Objectif
Extraire le contenu textuel des fils rss du journal le Monde sur une année.
Donner des arguments en entrée
Pour lancer ce script, nous donnons deux arguments en entrée : le nom du répertoire (2015) et le nom de la rubrique (voir plus loin).
Les arguments donnés en ligne de commande sont passés dans un tableau @ARGV. Pour les récupérer, nous utilisons donc leurs indices ($ARGV[i]) dans notre script.

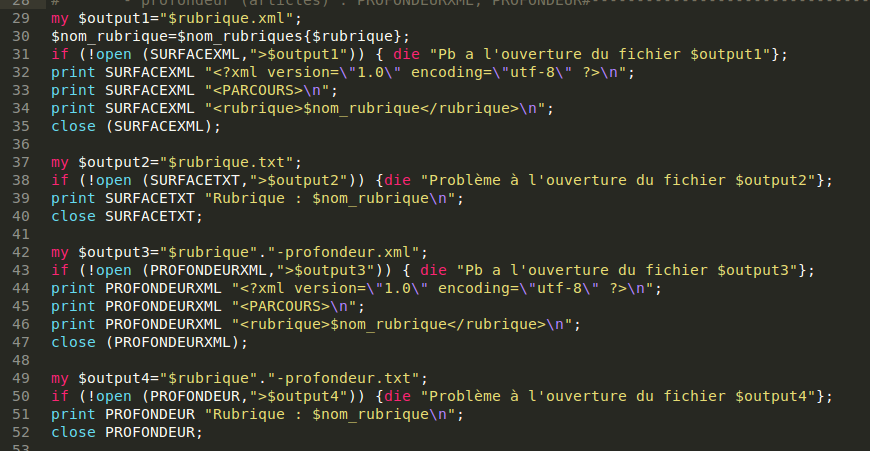
Déclarer les fichiers de sortie
On veut un fichier de sortie au format xml et un fichier de sortie au format txt pour la surface et la profondeur (voir plus loin), soit 4 fichiers de sortie par rubrique.
On les initialise tous au début de notre script (on utilise des descripteurs de fichier explicites pour ne pas se perdre) :
Parcourir une année de données
Voici l'arborescence sur laquelle on doit travailler.



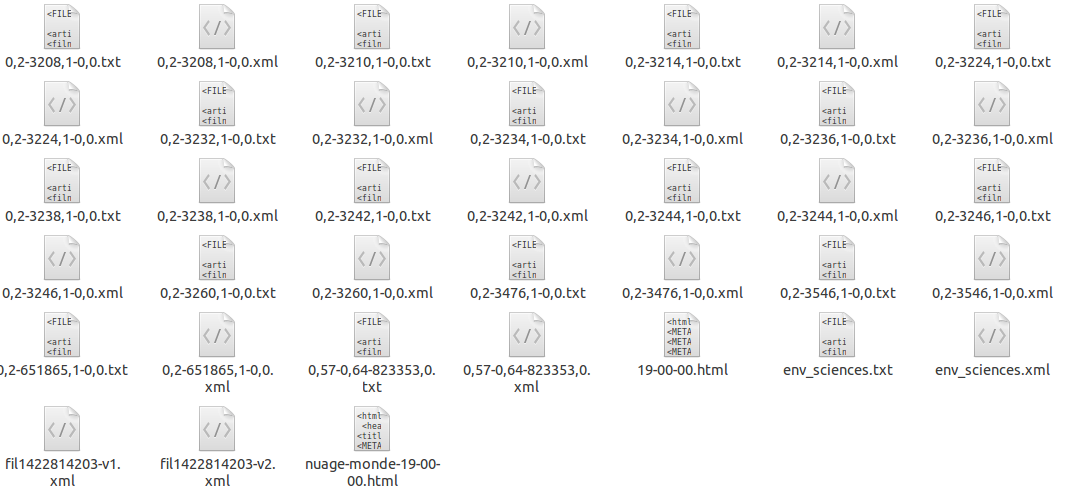
Le fichier dont le nom est de la forme 0,2-3208,1-0,0.xml contient ce qu'on appelle la surface : le titre et la description de chaque article pour une rubrique donnée.
Le fichier dont le nom est de la forme 0,2-3208,1-0,0.txt contient ce qu'on appelle la profondeur : les articles entiers pour une rubrique donnée.
Les noms de rubriques correspondent aux chiffres utilisés dans les noms des fichiers. On déclare leurs équivalents dans une table de hachage au début de notre script pour pouvoir utiliser un nom de rubrique explicite dans nos fichiers de sortie.

Chaque fois qu'un fichier d'une journée est traité, il faut pouvoir à nouveau parcourir l'arborescence et traiter le fichier de la journée suivante et ainsi de suite sur toute l'année. Pour faire cela, on va utiliser ce qu'on appelle une procédure en Perl. Comme une procédure peut s'appeler elle-même, cela va permettre la récursion.
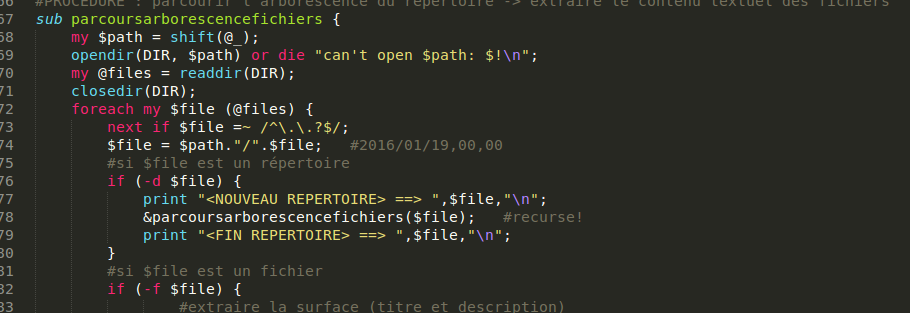
- L'argument qu'on donne à la procédure passe dans le tableau @_.
- On utilise la fonction shift qui enlève le premier élément d'un tableau et prend comme valeur de retour cet élément afin de récupérer cet argument dans une variable $path qui va nous permettre de construire les chemins dont on a besoin pour parcourir l'arborescence.
- Au premier appel de la procédure, on donne comme argument le nom du répertoire 2015. On utilise donc opendir pour ouvrir ce répertoire (et les répertoires suivants lors de la récursion) et on crée une liste avec les éléments qu'il contient à l'aide de readdir.
- On fait ensuite une boucle sur cette liste : si un élément de la liste est un dossier alors on appelle la fameuse procédure à l'intérieur de la procédure qui permet de passer au sous-dossier suivant, si un élément de la liste est un fichier alors on lui applique le traitement décrit ci-dessous.
Extraction de la surface
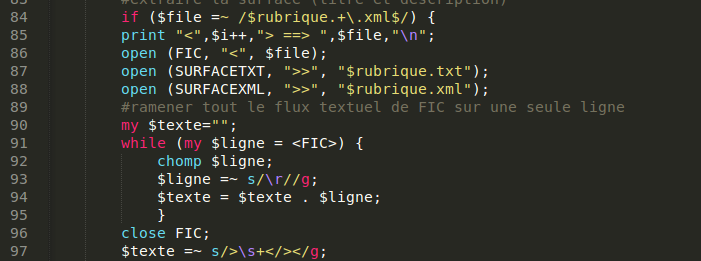
Voici un extrait du fichier xml dont on veut extraire la surface :

On voit que le fichier en question ne compte en réalité que 2 lignes. On va supprimer les retours à la ligne (\r), et mettre tout le texte sur une seule ligne pour pouvoir extraire le contenu qui nous intéresse à l'aide d'expressions régulières. On s'assure également qu'il n'y ait pas de caractère d'espacement (\s) entre une balise fermante et la balise ouvrante qui suit.
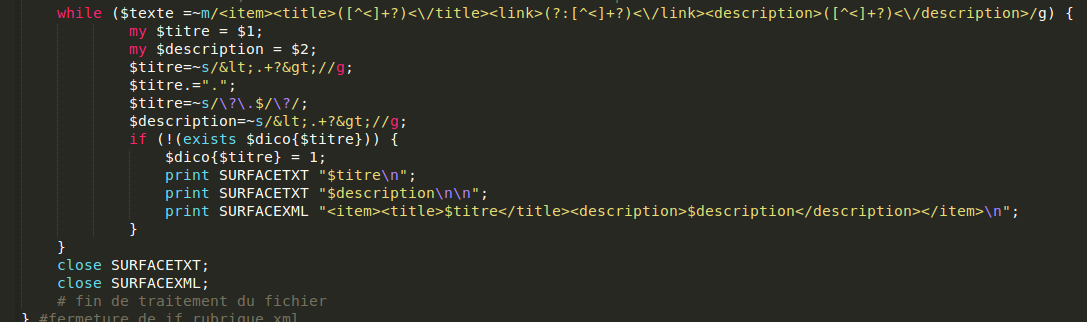
Méthode 1 : expressions régulières
Perl permet de récupérer la chaîne reconnue par une expression régulière en utilisant des variables temporaires ($1, $2,... en fonction de la position de la parenthèse capturante du motif), c'est ce qu'on utilise pour récupérer les titres et descriptions.
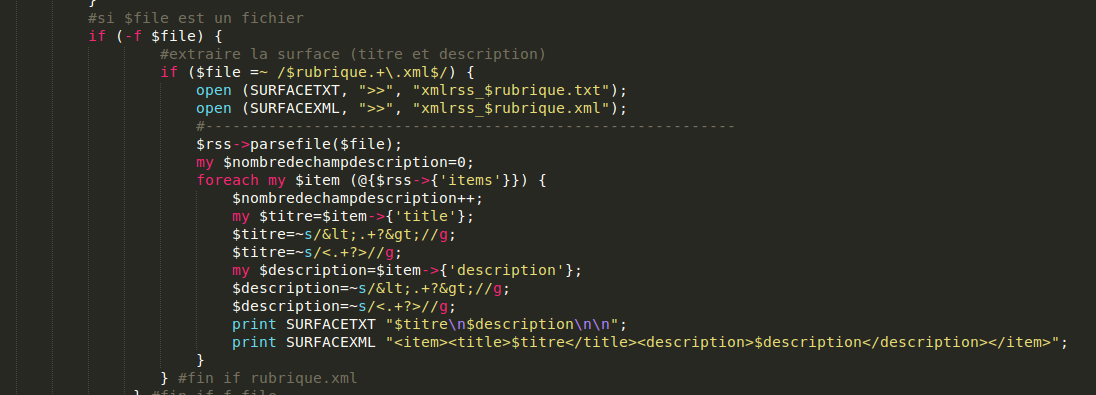
Méthode 2 : bibliothèque XML::RSS
Il existe déjà des modules Perl pour traiter les fils RSS, on va en utiliser un : XML::RSS.
On doit d'abord installer le module, cela ne présente aucune difficulté sous ubuntu (ligne de commande -> sudo cpan XML::RSS).
Au début du script, on précise qu'on va faire appel à un module extérieur avec la ligne use XML::RSS. Puis on déclare un nouvel objet RSS qui représente le fil RSS à traiter.

Le principe est simple :
- On utilise parsefile pour parser (reconnaître la structure)le fil RSS qui nous intéresse. On va ainsi obtenir une table de hachage avec les noms de balises comme clés et leur contenu textuel comme valeur.
- On parcourt cette table en la transformant en tableau pour récupérer les valeurs des clés title et description qu'on assigne aux variables $titre et $description.
- On s'assure qu'il n'y ait pas de contenu indésirable dans le texte récupéré à l'aide d'expressions régulières.
Extraction de la profondeur
Voici un extrait du fichier txt dont on veut extraire la profondeur :
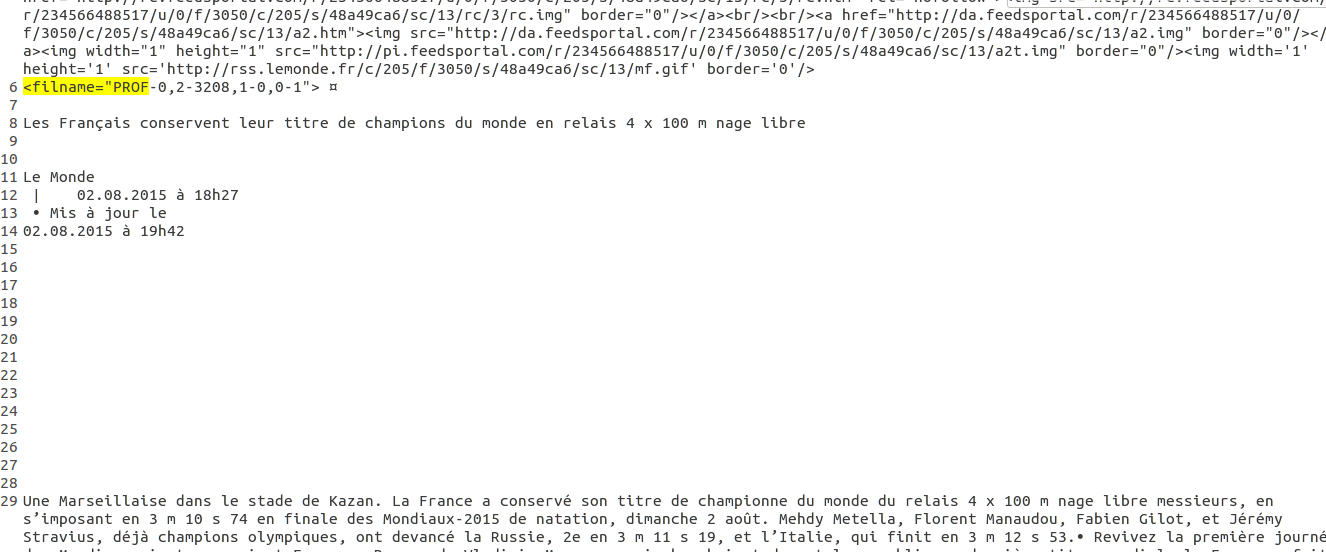
Il n'y a pas de balise fermante dans le fichier mais nous pouvons tout de même utiliser une stratégie d'extraction similaire à celle utilisée pour la surface. Ici aussi on ramène tout le texte sur une même ligne puis on récupère le motif recherché (qui correspond à un article) dans une variable temporaire.
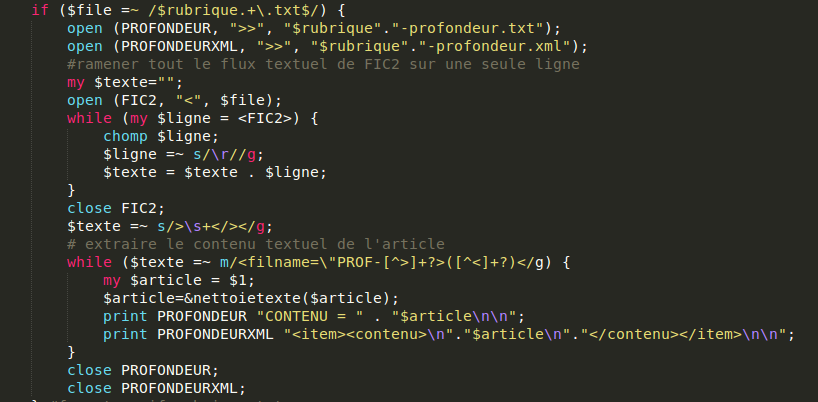
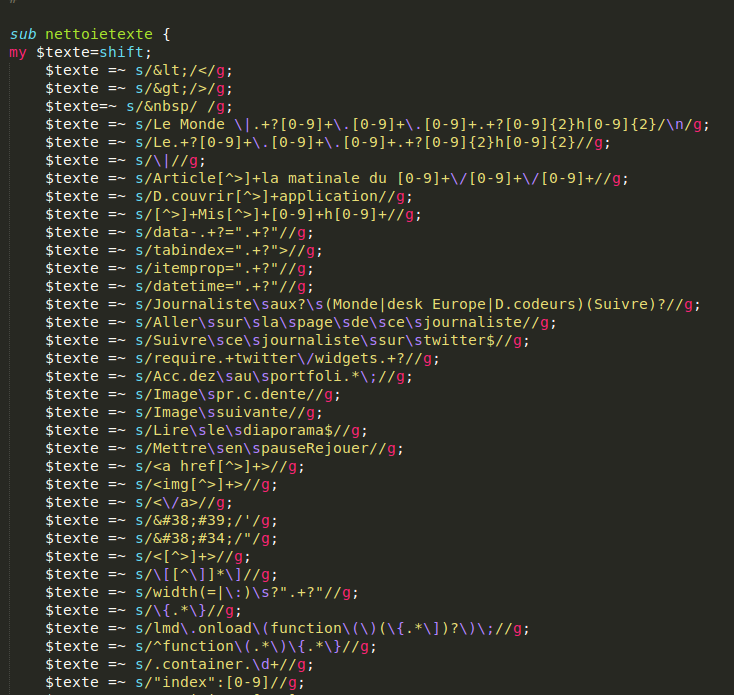
Par contre, le contenu récupéré est parsemé de caractères et d'expressions indésirables. On crée donc une procédure qui va les supprimer à l'aide d'expressions régulières et va retourner le texte nettoyé. En voici un extrait :
Scripts
Télécharger le script qui utilise la méthode 1.
Télécharger le script qui utilise la méthode 2.
Fichiers obtenus pour la profondeur :
rubrique Culture (txt)
rubrique Culture(xml)
rubrique International (txt)
rubrique International (xml)
Fichiers obtenus pour la surface (pour les fichiers de sortie xml, voir la bao2) :
rubrique Culture (xml)
rubrique International (xml)
rubrique Culture (txt)
rubrique International (txt)