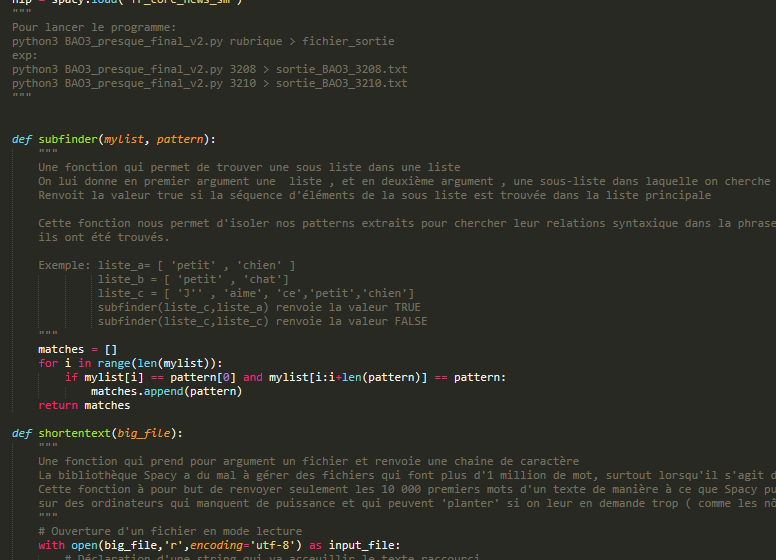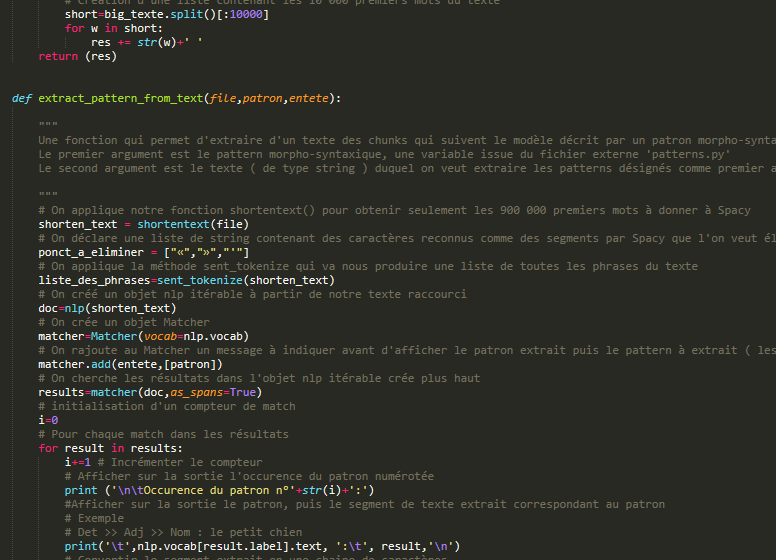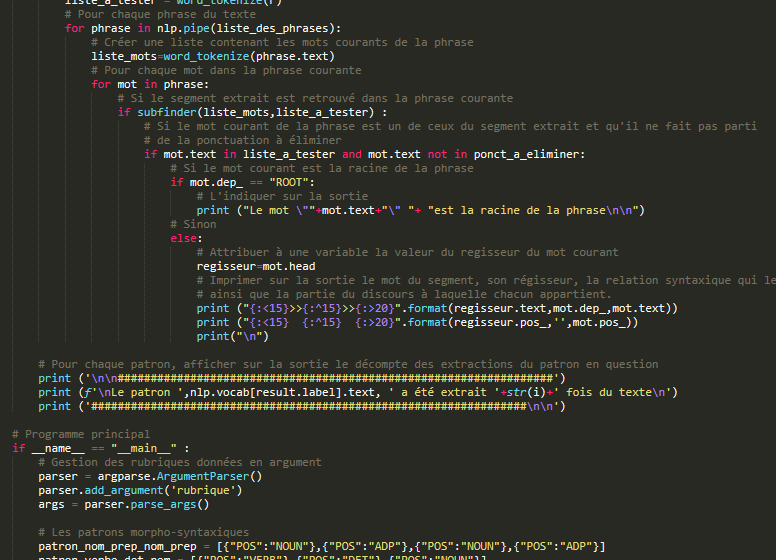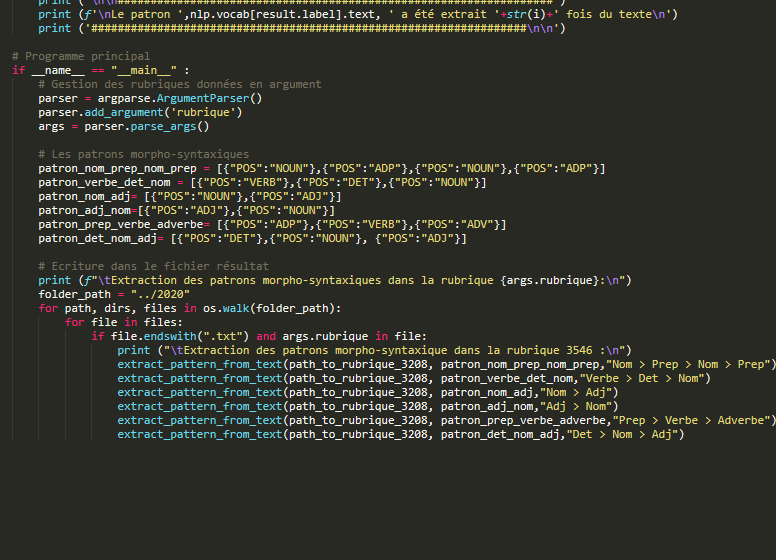
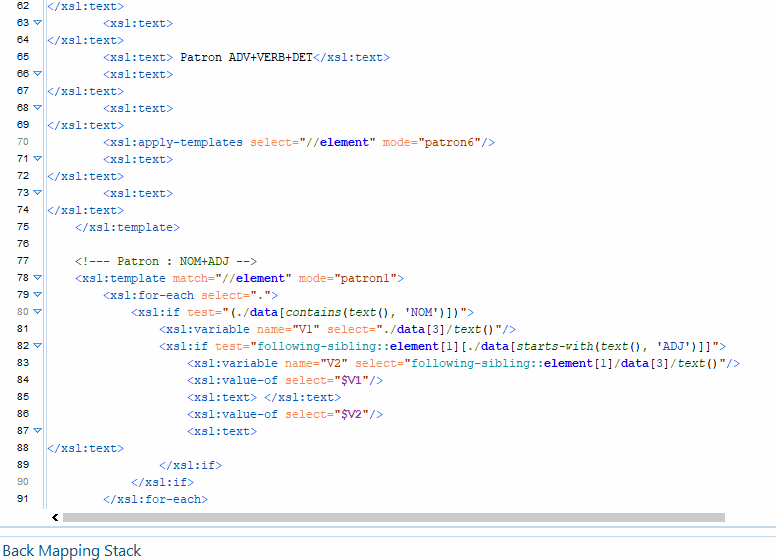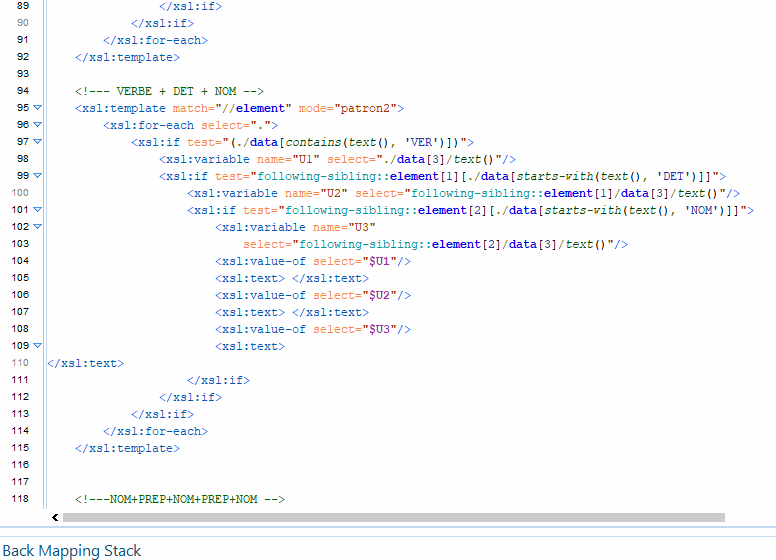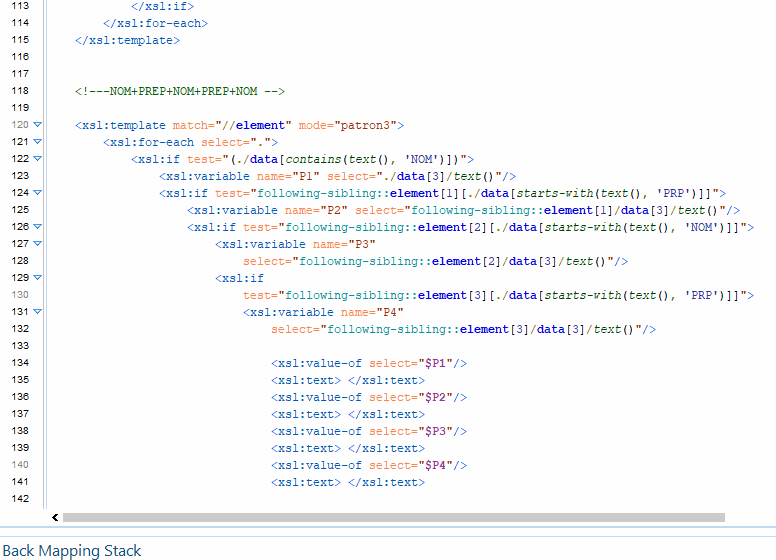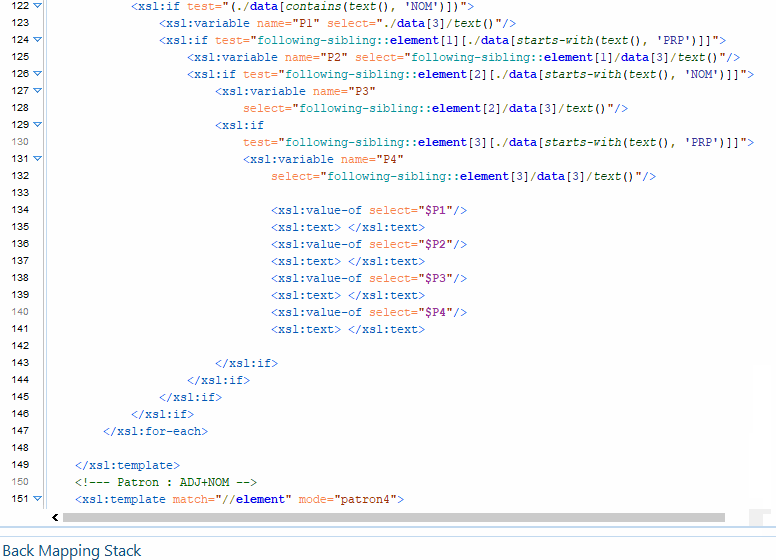
Pour cette boite à outils, l’objectif est d’ extraire de nos sorties texte des segments qui suivent des patrons morpho-syntaxiques définis. On veut par exemple extraire toutes les suites Déterminant › Nom › Adjectif du texte. Nous avons décidé pour ce travail de produire un programme python pour arriver à nos fins. Il s’agit dans un premier temps de préparer les données en amont de façon à ce qu’elles puissent être traitées par le module d’étiquetage de tokens et de relations Spacy. Nous voulons produire en sortie une extraction des patrons désignés, où chaque token est représenté mis en parallèle avec son régisseur ainsi que la relation morpho-syntaxique qui les unit. La spécificité de cette version est qu’elle utilise un jeu d’étiquette différent, le jeu d’Universal Depedencies à l’instar de l’outil GrewMatch.
Les grandes étapes
La première étape consiste à pré traiter nos données en entrée. Spacy est un outil puissant, mais il présente la contrainte d’être gourmand en ressources. Pour que le tagging et le parsing se passent sans encombre, nous avons décider de limiter notre corpus aux 10 000 premiers mots du texte. Nous avons crée une fonction qui gère ce traitement. Ensuite, nous procédons à l’extraction des segments qui suivent nos patrons morphosyntaxiques dans notre texte , selon des patrons définis que nous déclarons dans le programme principal. L’étape suivante est la plus délicate, puisqu’il s’agit maintenant de faire le lien entre les segments phrastiques, et les phrases entières. Il faut donc rechercher leur correspondance dans chaque phrase du texte, afin d’extraire du texte les relations syntaxiques des mots du segments, même quand celle-ci sont entretenues avec des mots qui ne font pas parti du segment. Cela a été assez difficile puisqu’il faut d’abord isoler le segment à analyser et le recontextualiser dans la phrase dont il est extrait.
Sortie
Ainsi, la sortie est construite sur un format qui donne des informations supplémentaires sur les segments extraits. Chaque mot du segment est mis en relation avec son régisseur. Nous indiquons sur la sortie la nature de la relation de gouvernance, ainsi que la partie du discours à laquelle appartient le régisseur et le dépendant ( mot du segment extrait selon le patron ). Chaque segment extrait est numéroté, et on a indiqué à la fin de l’extraction de chaque patron le décompte d’extraction. Veuillez trouver ci-dessous le programme, et plus bas les résultats.